
Understanding the Complexities of Cloud Computing Architecture

Cloud computing offers on-demand storage power and computing resources to several businesses. It contains several data centers managed and handled by the cloud computing company, which are utilized by multiple users.
Whenever an organization decides to utilize cloud computing services, they are always faced by the crucial decision of choosing the right architecture. Although this computing architecture depends upon the technical requirements and business design, it is hard to plan this transition effectively. The change puts forth a chance to gain control over professional choices, design, economics, and risk factors. But, it also increases the burden on the business as high-level design expertise is required.
In this article, we have summarized the cloud computing architectures
What Is a Typical Cloud Computing Architecture Made Up Of?
Broadly, the cloud computing architecture can be divided into two parts, front-end and back-end, both connected to each other via a network, typically the internet. The front-end, as per convention, is the client side or the user side. Back-end, on the other hand, is the other end of the system which makes everything in the front-end operational.
Front-end
- Consists of the final user’s computing device or the computer network.
- Consists of the application required for the cloud-based service to run on these devices, with a meaningful interface to make user operation possible and simple.
- These applications can be web browsers such as Firefox or Safari, or email software (which can be web-browser enabled).
- It may include unique applications besides the above, such as Salesforce.
Back-end
- Consists of a large number of computers and data storage systems.
- Consists of all the programs that run or help run the application on the front end.
- It may typically look like large spaces having many computing systems running simultaneously.
- Take a look at the following image. The client computer on the left (outside the blue rectangle) with the user interface comprises of the front-end and everything inside the blue rectangle makes up the back-end.
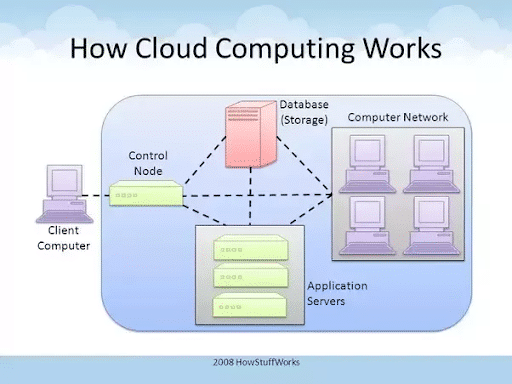
Components of the Cloud Computing Architecture
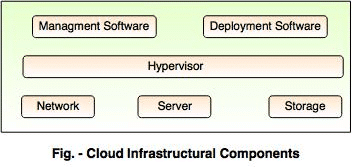
On a more detailed level, the cloud computing infrastructure consists of the following components:
-
Hypervisor
The computing devices on the back-end can often have ‘Virtual Machines’, which is a file that operates as a separate computer. This allows increased efficiencies by virtually running more machines on a single machine. A ‘Virtual Machine Manager’ is required to run such VMs and the Hypervisor is nothing but a VMM. A hypervisor is virtualization software that divides and allocates resources on available pieces of hardware.
-
Management Software
Cloud management software, as the name suggests, does the job of managing and monitoring the operations of a cloud. These are tools that ensure the optimum functioning of all resources and that interaction between users and servers is proper. Usually, Cloud Management tools are deployed as Virtual Machines on existing machines, with a database and a server. As of today, a variety of cloud management software is available in the market.
-
Deployment Software
The deployment of cloud services is carried out using deployment software. It consists of a number of installations and configurations that allow users to access and use cloud computing services. There are three different models which can be deployed:
- SaaS: This stands for Software as a service and uses the internet to provide the application to the user. It usually does not require separate software to be installed and can run over web browsers. E.g. Dropbox.
- PaaS: It stands for Platform as a Service. Unlike readymade applications as in SaaS, it provides a framework for developers to build upon and create customized applications. E.g. Microsoft Azure
- IaaS: This stands for Infrastructure as a Service. It outsources virtualized computer infrastructure directly to the client. E.g. Amazon Web Services.
-
Network
The network is what connects the front and the back end and allows the user to access the cloud services. Typically, it is the internet.
-
Cloud Server
It is a virtual server delivered over the internet which is built and hosted on the cloud computing platform. It can be accessed remotely and has all the characteristics of an on-premises server.
-
Storage
Storage forms an important part of the cloud as all the user-generated data can be stored on the cloud and accessed from any location. It reduces resources spent on the on-premises physical storage and also brings flexibility to the storage requirements. The storage is necessarily a back-end part.
Baseline Cloud Computing Architecture
Single Server
As the name indicates, a single server means only one server, whether physical or virtual, containing one web server, database, and application. The simplest example is LAMP Stack, which is short for Linux, Apache, MySQL, and PHP. This structure is not widely utilized due to associated security risks.
Single-Site
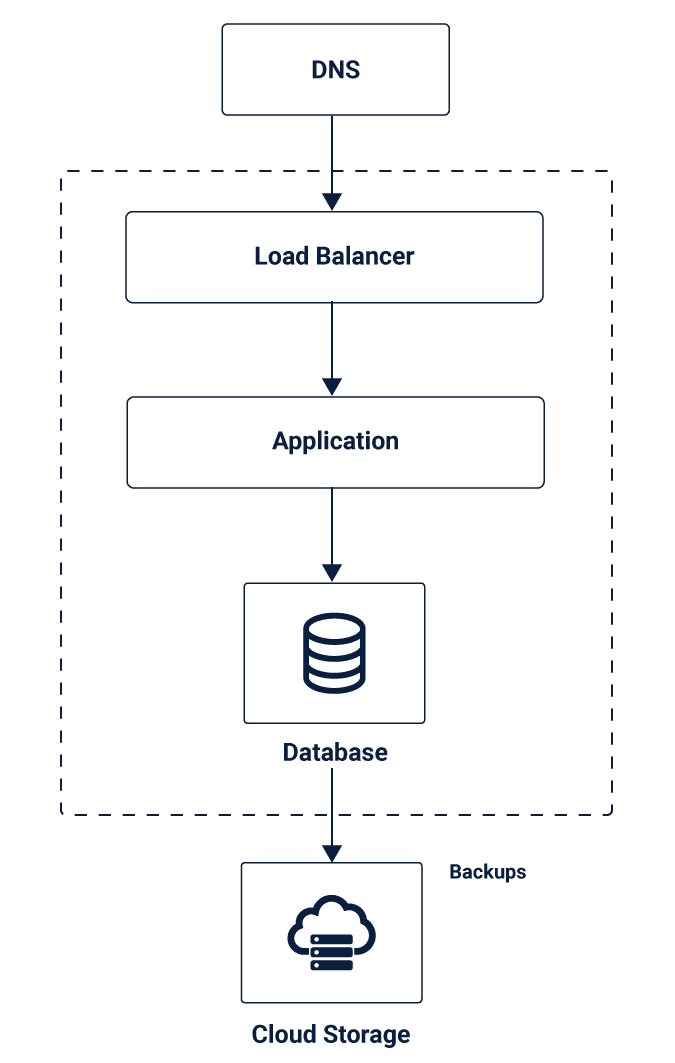
A single site is similar to a single server. But, the only difference is that it creates separate instances for all the layers. This leads to a three-tier architecture with every resource at one location. This type of architecture includes further two types:
- Redundant
- Non-redundant
The redundant three-tier plan adds one more set with the same components and aspects for repetitiveness. It is necessary for the recovery of information in case of system failure. These basic types need a thorough evaluation of horizontal scaling and vertical scaling.
The non-redundant three-tier plan has high risk, but it saves cost. Even a single failure point can restrict the traffic from flowing in and out of the system. These architectures are common for testing environments. However, it is not suggested to use this storage structure for the production environment due to high risks.
In redundant architectures, the single failure points are removed as redundant sets are present. When only one component is present in separate layers, there is only one in and out path. Hence, when one fails, everything fails – giving rise to a single failure point.
The horizontal scaling is used to remove the single failure point. But then, it becomes hard to determine the flow of traffic between redundant horizontal components. Hence, load balancers are often used to balance the traffic between various parts.
Further, while implementing your solution, the difference in resiliency and redundancy should be clear. These are not interchangeable terms. While dismissal is a replication of components, resiliency is finding a solution to an issue. Redundancy is implemented before the problem and resiliency are applied after.
OSI Model
The cloud computing solutions related to Open Systems Interconnection or OSI model contains seven-layers for storage plan. The design part of the solution starts at the physical layer of the OSI stack. Check the segments below:
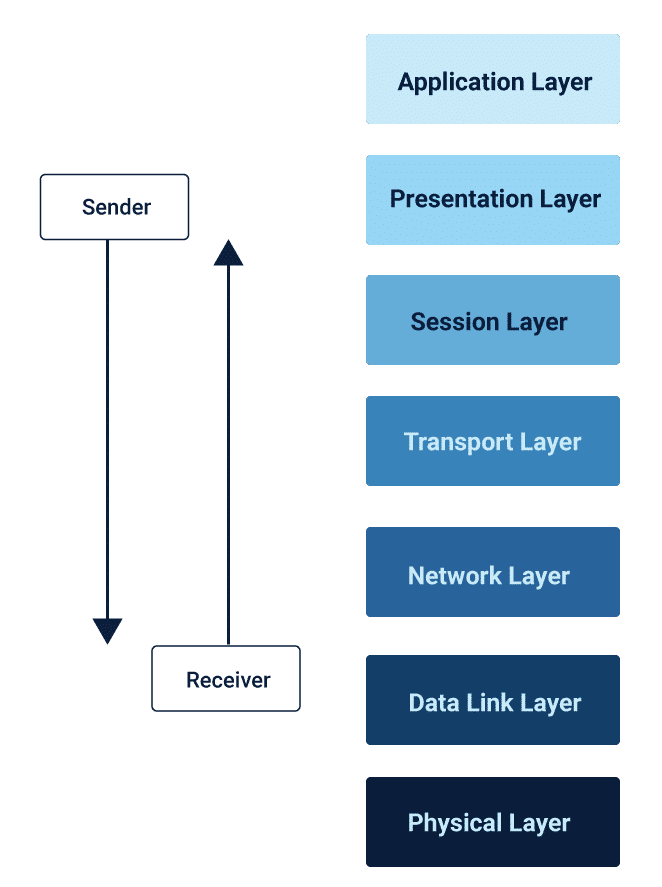
Talking about single-site, single-server, or single-site redundant architecture, every design starts from the bottom and adds up to follow a bottom-up approach. Load balancers are included for a healthy flow of traffic amongst various redundant layers. A redundant architecture here can safeguard the server from downtime and unavailability.
For resiliency, RAID configurations are used for database, back up processes, restore processes, and database rebuild is separately defined for failure scenario.
One of the significant benefits of using OSI stack is the ability to autoscale as per the consumption. As the business requirements change over time, the model or structure automatically scales horizontally for sufficing the demands.
The feature of autoscaling is utilized in baseline planning structures discussed above. The server can dynamically scale and corresponding load balancers are either pre-configured or dynamically configured according to the scaling requirements.
Complex Architecture
Multi-Data Center
The redundant single server architecture can deal with most of the common issues. But, what if the whole site is unavailable? This can happen due to DNS misconfiguration, which will make your single site unreachable. The solution lies in geographic redundancy. Multi-datacenter architecture means having data centres at multiple locations.
However, although this implementation reduces the system risks of failure, it increases various other hassles. Here are a few challenges of multi-site planning:
- What will be the information flow of the traffic between two sites?
- How will you handle the failure of the primary site at the secondary site?
- What modifications will be made to resiliency plan and how?
- How will you synchronize data between two sites before and after the failure?
The load balancing or flow of traffic in this scenario is dependent on the DNS information manipulations as DNS information can consume hours to update information at different sites.
For data redundancy and resiliency, the best model is active-active database enabled with bi-directional replication. Of course, this setup increases the complexity, but it improves the redundancy and resiliency across both servers.
Note: Select the caching carefully as it can impact the database server load, size, load balancing design, storage type, storage replication, and storage speed.
Hybrid Cloud
A hybrid cloud maintains redundancy with the help of public and private space. However, this approach requires the same server on several private and public storage that is being utilized.
Scalable Multi-Cloud
A scalable multi-cloud architecture allows the business to host an app on the private space but scale it to the public space whenever additional resources are required.
Failover Multi-Cloud
Many businesses acquire two cloud computing services. Same server and scripts are replicated and launched on the data centre partition of both the service providers. Communication between the storage space of both the providers is managed with VPN enfolded in public IP address.
Dedicated Hosting
Instead of external and internal data centres, many businesses prefer using private and public storage resources. But, VPN is necessary to create an encrypted tunnel for dedicated and cloud servers.
Hybrid Cloud Architecture
As every user has varying requirements, and they exhibit different load on the server, hybrid UI serves as the solution for varying user workloads. The UI component is on the flexible environment for meeting the demands, and other parts are on the static context.
Since the flexible environment has a different workload, processing components are also designed to handle varying workloads of the flexible environment. Loose coupling is maintained by asynchronous transfer of information across hosting environments. The data requirements of the flexible environment are also changing as the data demands can increase or decrease randomly.
Data backup is a crucial task in the hybrid cloud environment as many businesses need to store information for more extended periods because of audits. Hence, periodically, data is extracted and replicated to the relevant storage component.
The backend of the hybrid storage keeps some components in the flexible environment. This is because components with unpredictable, periodic, and continuous workloads can’t reside in a static environment.
Summary
For any business, a successful cloud computing solution is decided by its technical, economic, and strategic requirements. Every cloud Computing model should be assessed for its risk factors and ability of the business to quickly mitigate these risk profiles. As you will design the architecture, various updates and changes will surface through a feedback loop. Regularly implementing these updates will automatically lead you to a plan right for your business.