
The Most Powerful & Practical Write-up on Cloud Cost Optimization

Cloud Cost Optimization – Why the Focus?
Cloud computing has changed how we engineer and deliver applications. Traditionally, computing was confined to a large room called the data center and was governed centrally by an operations team. These traditional data centers had many drawbacks including greater downtime, expensive infrastructure, under-utilization of resources and dependency on a single team thereby resulting in poor disaster management techniques. With the advent of cloud computing services, most of these problems were addressed, as infrastructure came closer to the developers.
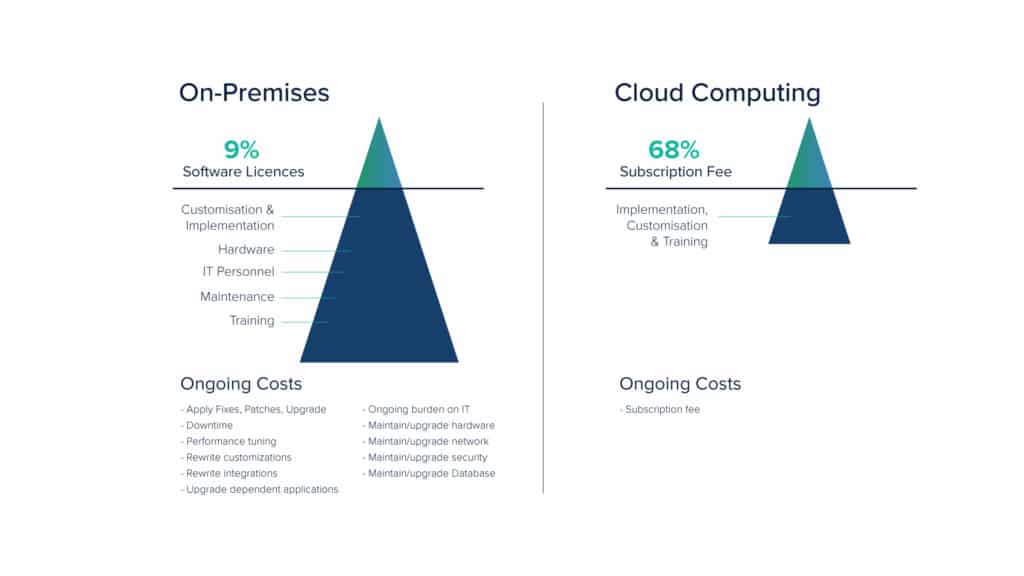
Nevertheless, cloud computing has its own share of challenges like scalability, security, and optimization. The cloud infrastructure today is mostly controlled by developers. However, it is not practical and feasible for them to govern the entire infrastructure. Hence, our focus inadvertently shifts to cloud cost management & optimization.
Optimization Is At The Heart Of Cloud Computing
Traditional data centers were controlled by a central data team that knew what was going on inside each instance in those data centers. The developers relied on these centralized governance teams for the availability of resources. Also, there was a huge possibility of instances within a data center being underutilized.
Cloud computing, on the other hand, is designed in a way that no instances or machines sit ideal with minimal to no workloads running on them. The inherent idea behind cloud computing has always been optimization- resource optimization, cost optimization and performance optimization. This article, therefore, talks more about how to optimize the cost of cloud implementation and operations without compromising its performance and security.
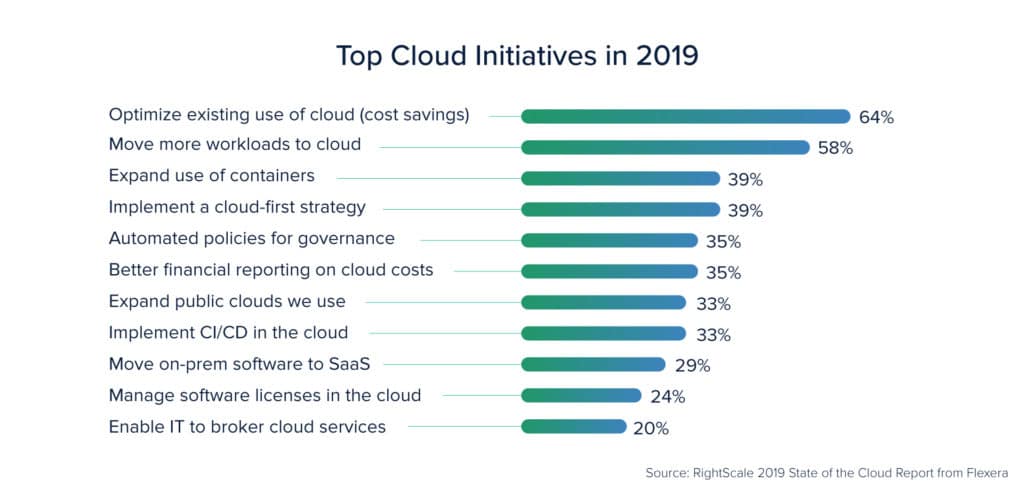
Cloud computing promises greater cost reduction through automation and orchestration. However, there are a lot of challenges that a team or an organization faces in managing these costs. One of the typical scenarios is the result of the growing DevOps movement resulting in several cross-functional DevOps teams within an organization. Each team maintains its cloud account, runs deployments, and manages resources and workloads.
These teams are largely focused on delivering features like speed and tend to overlook the optimization aspect. Because of several accounts working in silos, the possibility of viewing the cloud infrastructure in entirety is tossed away. None of these teams look at it from a single standpoint as to whether the best practices for cloud optimization are implemented or not. As these teams keep on growing organically, the cost overheads also keep on increasing. When the billing cycle ends, everyone is taken aback by the large and unexpected numbers on the bill. At this point, the teams contemplate what went wrong.
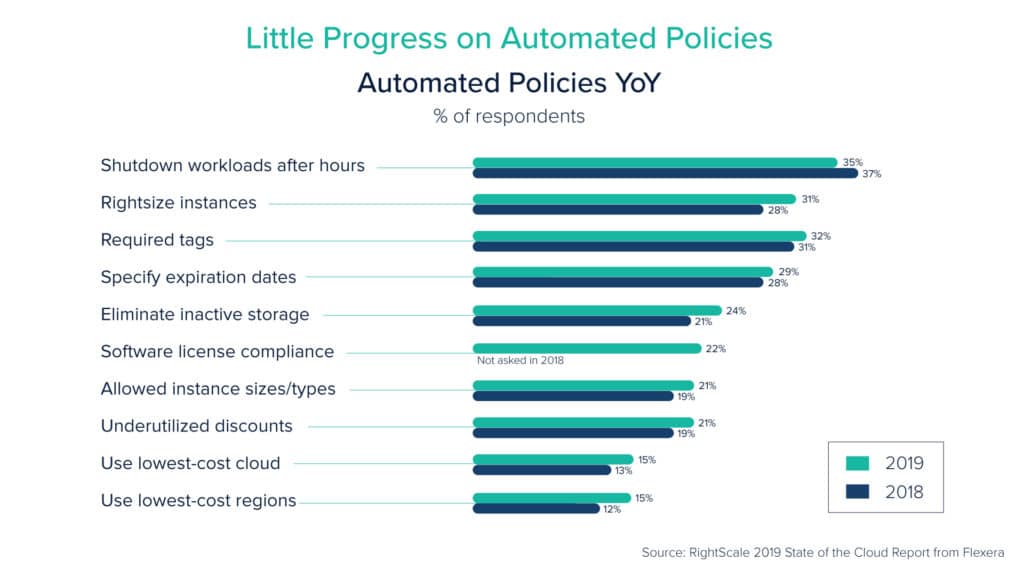 Most often, the problem is that the teams don’t follow best practices about cloud computing with their organizational and team goals in sync. The ideal way about this would be to let the DevOps teams take individual actions and decisions alongside keeping best practices in mind. Avoiding over-provisioning of resources, selecting the lowest-cost resources that cater to your technical needs, and optimizing data transfer costs, are very important practices in this regard. Based on these the teams can build their systems keeping in mind the overall organization costs without sacrificing performance and security.
Most often, the problem is that the teams don’t follow best practices about cloud computing with their organizational and team goals in sync. The ideal way about this would be to let the DevOps teams take individual actions and decisions alongside keeping best practices in mind. Avoiding over-provisioning of resources, selecting the lowest-cost resources that cater to your technical needs, and optimizing data transfer costs, are very important practices in this regard. Based on these the teams can build their systems keeping in mind the overall organization costs without sacrificing performance and security.
Managing Network Optimization for Cloud
In the case of on-premise systems, the enterprise takes care of the network bandwidth, makes sure the applications are using the bandwidth correctly, gets the ISP connections, and manages all this within a single place governed by a single authority.
However, when it comes to cloud, companies are so engrossed in migrating to cloud services that they often ignore a critical aspect of their enterprise, i.e. Network Optimization. In the absence of a physical infrastructure to manage, network cost is often overlooked.
While shifting to the cloud, enterprises think in terms of availability, scalability, and reliability. Initially, opting for high availability zones looks good, but as the system scales up, there is a huge surge in the cloud costs. This surge is the cost of outbound data transfer. Consider an application that is to be accessed majorly in Asia-Pacific but owing to its high availability, you host it to the Virginia region in AWS. Everything looks good in the beginning. The network cost is so little that you don’t even notice. The problem begins when your application starts scaling up. You realize that there never was a freebie involved and that you were always charged for the network cost by your cloud provider. You just didn’t see it until it reached a significant amount.
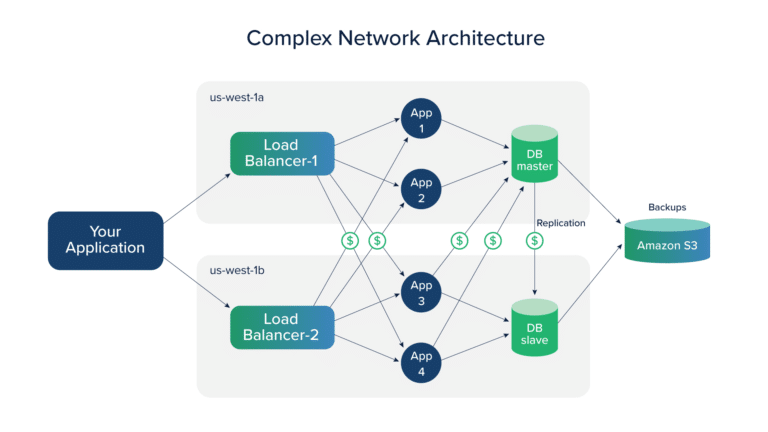
There is network cost involved for every piece of communication- whether it is between the regions or within a single region in case of distributed databases with the number of times your application is accessed. As your application scales up these overhead charges are bound to go up too.
Cloud network cost optimization is dependent on the selection of the cloud region and availability zone. The proximity of the cloud region from the availability zone where the application is hosted; business costs related to energy, carbon penalties, real estate taxes, and operating costs including governmental costs like taxes or duties placed on services- all of this adds up to the cloud region cost. Therefore, cloud regions and availability zones for your application factor in as a large part of your cloud expenditure.
The region and availability zone for an application needs to be selected while keeping two things in mind: the kind of application it is i.e. will it be accessed in a particular region or all across the world and whether the application architecture is standalone or distributed.
Once the region and availability zones are decided, the next practical thing would be to consider optimizing the network calls. One way to achieve this, both for inter-zone communication as well as external communication, is through compression techniques. In the case of a distributed application, the first thing to ensure is whether the application truly needs to be distributed.
One must think about all aspects of architecture- whether it is required to be spread across ‘N’ number of availability zones, whether the application be partially distributed in a single availability zone with part of it in multiple high availability zones. Thinking on these terms will help in cutting down some of the inter-zone traffic costs.
When an application uses distributed systems in the cloud, you need to pay attention to the configuration such that it lets you control how much chattiness has to be allowed. It can then be balanced against your high availability and fault tolerance requirement.
Network Optimization Through Better Handling Of Payloads
Handling payload transfers efficiently between two nodes is another important aspect of Network Optimization in the clouds. If the API development does not take care of redundant payload, it results in fatty clients and thin Servers. Fatty clients are those that receive a lot of unnecessary and unprocessed data from the server. A thin server means that the server sends a lot of redundant data to the clients, and lets the client process the required information out of it. This unwanted transfer of data from the server to the client adds to the network cost which is ultimately added to the enterprise’s bill by the cloud provider.
Fatty clients and thin servers generally result when the developers fail to balance the ease of development versus the cost of development. The idea is to let the client decide which piece of information it requires so that the client is not inundated with unnecessary and redundant data. This can be achieved to some extent by a well-implemented REST API design. A better solution though would be exploring systems like GraphQL that helps transfer the exact data that the client is looking for.
Cuelogic recently did a GraphQL implementation for a financial customer that had multiple data sources for each aspect of that domain. During the architectural phase, one of the challenges faced was to build a REST API and then decide which parts of the data needed to be sent to the client. It was, therefore, strategically decided to use GraphQL to optimize the network cost by sending only the pieces of data that the client requests.
Apart from network calls from server to client, there can be a scenario where the client needs to send data to the server. To optimize these network calls, the client browser can use HTTP compression schemes like GZIP and DEFLATE. Most of the web servers account for these compression techniques. The browser sends the header to the web server stating that the client accepts compression along with the preferred compression algorithm. The server then makes sure that the data is sent back to the client using the agreed-upon compression algorithm. Using such compression techniques one can save the bandwidth between 30 to 70 percent.
Another measure would be to introduce edge processing on those machines. When dealing with sparse data, you can successfully apply compression, or stripping techniques to cut down the network cost. Additionally, one should start thinking about different kinds of protocols.
For example, WebRTC, which is a free, open-source project that provides real-time communication for web browsers and mobile applications, can be used for sending the data. If your domain and use case permit, you may also consider using UDP over TCP.
While developing a scalable web application, it is quite a norm for developers to use the polling technique instead of a web socket. Initially, this appears to be a good implementation however as the application grows, it affects the network traffic immensely. To implement real-time features in a web application, developers are likely to create an AJAX or XML/HTTP request with the client polling in at regular intervals to the server.
As traffic increases, polling becomes an expensive operation as it results in thousands of avoidable and additional hits to the server. To avoid these needless hits, web sockets can provide a better solution by the server pushing the data to the client rather than the client continuously asking for data from the server.
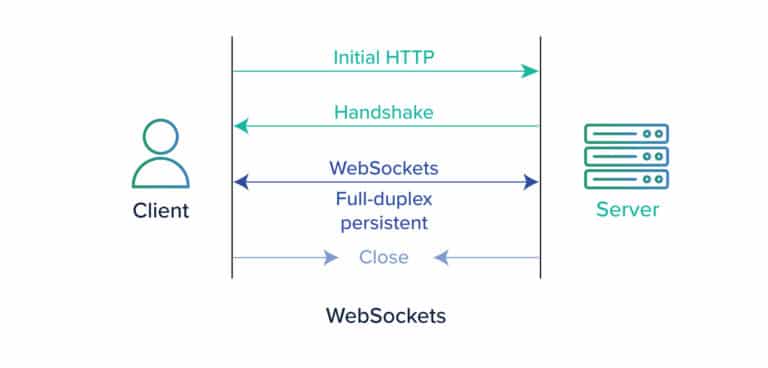
However, as with every technology, web sockets too, have some bottlenecks. While designing an application that uses a web socket server, one might face issues with scaling and load balancing. Fret not; it isn’t something that can’t be handled.
We will look at this through a use case for a customer at Cuelogic. We were building a time tracking system for a customer. One of the challenges was to keep these time-tracking boards updated as a lot of users were simultaneously operating the system. At the POC level, web sockets server seemed to be a great choice because of its real-time behavior. But as the system grew with millions of users accessing it, challenges started to creep in. The system couldn’t be simply scaled because there was a single web socket server handling all the millions of requests. So the web socket server itself had to be scaled. As the web socket server was scaled, there came another challenge of load balancing because the requirement was to keep a persistent connection from the server to the client. To handle this scenario sticky sessions were introduced to manage load balancing.
Another point to consider is that distributed systems like Kafka have a master-slave architecture with several brokers. These distributed systems orchestrate between the brokers. In Kafka, each of the brokers which is distributed within multiple availability zones heartbeat for high availability and fault tolerance.
A common mistake that developers make is to leave the configuration as it is. This works fine in the local environment, but as the system scales-up, a lot of chattiness grows from slave to the master. This added network communication call can be avoided altogether if the developers manage configurations like heartbeat intervals beforehand.
CDN (Content Distribution Network) & SPA (Single Page Application) for Network Optimization
Think about an application hosted in a data center in the US, but it caters to traffic from users all across the world. For high availability, one way is to set up your application in all the regions in the cloud, but obviously, that is going to be an expensive solution owing to the traffic between the regions. As we have seen earlier, there are cost differences between the regions too.
For instance, regions that are less used are costly while the regions that are heavily utilized have fewer charges. So, a more feasible solution to this problem is a CDN or a Content Distribution Network.
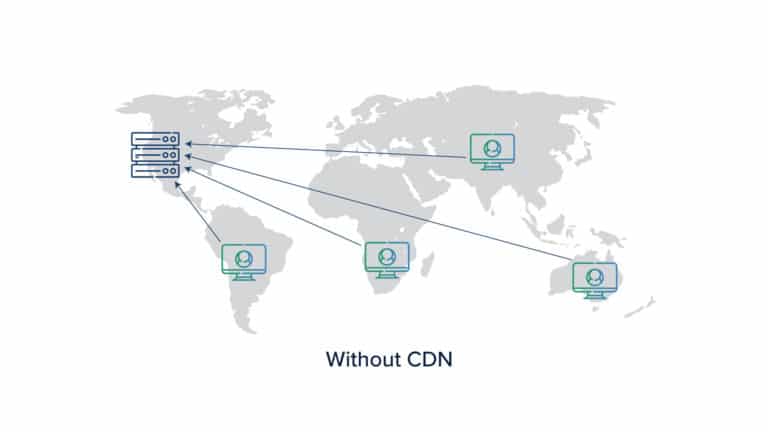
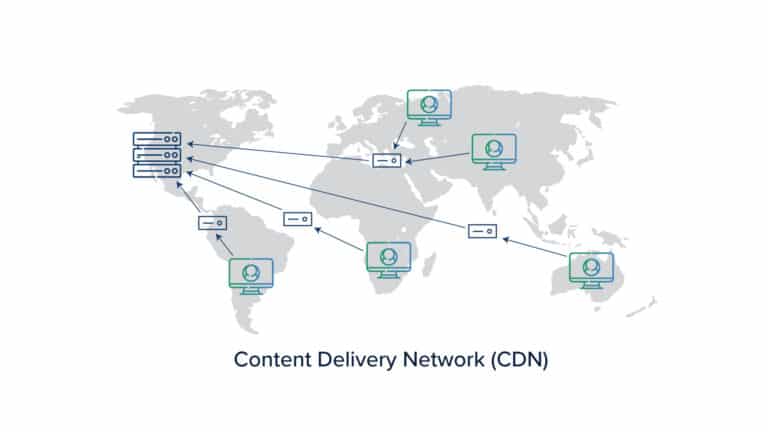
CDN is a system of distributed servers that sends web content to the users based on their geographical location. A CDN network consists of several edge servers spread across globally. The web traffic is controlled and cached at these edge servers.
When the client requests data for the first time the edge server will be a miss and the data directly comes from the origin server. However, for subsequent hits, the edge servers will start caching the data. So whenever a request comes from a client, the nearest edge server responds, thereby, significantly reducing the latency and improving the user experience. There are a lot of CDN’s available for use, like the Akamai CDN server or CloudFront in AWS.
CDA’s are a hit, particularly with Single Page Applications. For a SPA, the assets are hosted on a CDN server. When the browser requests data, it comes from the closest edge server where it is already cached, thereby saving the network cost by not requesting an origin server that is located further away, for data again and again.
An example of using CDN for SPA is a document management system. Document management systems consist of many static assets. As the system scales, the number of documents and the request to fetch these documents grows manifold. Here, caching plays an important role in cutting down network costs.
On the other hand, this may affect the security of data. So CDNs are perfect for a public domain and globally spread Document Management System that does not require authentication or authorization. For other cases, each CDN provider handles authentication and authorization in different ways. In the case of a high-security application, you should first confirm how your CDN is handling sensitive data.
Earlier, there was server-side rendering that used to send a lot of bloat from the server to the client. For example, it would send the entire HTML page structure to the client which would then be rendered on the browser. Sending the entire HTML structure again and again used to affect the network cost and speed. With the advent of SPA and REST APIs, one can have SPA assets like react.js or angular.js applications on the edge which are cached and sent from here.
This will save network costs as you don’t need a server or virtual machine but can simply send the REST API call. For a few customers at Cuelogic this was combined with GraphQL that further saved on the REST API calls by sending only required data packets. So for an ideal application, the first layer would be saving on HTML costs, the second layer would be well implemented REST APIs, and on top of REST API, there would be GraphQL sending the necessary pieces of data only. This will make sure you are as optimized as possible in terms of the network in the cloud.
Storage Optimization in the Clouds
Storage, like Network, is another prominent but less understood component of the infrastructure. When developers set up the cloud systems, they often ignore the storage aspect and go ahead with the default options attached to each Virtual Machine. Instead, they should factor the kind of workload expected and therefore the type of disk required by the application at that particular time.
For example, for high throughput, you might be tempted to use the latest SSD system that the cloud provides as a default option. However, not every application will require such a disk. It is, therefore, important to understand what kind of disk instance would be most feasible for your application needs. Instead of blindly using the best available disk with your cloud provider across all your virtual systems, the right approach would be to understand the components of the system and the kind of throughput performance they require from a disk read/write perspective. This will save a lot on your bills if factored at the beginning itself.
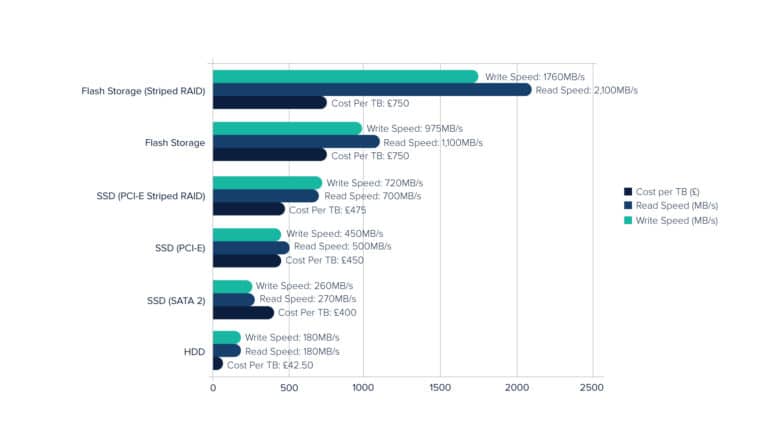
Apart from the disk cost, another factor that is overlooked is the cost of ‘data’. Data is crucial to any system. Even if there is a massive failure in the production workload, one can still bounce back if the data is intact. To be disaster ready, almost every system takes a snapshot and often for better disaster recovery, stores the snapshot at each cloud region.
However, once the snapshot is taken, it keeps lying there and subsequent snapshots keep piling up months after months. In the beginning, this may not be noticeable but over time the snapshots eat up a lot of storage space on your virtual machine thereby increasing your storage cost. To avoid this, you need to devise measures to manage the lifecycle of these snapshots. Almost all cloud providers have options for setting lifecycle policies and it is a good idea to check these policies before piling up the snapshots.
At Cuelogic there was a heavy data-intensive project (100 + TB of data) with critical data. Due to the criticality of data, snapshots were to be taken frequently into other regions as well. With time, the snapshots kept growing in numbers also increasing the storage bill amount. At first, the team framed certain policies to clean up these snapshots manually. In the long run, as manually doing so wasn’t a good option, the team had to think about techniques like the automated Lambda function in AWS that allowed for these snapshots to be created and deleted periodically.
There are other solutions to this problem too. One is to maintain the snapshot lifecycle in the S3 buckets. The other is to use incremental snapshots that save a lot of nuisance of maintaining these snapshots. In the case of incremental snapshots, every time a snapshot is taken, only the delta is saved. An incremental snapshot or the delta is created over the previous snapshot and gives a seamless experience to fetching of data or attaching the snapshot back to the previous instance or a new instance. Thus, by saving only the delta, there won’t be a lot of snapshots left stranded to be managed or deleted later on.
A point worth considering is to understand the different types of disk instances available for server configuration and to make sure that you use only the right instance. In AWS, the default option is the SSD disk- but there are other types of disk instances too which are less utilized yet are worth exploring, like a hard disk.
People usually assume that they need to use an SSD every time and end up paying an additional price. Not every type of workload requires SSD storage though. Disk compression too can play a role here depending upon the file system that you are using. For instance, certain file systems are efficient in storage and retrieval of data, and faster write and read operation.
Based on a particular use-case one can select which file system to use. One example of this is the usage of the X4 file system. Generally, people use the X4 file system which is not optimized for every operation, so it would be a good start to shift to XFS or ZFS file systems for a database-specific operation to have better performance.
Another point to ponder is that today most of the applications deployed in the cloud are maintained by the developers who may not have an understanding of the infrastructure as good as the system administrators did. Things like how to efficiently set up RAID and making sure the applications are performing well may not be the developers’ forte.
For example, developers will generally attach an Amazon Elastic Block Store and they will be fine with it. A system administrator, on the other hand, will think on logical lines like you can start with a lower disk capacity and have a logical volume. Then as the need arises you keep adding disks without disrupting anything. While this logical thinking comes naturally to system administrators, developers are not used to it.
Using Object Storage For Optimization
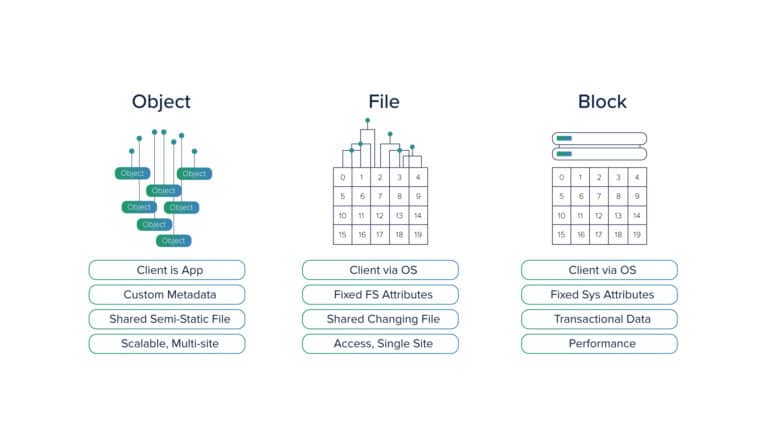
There is a common misconception among developers that Object Storage is good for storing assets like static images etc. Although this is one of the use-cases for object storage, its utility is not limited to only this. Object storage is slower compared to disk performance. This is another reason why people never think of using object storage for saving actual data.
One needs to know the difference between object storage and typical block storage to understand its advantages over a disk. For one, object storage can have more metadata that can help in the efficient retrieval of data. Keeping speed aside, if you think on the lines of efficient storage and retrieval through key-value pairs attached to the metadata, object storage will certainly appear beneficial. And to add to that, object storage is economic as against disk storage.
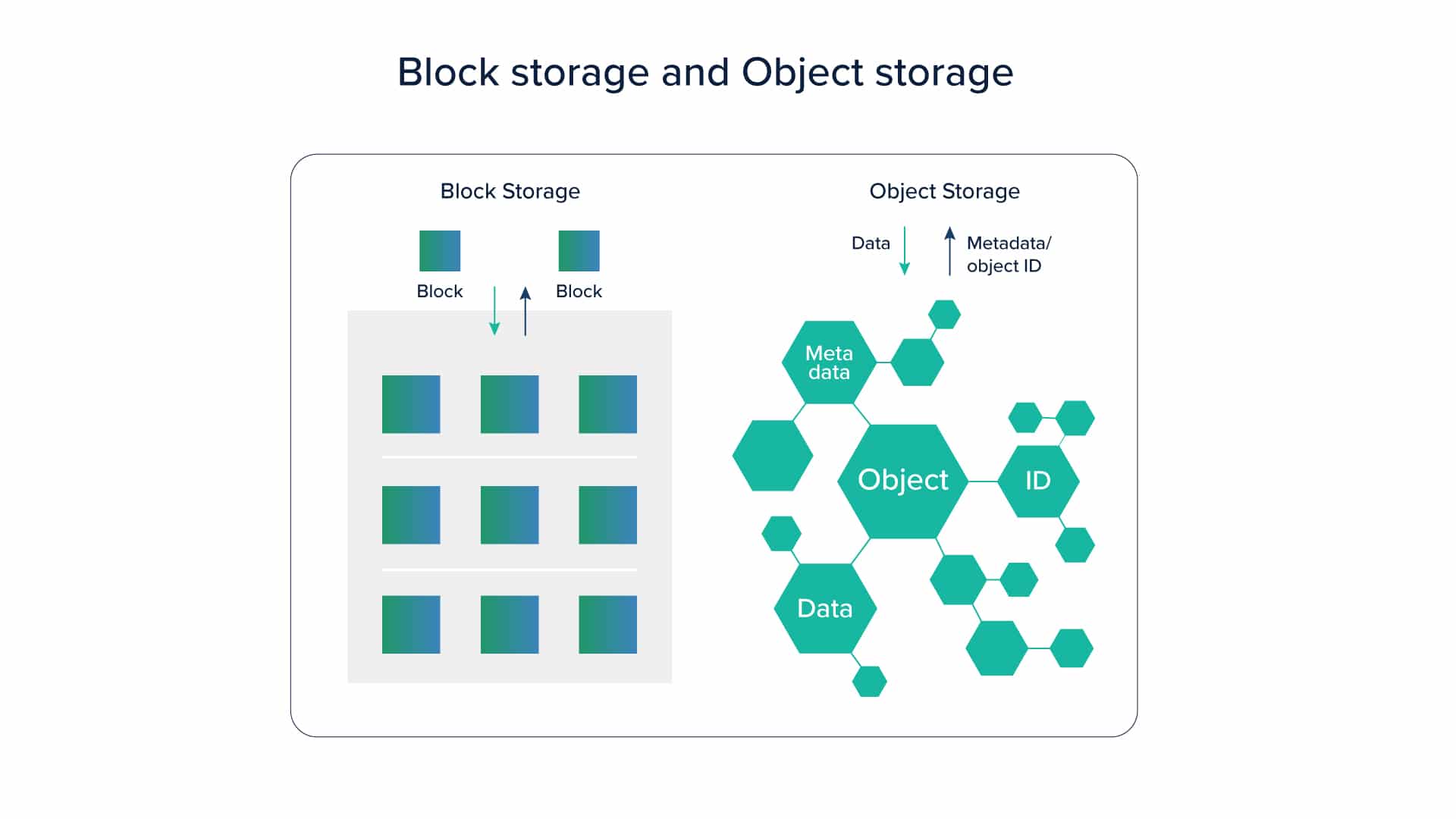
Large scale systems like Big-Data or even traditional data warehouses today deal with terabytes and petabytes of data. This ever-growing data keeps on adding to the storage cost. If you keep using SSD or hard-disk, you will end up paying huge storage costs. With technological advancements, there are now ways to store huge amounts of data on object storage and a small amount of data on actual SSD or hard disk drive, which can then be used efficiently to retrieve data.
Recently, at Cuelogic, there was a customer with a similar use-case. The customer initially used a large elastic search cluster to search through the logs generated. In the beginning, this worked out great. But with time, as the daily log count increased to billions of logs per day, the real problem started. Over a period of 20 days or so the disk used to max out and it became a challenge to manage and decide how much disk capacity is to be left in the cluster. A turnaround was to take a snapshot and then move it in object storage but the retrieval of data afterward for audit or other purposes was still a greater challenge. Other than paying a huge cost for the disk, and the network cost, it was also an operational haphazard to retrieve this data back as the disk would never have enough space. For instance, if the user wanted to retrieve logs for a period of 6 months to a year, there was no space on the disk to retrieve back such a large amount of data. It became a challenge to ensure that the disk didn’t max out, to periodically take a snapshot, transfer it to object storage and then pull the data selectively in fragments as the disk couldn’t accommodate all the data at once. To solve this problem for clients, we used Object Storage through different technologies like Alluxio, a memory-speed virtual distributed file system. We created a lambda architecture in the Big Data landscape, where a short period, say 24 hours of data, was stored on disk-based systems and the rest was automatically taken a snapshot of and sent to Object Storage. The best part was that as Object Storage has a metadata structure, it was way easier to search across data with technologies like Alluxio. This re-architecture of the system brought down the operational costs for our customers up to 50 percent.
Almost every cloud provider today offers this functionality. For example, AWS primarily uses Presto in the form of Athena to fetch data from S3, or RedShift spectrum to fetch the data. RedShift used thousands of dollars to store 1TB of data. In RedShift Spectrum, you get an option to send older pieces of data to S3 and then use Spectrum to fetch that data whenever required.
As people are getting aware of these technologies, they are trying to explore how to move parts of their data to object storage without impacting the ease and efficiency of data retrieval. If you use the only disk at the big data level, with the growing data the cost associated will be enormous too.
In this hybrid model, a disk is used only for small and fast data, and the rest is sent to object storage, and the backing up of data or snapshots are automated. Customers can easily search a year’s worth of data in S3 and retrieve it efficiently on the disk as well. The query can be a bit slower, but the caching mechanism in technologies like Alluxio can improve the performance significantly, almost close to disk-based retrieval.
Compression In Object Storage
Object storages are significantly cheaper than disks; however, they aren’t cost-friendly either, especially when we are dealing with large amounts of data. As Big Data systems grow, their data grows exponentially into PetaBytes of data. To handle such vast amounts of data, you require a lot of object space. This cost is probably lesser than disk but cumulatively, object storages too affect your bills to a larger extent.
 For efficient and cost-effective object storage, the initial step would be to select metadata that facilitates data retrieval. In Big Data systems there is a mechanism that greatly reduces network cost, known as predicate pushdown. It involves “pushing down” parts of the query to the data in the storage itself, and then filtering out most of the data. Almost all object storage today supports this mechanism, where you specify the byte range so you can get only the essential piece of data.
For efficient and cost-effective object storage, the initial step would be to select metadata that facilitates data retrieval. In Big Data systems there is a mechanism that greatly reduces network cost, known as predicate pushdown. It involves “pushing down” parts of the query to the data in the storage itself, and then filtering out most of the data. Almost all object storage today supports this mechanism, where you specify the byte range so you can get only the essential piece of data.
Object storage usually deals with large files in size of TB’s for efficient storage, for example, AWS and S3 support 5 TB of data per file. Searching or accessing such large files is an expensive operation, while you may only need a block of data. Hence, it is a good practice to save on network costs by accessing only a required portion of the file rather than the entire 5 TB of file. Big Data systems deal with huge files and there are high chances of individual records being de-normalized i.e. they have a flat structure with tons of columns.
All these columns may not have values in them resulting in sparsely populated data. If a traditional format like CSV is used then the sparse data will result in null values or spaces in the columns, adding to the file’s volume thereby eating up the storage.
There are more efficient row columnar data formats like Apache Parquet or ORC both of which resolve this problem. Cloud providers today offer these formats where only the columns that have data are stored. For example, Google BigQuery uses Apache Parquet file format. Another advantage of these file storage types is that unlike traditional file systems’, searching is easy and cost-friendly as it is done through columns and not rows.
Using Apache Parquet or similar file systems will ensure using a predicate pushdown mechanism is fetching only essential pieces of data. They also aid in compression as millions of records are saved within a single file. Comparing these columnar storage file systems with the JSON file structure will show close to 90% compression. For large files, such formats can offer up to 50% compression as against a CSV format. Additionally, there is efficient retrieval of data through this format that is generally costlier in JSON or flat structures like CSV.
Another thing to understand is that like a disk has different types e.g. instance-level Solid State Disk, network Solid State Disk and hard disk, similarly object storage has classes like standard classes in AWS, infrequent access, and glacier, etc. Each of these classes is associated with different pricing but people often go forward with the default Standard Class in AWS, which turns out to be expensive. It is, therefore, imperative to define the lifecycle of your data pieces and then select these classes.
For instance, moving lesser-used data in infrequent access class or glacier can save a lot on the cost. But while making this choice always keep in mind the retrieval of data as it is a bit complicated in deep storage. Currently, a lot of work is being done in this segment with different cloud providers handling it in different ways.
For example, AWS does not allow direct data retrieval options from deep storage. One has to request the data and then wait for a couple of hours before AWS sends the data to the standard storage like S3 for access. Though AWS incorporates concepts like intelligent tier, which moves the data in a predictive fashion through different tiers to save on cost, yet this does cost you some time and money. Google offers a different strategy, where your deep storage is always online, and you can access data yourself with some network latency.
This is an evolving space in terms of how to manage the lifecycle of data, how you reduce the complexity of lifecycle and simultaneously making it cost-efficient.
Compute Cost Optimization in Cloud Computing
When it comes to optimizing spend in the clouds, people often disregard the network cost, and while they understand storage costs they don’t plan around it well. Irrespective of this, developers always plan efficiently the Computing Cost, probably because it is a prominent component on the bill. For computing optimization, using on-demand instances in the cloud sounds like the most viable option.
On-demand is cost-effective for workloads where you want the instances periodically or free them for an extended period and then want them again. On the contrary, always using on-demand instances can turn out to be expensive. For on-demand, the cloud provider has to spin the instance, ensure the instance is available and blocked till the time you need it, ultimately adding this cost to your bill.
Consider a case where you started with on-demand instances, and with time the workload got stabilized, the system scaled up, and you exactly understood the type of instances required. In such a case the best option would be to pay upfront for these instances, also known as reserved instances, and buy them or lease them for the duration that you require them. As this option is easier on the cloud provider, the cost that the cloud provider saves by reserving certain instances for a particular user for an extended time is reflected on the user’s bill as well.
The upfront cost for these reserved instances may appear higher, but there is at least a 30% cost reduction as compared to on-demand instances.
A question may arise in your mind, that if I reserve instances for a prolonged duration, what will happen in the case the workload increases?
To provide a solution to this problem, cloud providers like AWS have an option of convertible reserved instances. Convertible reserved instances require you to pay extra money as compared to reserved instances, but you can later use this amount to buy additional instances as the need arises. So if a user considers using reserved instances, it is highly recommendable to go for convertible reserved instances to get the flexibility of changing the computing power on the go.

Recently, there was a requirement for a customer at Cuelogic, where the need was to migrate and re-architect an already existing large system into a completely new system. There were instances from the previous architecture with a predefined type that had to be changed as per the new architecture. This could have been cumbersome, but as they already suggested to our customer to use convertible reserved instances, it was a breeze to convert the earlier instances to the new instance type. Had Cuelogic not cared to advise the customer for convertible reserved instances, other than the ease of re-architecture, the customer would have paid 30 to 40 % more price too.
Overall using convertible reserved instances was a cost-effective solution. This might appear expensive as compared to reserved instances or on-demand instances, but if you look at the larger picture throughout the lifecycle of the system, convertible reserved instances are a good investment to make. Currently, innovation is happening around another instance type, known as Spot instances that are available up to 90% discount compared to On-Demand price.
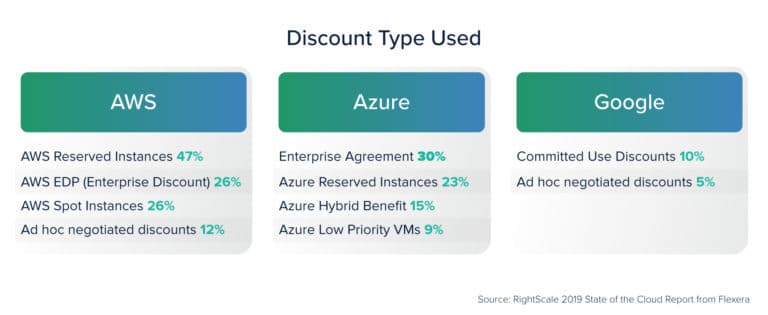
To know what spot instances are, let’s understand that at any given point of time, there are a huge number of people using data centers in regions and availability zones across the world. A lot of these people will be using on-demand instances. So whenever any of these users demand an instance to be shut down, it is practically not possible for the cloud provider to instantaneously do this.
So generally, the cloud provider will schedule them to be shut down at a later time. Meanwhile, the cost of running these instances is on the cloud provider. So they prefer to make these instances available for utilization by a customer. These instances, therefore, are available as spot instances at dirt cheap rates.
From a user’s perspective, though, there are a few concerns related to these instances. For example, there is no guarantee when these instances will be available for use or once available when they will be taken back, along with the pricing fluctuations associated with them.
The need of the hour is to come up with a strategy or an architecture that effectively manages such instances. This is where the Cloud-native movement in DevOps comes to the rescue. One of the prominent players in the market used to automate deployment, scale-up systems, and manage containerized applications is the Kubernetes orchestrator.
There are a few things to consider for an application to be compatible with spot instances.
Firstly, the application should be containerized, i.e. it should be packaged together with the requisite libraries, frameworks, and configuration files to be able to run efficiently in different computing environments.
Secondly, the application should be cloud-native, i.e. it should be designed to a 12-factor principle that consists of best practices to enable building portable, resilient, and scalable applications. Lastly, ensure that the applications can have downtime without affecting the system’s functioning.
The Kubernetes orchestrator can take care of all the three points above along with being tied to spot instances as well as reserved instances. Spot instances and reserved instances share the workload somewhere in the ratio 80:20. The orchestrator decides how and what kind of workload to manage between both these instances. The stateless services that don’t require storing the state like computing services, data transformation services are generally reserved for spot instances. Stateful services like databases and message queues are put in reserved instances.
Several strategies and policies can be used to ensure that stateless services go in spot instances. Whenever a spot instance comes up, the already scheduled stateless services go to that spot. When the spot dies, the stateless service can either go to another available spot instance, or if none available, it goes to a reserved instance.
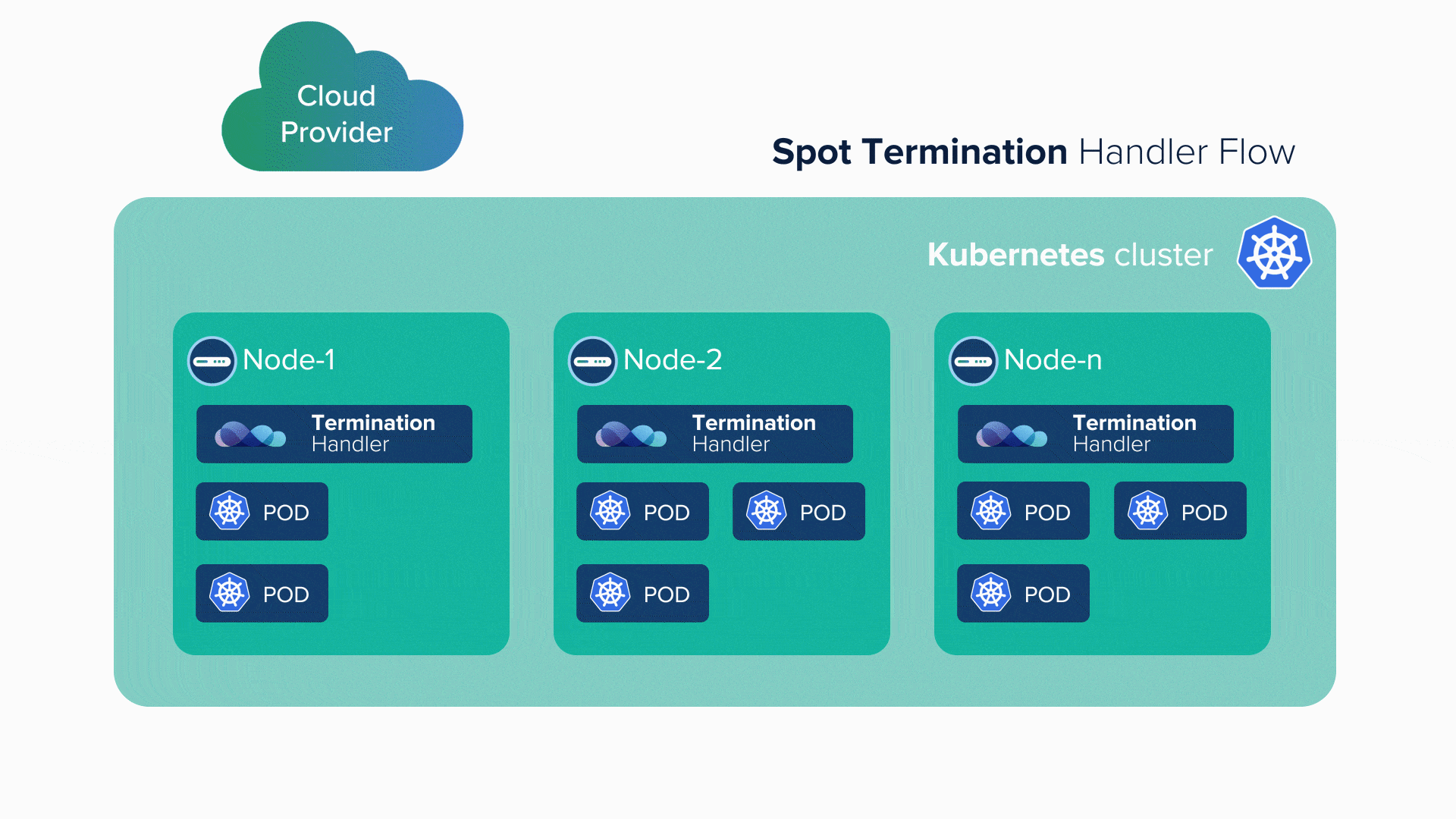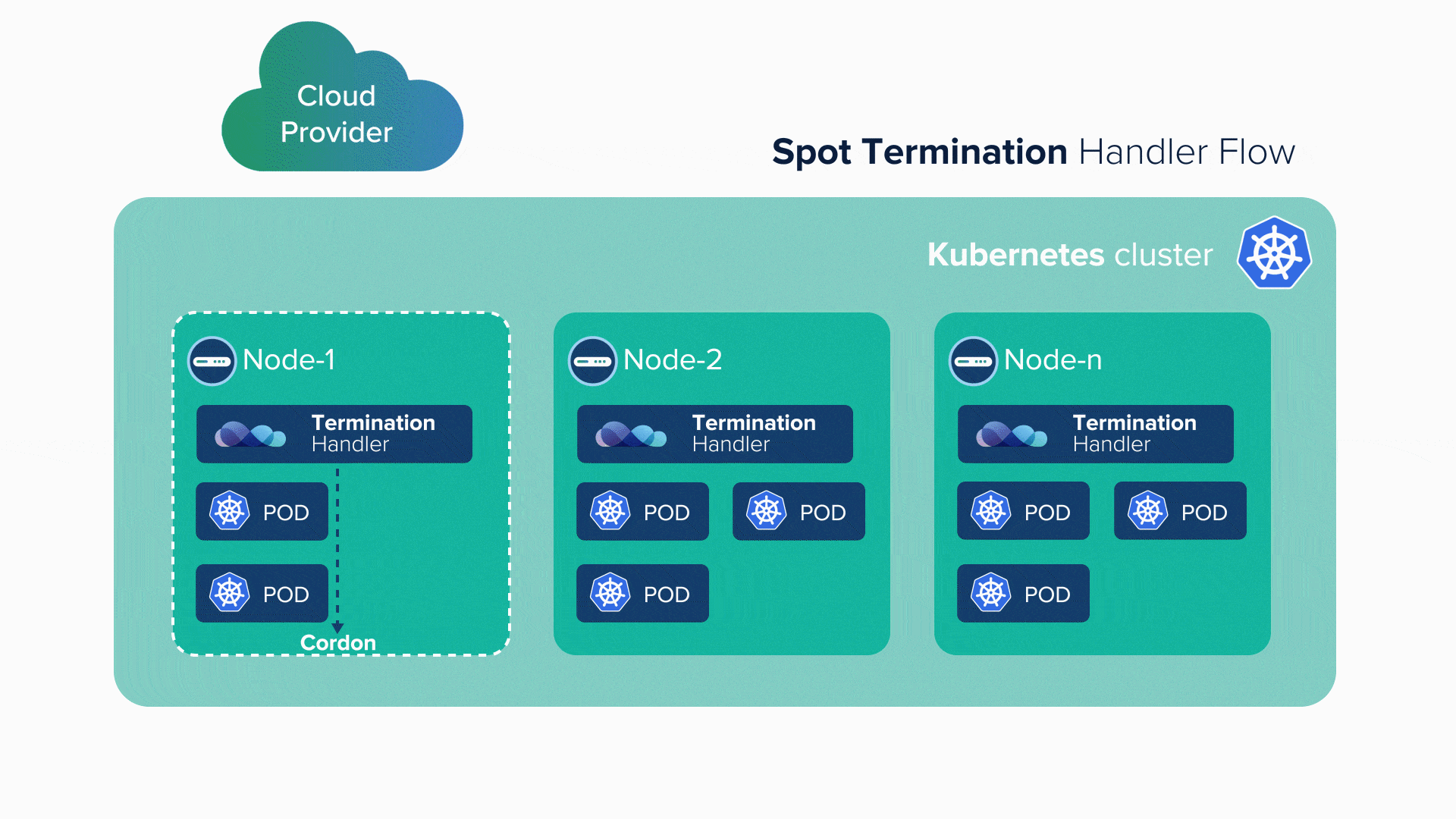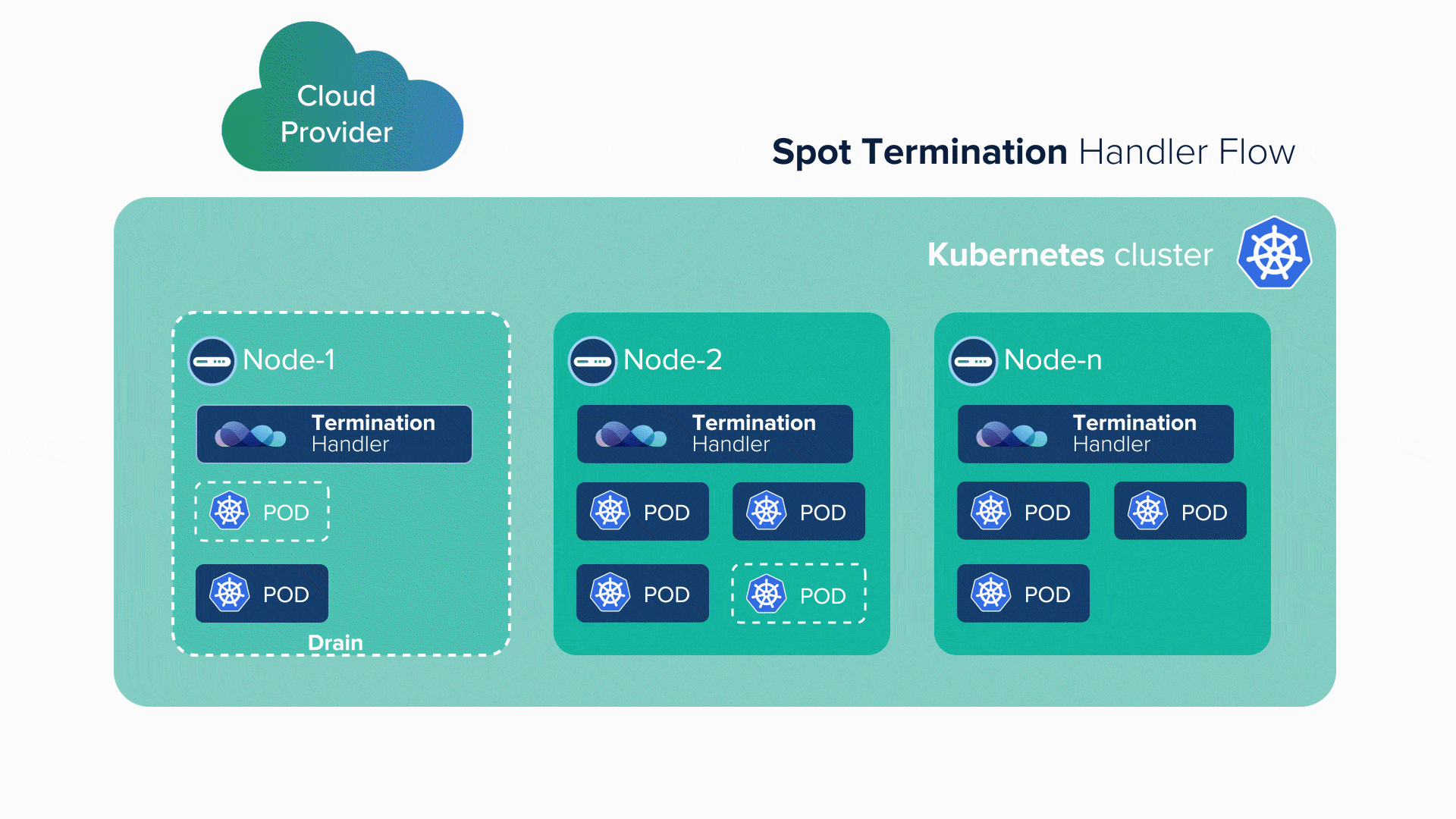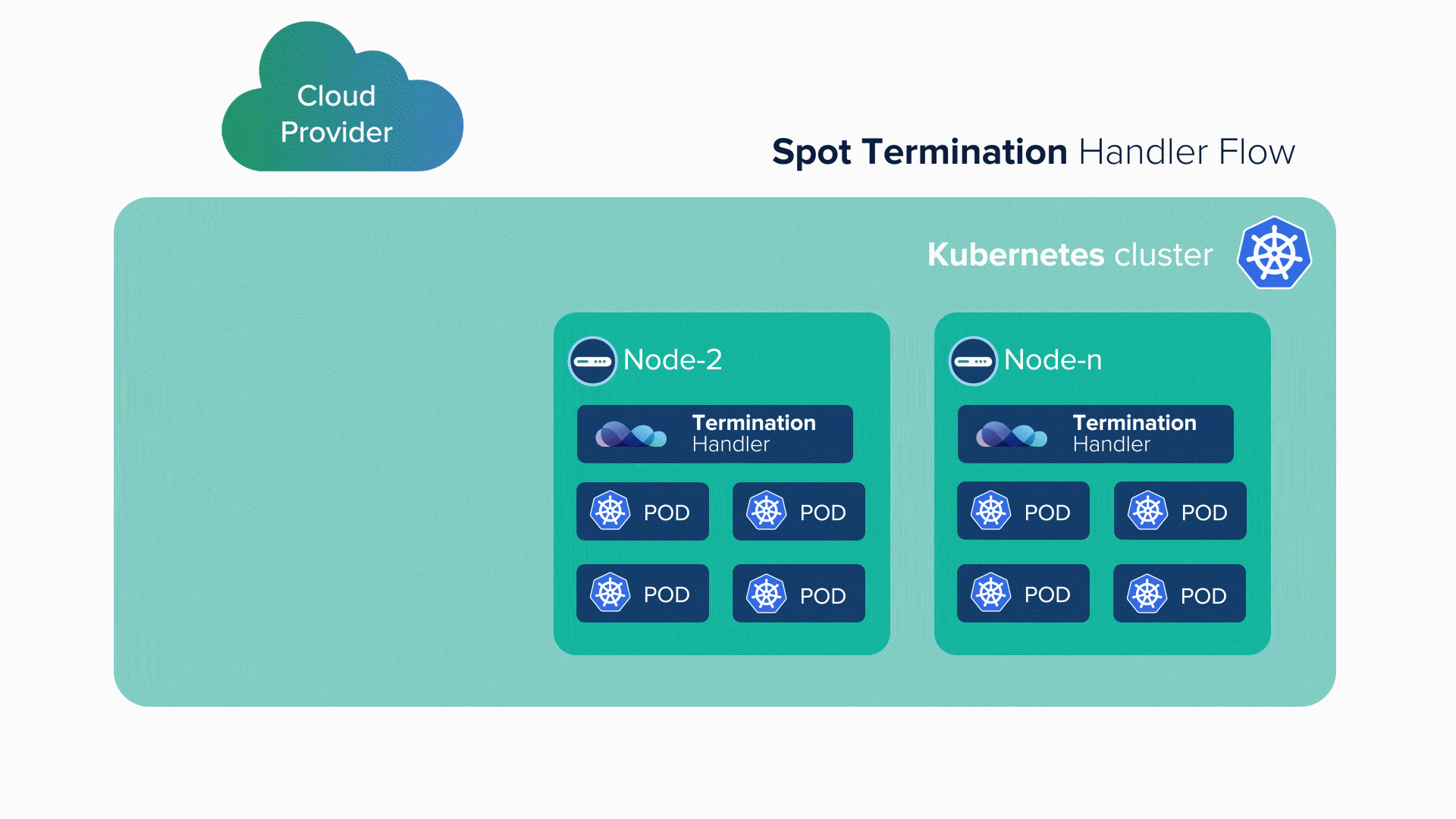
Managing spot instances is not possible manually, thus the orchestrator plays a great role in this regard. The infrastructure architecture, application architecture, and the strategy for deployment of instances play a huge role in such a scenario. Big Data sees many stateless services, so those are scheduled for a spot instance.
At Cuelogic, this has been done quite efficiently for a customer with up to 60% saving on the computing cost for the stateless workload. If we compare these savings to on-demand, there will be another 20-30% saving on computing.
DevOps Strategy: Total Cost of Ownership Versus Cost Of Managed Services
Saving on network cost, computing cost, and storage cost through automation and orchestrations is easier said than done. Building such large scale infrastructure requires considerable manual effort. Thus, all the network, storage and computing optimization will go in vain if the human effort cost surpasses them. Therefore, let’s explore how to save cost on the human effort for setting up, monitoring, and maintaining infrastructure.
As DevOps, an amalgamation of operations and development is evolving; developers are getting closer to the operations. Various new tools are launched in the market, including an orchestrator, Kubernetes. Kubernetes is a predominant open-source orchestrator available today that helps in building cloud-native applications.
Cloud-Native Computing Foundation (CNCF), a Linux Foundation project, hosts 100’s of such open-source applications and brings together developers, end-users, and vendors across the world. Selecting the best among this vast pool of applications based on individual requirements involves great efforts in architecting the systems. So saving the cost through cloud optimization comes at the price of increasing the human efforts.
This effort largely depends on the team involved, team members’ expertise and experience. For example, if a team is highly skilled at DevOps Services cloud and has architected it over and over again, subsequent projects will save on cost for hiring and maintaining these skill sets. The experienced developers can then look up to the new tools in CNCF and build a cloud infrastructure in the most efficient way.

Here comes the NoOps movement, which is based on the concept of an automated and abstracted IT environment from the underlying infrastructure through a series of functions. NoOps works in a way that it does not need a dedicated team for managing in-house software.
BigData consists of stateless workloads in abundance. These stateless workloads like data transformations and computing can be expressed in a series of functions and these functions can be orchestrated together for a serverless movement. In the case of No Ops, the developer has to develop functions and orchestrate them such that the result of one function is an argument to another function. All Cloud providers today support NoOps as AWS gives Lambda and API gateway, in Google, there are cloud functions and Azure provides Azure cloud functions.
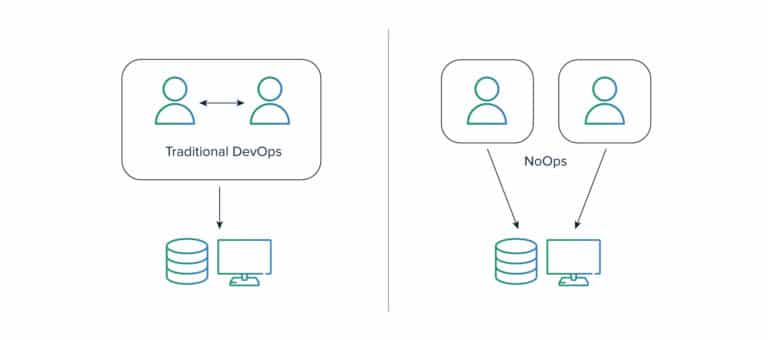
While in some cases the serverless movement is a good fit, in a few cases you will still have to go for an orchestrator based or cloud-native based approach. This choice largely depends on the customer being comfortable with vendor lock-in. As serverless movement is closely coupled to the cloud, vendor lock is imminent. The second thing to consider is, NoOps or serverless is great in terms of scaling systems because as the scale increases more functions are executed at the cloud provider’s end, but it comes at a price.
Again, depending on how large the scale grows, you will be paying a significant amount for getting these functions executed. The other thing is when the functions run in spot containers e.g. Lambda in AWS, they have limited resources like RAM, CPU, and technology choices associated with them. This seems a good option for smaller functions like Http requests for a page or small transformations. But as the complexity increases need arises to break larger functions into multiple functions and then orchestrate them using step functions.
Sometimes these functions could not be divided into multiple functions due to complexity. You may then hit a roadblock with this situation by not being able to deliver the application with intended functions. This is where you should consider moving to a containerized cloud-native approach. There is a flip side to every available option. In the case of the native cloud or DevOps approach too, there is the cost of human effort.
Therefore, based on the enterprise requirements and goals, a strategic decision needs to be taken considering both these options and select the best for that particular use-case.
Alternatively one can opt for a hybrid approach between DevOps and NoOps as applications and strategies evolve.
The two approaches can work together from the network’s perspective. The cloud providers give an option to have a common network container, like VPC in AWS where the Lambda functions can work and still invoke other workloads based on cloud-native, orchestrated things. Although opting for an infrastructure approach might see a spike in human efforts and the cost related to it, after the system is developed the cost will be nominal. If teams follow the right practices right from the start, keeping immutable infrastructure in mind, and to create templates out of it, you won’t have to manually create infrastructure and again later on.
All cloud providers support Infrastructure as a code or a template infra like AWS supports Cloud Formation, Azure supports Resource Manager and Terraform has Hashicorp. Also, inside those templates, one can define the NoOps part.
Governance In The Clouds
Cloud movement has taken its hold in the IT atmosphere but it comes with the inherent problem of governance. Over time, both cloud-native, and serverless will perpetually evolve. There will be a consolidation between technologies to simplify things, but again new technologies will keep coming up and adding complexity. Cloud providers these days are spending enormous time and money to provide better visibility to end-users and proactive monitoring.
This is an evolving space and several systems are already in place like RedLock which ties multiple accounts together and then looks at the problems with different accounts. In a typical enterprise scenario, there will be several teams working with different cloud providers using different accounts. RedLock will knit all these accounts together and show a single view of all your cloud expenses and resources, and then come up with suggestions on configuration, unused services, security issues, etc.
Additionally, there are tools like Trusted Advisor, and Cost Explorer from a cloud provider perspective that give regular suggestions and reports to help you understand which services to avoid, what optimizations to include, and also generate forecasted cost for the month. Keeping an eye on these tools day in and day out ensures that you take the right decision at the right time instead of waiting for it till the end of the month and then realizing what went wrong. Such a proactive approach needs to be there in operations for efficient clouds.
Wind-up: Optimization template
Cloud computing is deeply entrenched in the contemporary software arena. To ensure optimization in the clouds certain things need to be factored while architecting, developing, and operating the cloud.
We have seen how network optimization and storage optimization is crucial for cost-effective cloud implementations. We have also seen how DevOps movement has changed the way developers function today and how it has helped in faster delivery of systems and applications. Software technology has set up around cloud computing and DevOps and will continue to evolve. Cloud is here to stay and a lot more cross-functional teams, without any expertise in system administration, will be seen using cloud hereafter.
These teams, with varied skill sets, will be primarily focused on development. We also discussed some of the aspects that these teams have to consider especially as the system starts to scale. We have talked about disaster recovery, business continuity, and the different tools that have a proactive approach to maintain things like architectural decisions, thinking around cloud-native applications, serverless applications and keeping these things under control.
The technology landscape and computing landscape is changing rapidly. Professionals are learning newer ways to deliver technology. Enterprises too should develop cloud strategies that align with their organization’s goals and requirements to exploit cloud computing services to the fullest.