
Decoding Pipeline as Code (With Jenkins)

The growing focus on decentralizing the application building process through techniques such as micro frontends and microservices has propelled the need for revamped engineering practices that can manage pipelines as code. Primarily because pipeline-as-code can help speed up the process of building and progressively delivering software without compromising on consistency. The delivery pipeline templates that can standardize the way services and applications are built and deployed are a result of these changing requirements of the tech industry.
Pipeline as code technique rests on the paradigm that delivery pipeline configuration which builds, tests, deploys applications, and software infrastructure must be treated as code. As such, these must be categorized as source control and broken into modules of reusable components through automated testing and deployment.
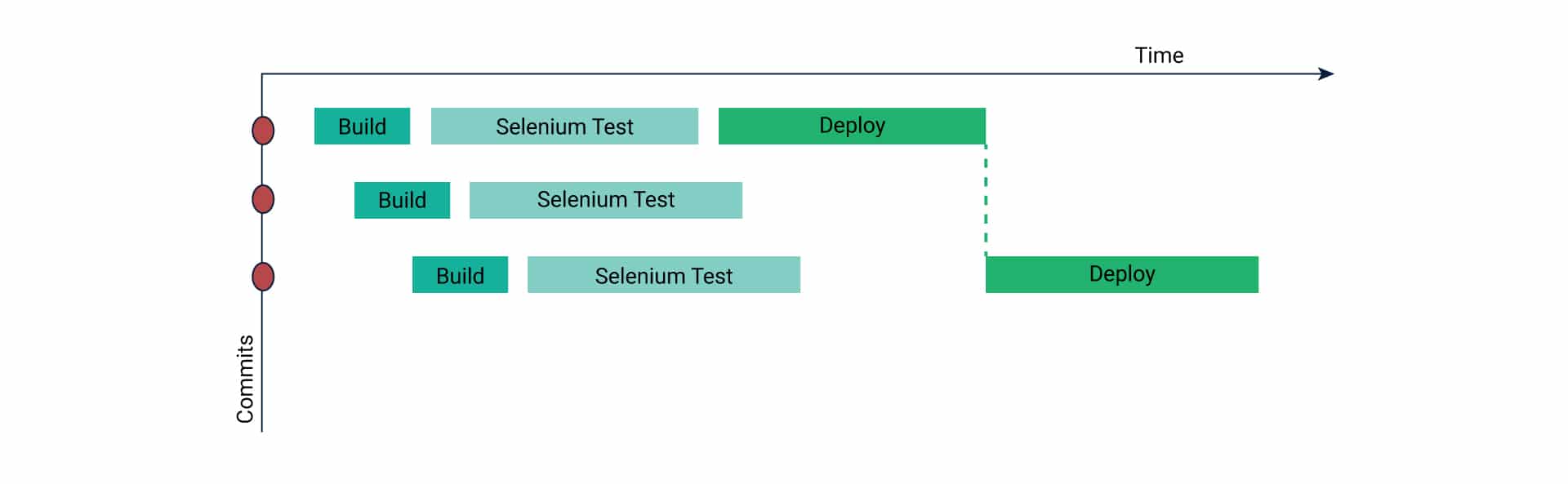
Different tools, today, are adopting this blueprint of pipeline-as-code to execute tasks at different stages of a delivery lifecycle – building, testing and deployment. In that sense, it can be considered as the up and coming backbone of the CI/CD approach.
What is Pipeline-as-Code?
Pipeline-as-code can be best defined as an approach of writing a deployment pipeline as code and categorizing it under source control. The history of the pipeline, thus, created is stored centrally and can be tracked easily. This technique eliminates the need for the traditional approach of manually creating and managing the deployment of a CI/CD pipeline.
Today, CI/CD tools and deployment pipelines are mainstream practices. The existence of pipeline-as-code is fast becoming a baseline standard for seamless execution of CI/CD. This is because deployment pipelines typically comprise complex workflows. Any microservice architecture entails several such deployment pipelines that are more or less identical.
Pipeline-as-code allows users to define different pipelined processes using code, which is stored and processed in the source repository. This, in turn, makes it easier to access, run and manage jobs for multiple deployment pipelines used in the CI/CD process. Users can implement the entire build-test-deploy pipeline for a project using the Pipeline plugin, eliminating the need to manually create and manage different pipelines.
Evolution of Pipeline-as-Code
Infrastructure-as-code, which means expressing the infrastructure for a deployment pipeline in the form of code, has been one of the cornerstones of DevOps services. In its most nascent form, this technique entails separately defining individual jobs in multiple pipeline tasks using web forms, text boxes and manually selecting entries from drop-down options.
These individual jobs were intertwined – each triggering the next into action – thus, creating a pipeline. This widely used approach for creating and linking jobs for building a pipeline has myriad limitations and challenges.
First and foremost, it goes against the very definition of infrastructure-as-code. The configurations of individual jobs used to be stored in the Jenkins configuration space in the XML format. This meant that these files could neither be read easily nor modified directly. As DevOps came into its own, more tools to implement infrastructure-as-code in its true earnest began to emerge.
How to Get Started Using Pipeline-as-Code?
The best approach to learn how you can use this scripted pipeline effectively is to download Jenkins, go through its several practical examples and then run it in a container. Write a line of code, then the next and then the next.
When you’re just starting, it is best to turn to the Jenkins website as a reference about the use of different syntax as well as the dynamic code generator. You can also refer to a Jenkins pipeline tutorial to understand the finer nuances of the implementation of pipeline-as-code.
To leverage this technique in the true sense, you must start by overhauling a functional UI-generated pipeline so that you get a point of reference about the expected behaviour and growth trajectory.
Your team must get the necessary training and access to credible resources to be able to adopt pipeline-as-code optimally because that’s where the future of CI/CD lies.
The program-based specifications of a pipeline are now a necessity to keep up with development taking place in multiple – often identical – pipeline and cater to their rapidly changing demands.
The best way to streamline the adoption and implementation of pipelines is to back it up with regular testing and supplement it with other beneficial software development practices. That way, you can rest assured that your CI/CD process will never grapple with bottlenecks interfering with quick deliveries.
Role of Jenkinsfiles
Even though the Jenkins application remains the primary environment for developing and deploying pipelines, the code for these pipelines can be placed in an external file known as the Jenkinsfile. This allows you to treat your pipeline code like any other text file. It can be stored and tracked in source control and be subjected to reviews.
Besides, this code can be stored and maintained alongside the product source thus facilitating the transition of a pipeline into infrastructure-as-code. One of the biggest advantages of using Jenkinsfiles is that the pipeline definition lives with the product source which means you don’t have to explicitly direct it for obtaining the source code.
With this, you can meet the DevOps goal of your pipeline being treated as code. The only potential downside to this approach is that discovering problems can be more challenging when you’re working in an external file outside the Jenkins application environment. This can be mitigated by developing code as a pipeline project within the Jenkins application and then converting it to Jenkinsfile.
Pipeline as code in Jenkins
Jenkins caught up with the rapid developments in the realm of DevOps and the pipeline-as-code functionality was released in Jenkins 2.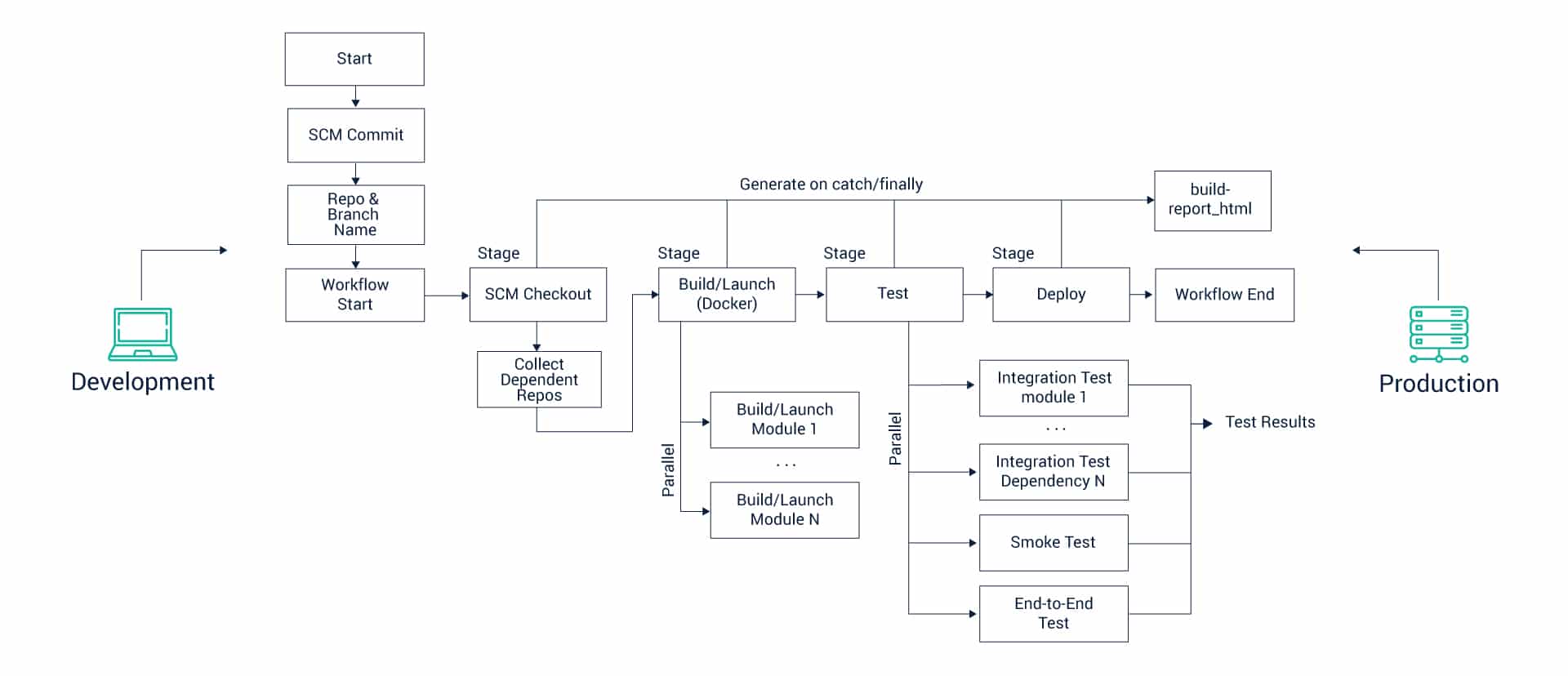
Jenkins and its plugins serve as the building block of creating, storing and running pipeline-as-code today. Here is the top Jenkins pipeline syntax that you need to be well-versed with to be able to use this technique to meet your DevOps goals:
Jenkins DSL Steps
The workflow plugin was one of the first milestones in the Jenkins journey to develop the pipeline-as-code model. This evolution process included the creation of domain-specific language (DSL) steps that facilitated coding uncomplicated jobs in Jenkins. Consequently, this led to the creation of simpler pipelines.
Today, DSL steps must be incorporated into different plugins for them to be compatible with Jenkins 2. This syntax is an automated substitute for actions that were traditionally executed using web forms. While DSL steps are an important part of the puzzle, it isn’t enough to build a full pipeline on its own.
Jenkins Scripted Pipeline
The scripted pipeline is the indigenous approach used for creating pipelines in Jenkins 2. These pipelines are contained in a node block – a system that runs jobs using Jenkins agent pieces. This node block itself is a construct called a closure. Using these elements, a scripted pipeline can be defined by creating a new pipeline project via Jenkins and entering the code in the Pipeline Editor.

The node block – though a valid syntax on its own – is used in Jenkins pipelines to create stages. These stages then divide the pipeline into functional units. The scripted pipelines provide a great degree of flexibility and accord programmers ease-of-use.
Jenkins Declarative Pipeline
The Jenkins declarative pipeline syntax performs the task of declaring what you want to include in your pipeline. It is essentially a more well-defined structure that builds upon DSL steps. The declarative pipeline structure includes different directives that indicate the items you want in your pipeline. This well-defined structure brings many advantages to using pipeline-as-code effectively.

First and foremost, by declaring what’s to be included in the pipeline, it helps facilitate an easier shift from Freestyle to pipelines-as-code. Besides, you get a clearer, more coherent syntax, and smoother integration with the Blue Ocean graphical interface.
Jenkins Blue Ocean Pipeline
The Jenkins Blue Ocean provides a UI for building pipeline syntax. The focus here is on reimagining the user experience of Jenkins. Blue Ocean, which has been designed from the ground up, helps reduce clutter in pipelines and offers every team member a greater clarity. The USPs of Blue Ocean include a more sophisticated visualization of CO pipeline, the inclusion of pipeline editor that makes pipelines more accessible, and an element of personalization catering to role-based needs of different team members.
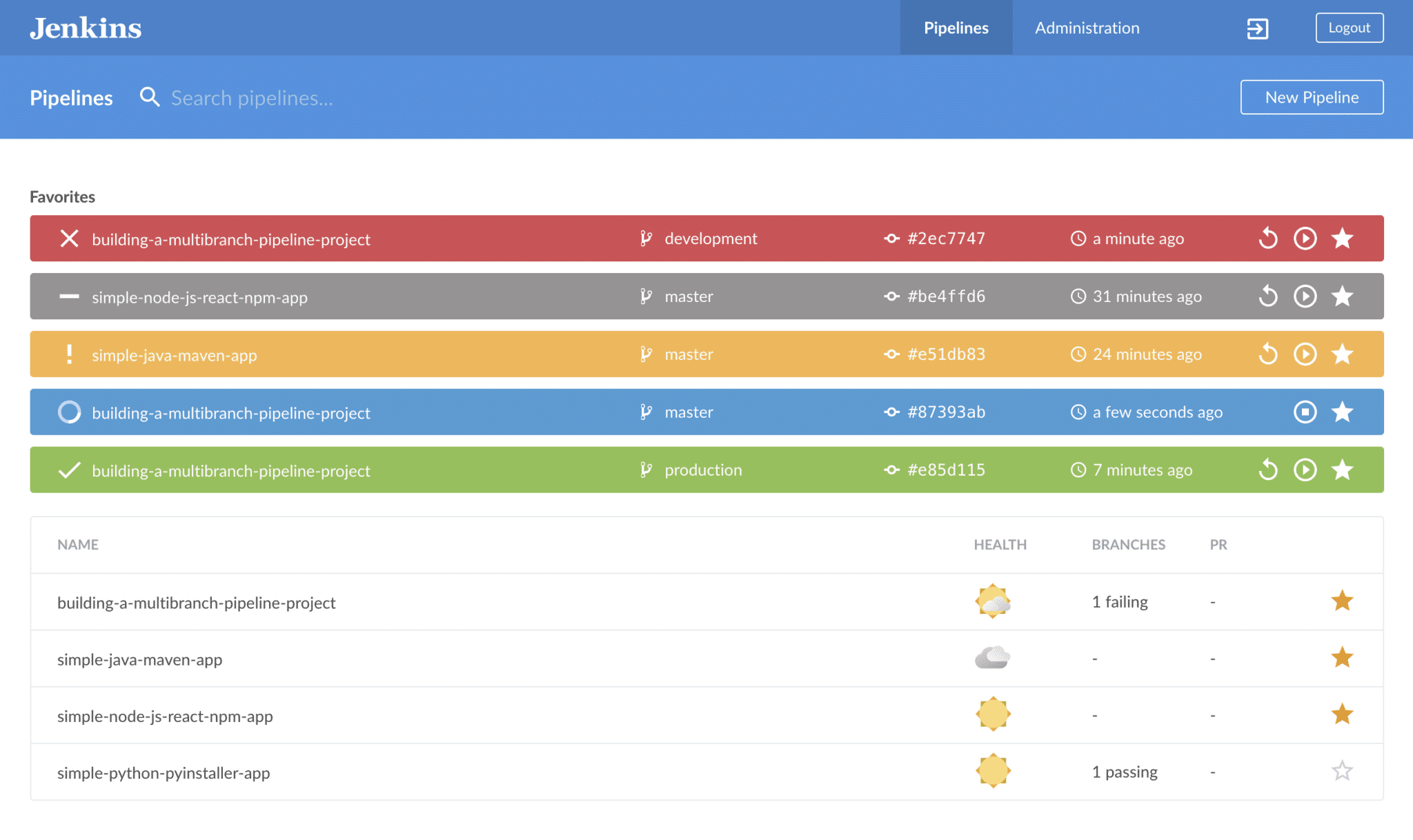
Blue Ocean can show you exactly at what point does your pipeline need attention. This helps to expedite the handling of issues and increase productivity. It also offers native integration for pull requests that makes code collaboration in Bitbucket and GitHub more productive.
Benefits and Drawbacks of Pipeline As Code
Pipeline-as-code is being touted as the future of CI/CD process and DevOps growth in general. But what is it about this approach that makes it so effective? And are there any shortcoming and pitfalls that you must be mindful of when implementing pipeline-as-code?
Let’s take a look at its top benefits and drawbacks to find out:
Benefits of Pipeline-as-Code
The top benefits of pipeline-as-code include:
- Minimal manual intervention: In a pre-pipeline-as-code era, teams had to manually configure CD and CI tools to create and get a new deployment pipeline running. Pipeline-as-code reduces the need for manual intervention to minimal by allowing you to write the deployment pipeline using code. This facilitates ease of collaboration without the need for manual edits inside the tool. Similarly, the process to update a pipeline also becomes automated. The CI/CD tool picks up and implements changes on its own. This is a giant leap forward from manual interventions for processing even the smallest of changes.
- Ease of maintenance: With this technique, you store your pipeline in a version control system. This allows you to track the history of multiple pipelines and pinpoint any changes made to the deployment pipeline. In the past, if a change made to a pipeline caused it to break, the development team would be blocked out. But now since you can track every pipeline nearly in real-time, the risk of breakdown due to rogue changes is virtually eliminated. The pipeline is open to code review which means different people from different teams can review any changes made to it. If a rogue change causes a breakdown in the deployment pipeline it can be easily reverted, thanks to the history tracking functionality.
- Consistency: Using pipeline-as-code also gives you a sense of consistency, as there is no risk of loss when a deployment pipeline is stored in a version control system. Even if you lose data due to a CI/CD tool crashing, the lost data pertaining to the deployment pipeline can be recovered from the control system and quickly restored. This element of consistency wouldn’t be possible if a pipeline was not hosted in a version control system as your CI/CD tool wouldn’t know where to look for lost data. In that case, it’d have to be created again manually.
Drawbacks of Pipeline-as-Code
These benefits of pipeline-as-code drive home the point that it is essential to implementing CI/CD in an efficient and scalable manner. However, you need to address its drawbacks to avoid hold-ups and bottlenecks. The biggest – and perhaps the only – drawback of pipeline-as-code is its perceived lack of user-friendliness. Writing deployment pipelines as code comes with a steep learning curve since it is something that not a lot of people are well-versed with.
Learning the myriad nuances and pulling off writing pipelines as code can seem tricky in the beginning. Thankfully, there are a lot of credible online resources to counter this stumbling block. You can turn to Jenkins pipeline tutorials or step-by-step guides to help you get started. Once you’re familiar with the process, try to re-use components across projects. In this way, you will be able to create a library that you can turn to when creating new pipelines and cut back on your development time.
To Sum Up
Anyone committed to CI/CD should embrace and implement pipelines-as-code at the earliest. It can help simplify the process of creating deployment pipelines and also cut back on several overheads. The ability to track changes as you go also play a key role in enhancing productivity and reducing breakdowns.