
Microservices in practice: From Architecture to Deployment

Microservices is the latest edition in the jargons of software applications. Software applications which had Monolithic architecture before, are now making a move to the Microservices due to several factors. Being the current favourite among the developer community, Microservices is enjoying a fair share of its fan following.
Due to this popularity, although many more are making a move to the Microservices, still people are yet to understand how it comes as a practice since it is relatively new. In this article, we would cover right from the basics of Microservices to its architecture and how it can be deployed in real-life use cases.
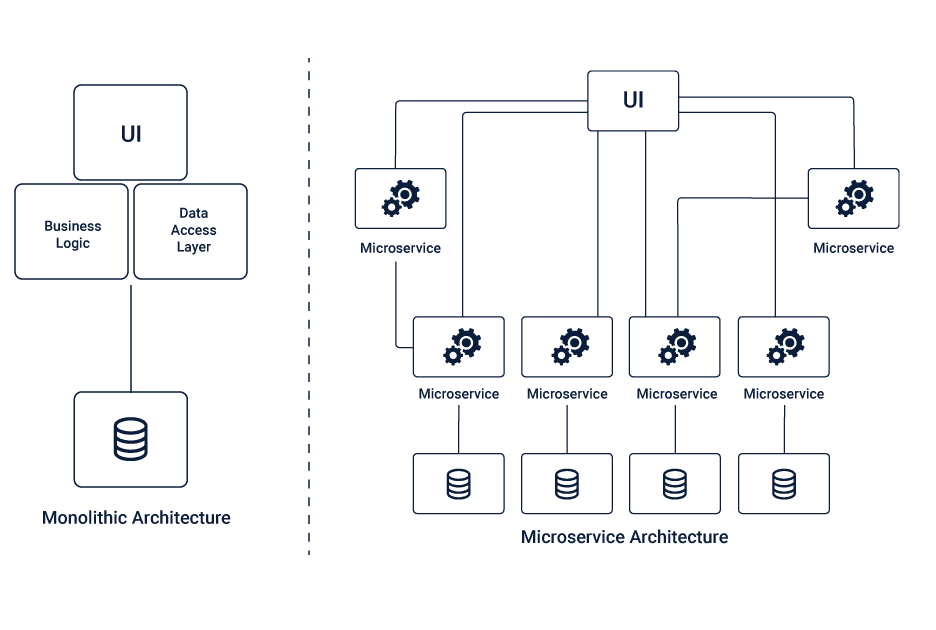
To get a thorough understanding of the Microservices right from the architecture to the deployment, we need to know the Monolithic architecture, break down of Monoliths to Microservices, and evolution of Microservices.
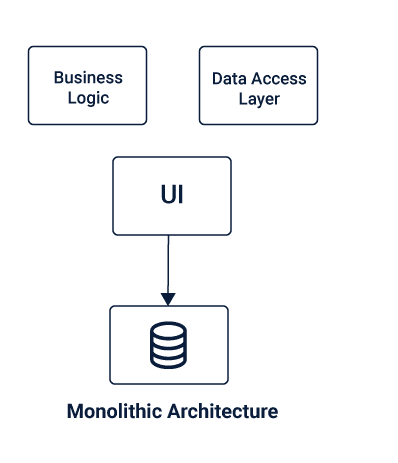
Monolithic Application
Monolithic Architecture is a single-tiered software application architecture that combines its UI and data access code into a single program on a single platform. It is one entity software application that contains everything in a single module.
This monolith module is a completely independent and self-contained entity, that is responsible for taking care of the entire functioning of the software. It does not depend on any other computing application.
A monolithic software application comprises of a database, business logic, client-side User Interface, and Data Interface, which all work together as a single entity. There is only one central code that has to be deployed for the monolith application. This means any changes in the system would mean a complete deployment of the updated version of the monolith application.
Microservices Application
Microservices architecture is a cluster of independent microservices which is the breakdown of the Monolithic architecture into several smaller independent units. These microservices are meant to handle a set of their functions, using separate business logic and database units that are dedicated to them.
It is more like a suite of several small independent services with individual functions combining to form a complete application. Microservices are lightweight and are interconnected using APIs that are used for internal communication.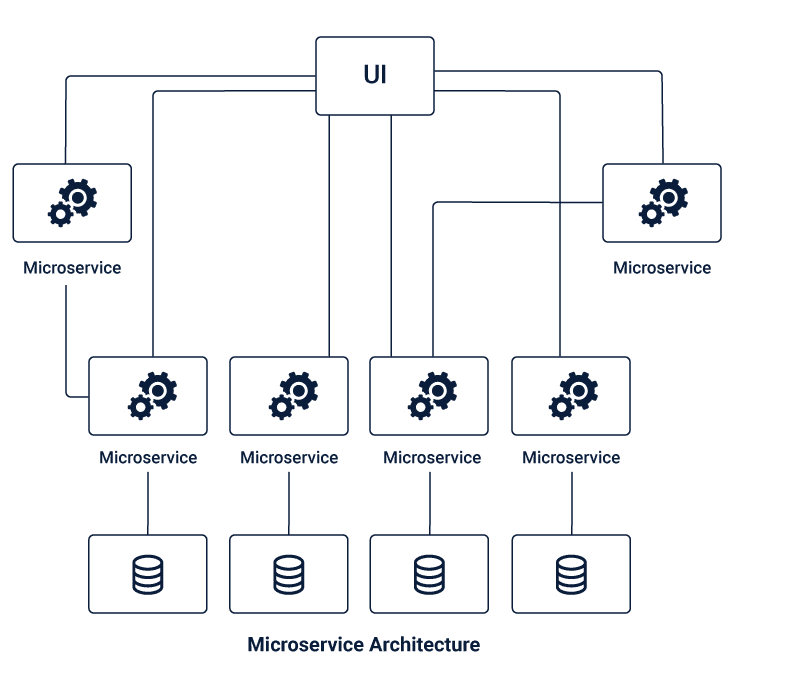 Microservices have their independent code, that can be deployed individually for each of these microservices, without affecting other modules of the application. These are loosely coupled and need not have the same technology stack, libraries, or frameworks.
Microservices have their independent code, that can be deployed individually for each of these microservices, without affecting other modules of the application. These are loosely coupled and need not have the same technology stack, libraries, or frameworks.
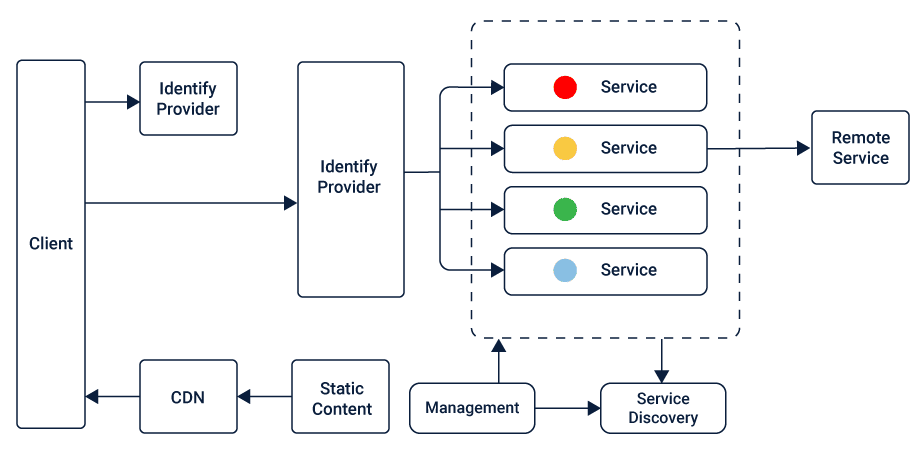
How Microservices evolved from Monolithic Architecture?
Monolithic Applications faced severe issues with scalability, agility, and applying changes or introducing any new technology in the application. There were many issues like scalability that were quickly resolved with the Microservices architecture, that encouraged people to make a move from the Monolithic Architecture to the Microservices.
It happens mainly because although the applications start as simple applications with a monolithic architecture, they do grow with time as the developers keep on adding stories at every sprint, introducing more features to outdo their performance and amaze the end users. This makes the application massive as they scale at a constant pace with time.
Though initially, the scale might not seem significant, it does grow to be huge after some point of time. At that stage, handling the monolith becomes a challenge in itself, and nothing can be even more challenging than adding several more features to keep up the growth and enhance the customer experience.
Fulfilling the fast-paced business requirements and making subsequent additions to the application becomes a humongous and challenging task, that comes with the risks of impacting the entire use at any point of time.
For obvious reasons, growth and upscaling cannot be made stagnant at any point of time, and thus one needs to find an exit from the monolith, breaking it down to several microservices for the ease of operating.
Designing Microservices Architecture
The first and foremost step for having a high performing Microservices application is designing the architecture. You have to ensure an optimized design that can offer the best and overcome most of the challenges.
A Microservices that is designed diligently, keeping in mind the size, scope, and other concerns of the Microservices to fulfill the business requirements for a better end user experience.
The size of each of the Microservices plays a vital role in the overall productivity, costs, and the resources allocation of the project. A quantity that can balance out all the factors considering the future scope and scaling should be determined while designing the architecture to get the best results.
The scope of each of the Microservices has to be determined in the line of business requirements and features to ensure that the similar or dependent features are held together in a container to minimize the dependencies within the architecture.
While deciding the scope of each of the microservices, one has to ensure cohesiveness is highly practiced, so that the final Microservices are loosely coupled without any significant dependencies that can complicate the architecture.
These Microservices should have their scopes cover all the possible business requirements, functions, and features for smooth and seamless functioning. The capabilities and concerns of these Microservices should be thoroughly addressed as per the current business requirements and future growth prospects. You should underline their skills and ensure a Domain Driven Design laying boundaries for smooth independent functioning.
Communication in Microservices
In Microservices Architecture, the Microservices communicate with each other using messaging, using a lightweight and straightforward mechanism. There are Synchronous and Asynchronous messaging techniques and several message formats that the Microservices could follow to communicate depending upon the purpose and requirements.
Synchronous Messaging Techniques
REST is one of the highly preferred synchronous messaging techniques used by the Microservices, where the HTTP request-response that defines a set of constraints based on the resource API.
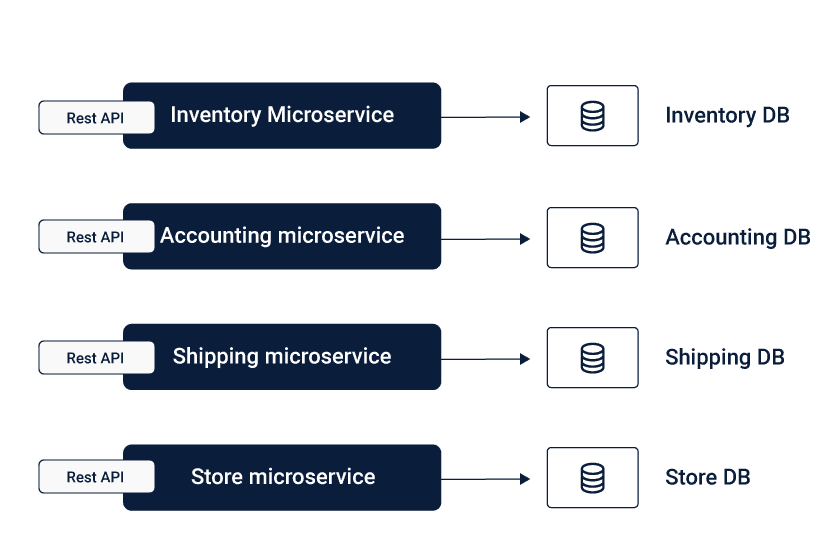 Let us have a closer look at how REST works for the Microservices. In the REST communication, services communicate over HTTP in the Request-Response set, without any additional infrastructure requirements.
Let us have a closer look at how REST works for the Microservices. In the REST communication, services communicate over HTTP in the Request-Response set, without any additional infrastructure requirements.
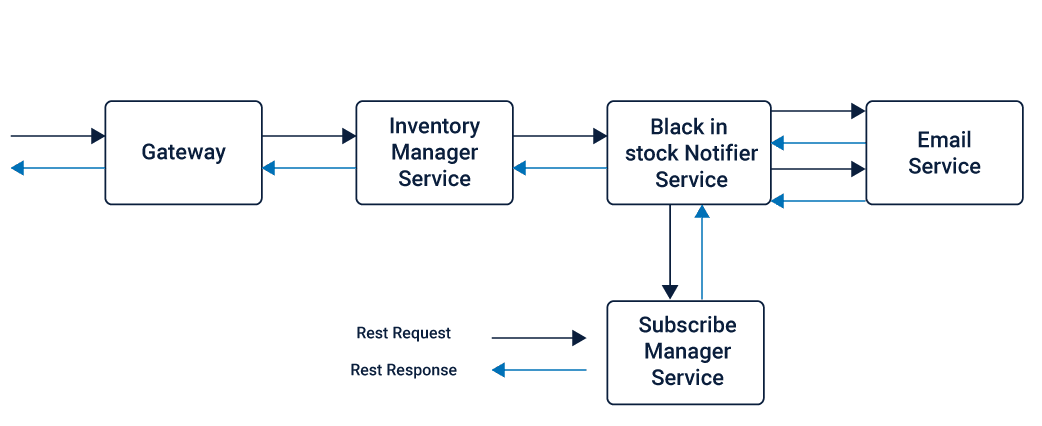
As REST allows a point to point communication, it can be used to connect the microservices directly for the discussion, this can surface the issue of coupling, causing several dependencies within the Microservices.
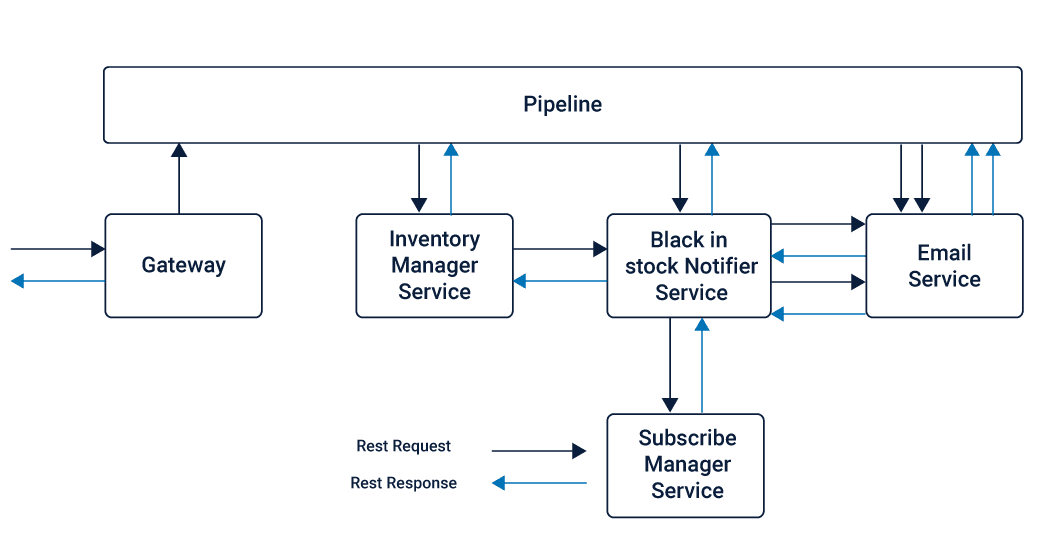
Thus, a current pipeline connecting all the Microservices can be used as an interface where all the Microservices connect via REST API. Although the communication offered in this case is still REST, it does not follow a point to point approach. Instead, the Pipeline here is responsible for orchestrating the message between the required Microservices using the REST protocol.
Thrift is another synchronous messaging techniques that form a Remote Procedure Call (RPC) framework that can be used as an alternative to the REST messaging technique.
Thrift allows the developers to generate all the necessary code to build RPC clients and servers by defining data types and service interfaces in a single language-neutral file. Saving works in binary and thus supports multiple programming languages such as C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml, Delphi, etc.
Asynchronous Messaging Techniques
In cases where an immediate response is not required Asynchronous messaging techniques such as AMQP, STOMP, or MQTT can be used.
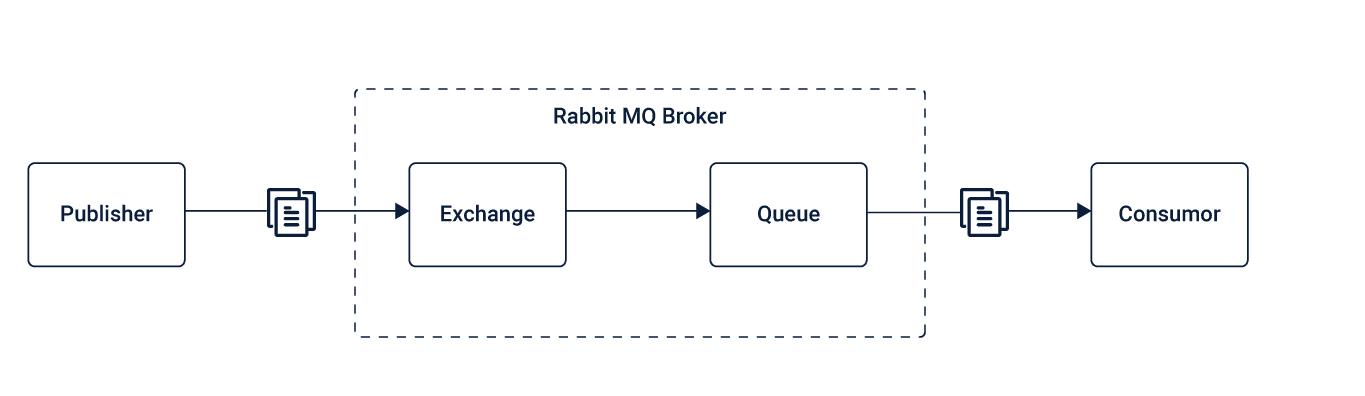
AMQP is an open standard application layer protocol used for asynchronous messaging that is highly reliable and secure. AMQP is a binary, flow-controlled communication protocol that has encryption.
RabbitMQ uses AMQP protocol to communicate by queuing the message and siphoning it off to single or multiple subscriber programs that listen to the RabbitMQ server. As RabbitMQ is written in Erlang, you must have Erlang installed in your system before you download the RabbitMQ.
STOMP is a lightweight and straightforward text-oriented messaging protocol, that provides an interoperable wire format, enabling its clients to communicate with the message broker. Similar to AMQP, STOMP also provides a message/frame header with properties and a frame body, making it interoperable and straightforward.
But unlike AMQP, it does not deals with queues and topics, making the user map the internal communication destination.
MQTT, on the other hand, provides publish and subscribe messaging without any queues, which can serve efficiently on resource-constrained devices and low bandwidth, high latency networks such as dial-up lines and satellite links. It offers little footprints and a compact binary packet payload, making it suitable for simple push messaging scenarios.
Based on the communication mapping and application requirements, one has to choose for the best asynchronous mechanism that can establish efficient communication in the Microservices of an application.
Message Formats
Depending upon the communication requirements of the application, language integrations and the message to be communicated whether synchronous or asynchronous, different message formats such as JSON, XML, Thrift, Avro or ProtoBuf could be used for communication in Microservices.
Integration of Microservices
As the individual Microservices serve different tasks that come within their scope, to realize a business use case, several Microservices have to coordinate and deliver the desired result in a combined effort.
Thus, there has to be inter-service communication using a lightweight message bus or gateway that involves minimal routing without any business logic to avoid complexity within the architecture.
There are different ways in which the inter-services communication takes places, depending upon the requirements and frequency of communication.
Point to Point Inter-services Communication
In this method of inter-services communication, the routing logic depends entirely on the endpoints, letting the Microservices to communicate directly.
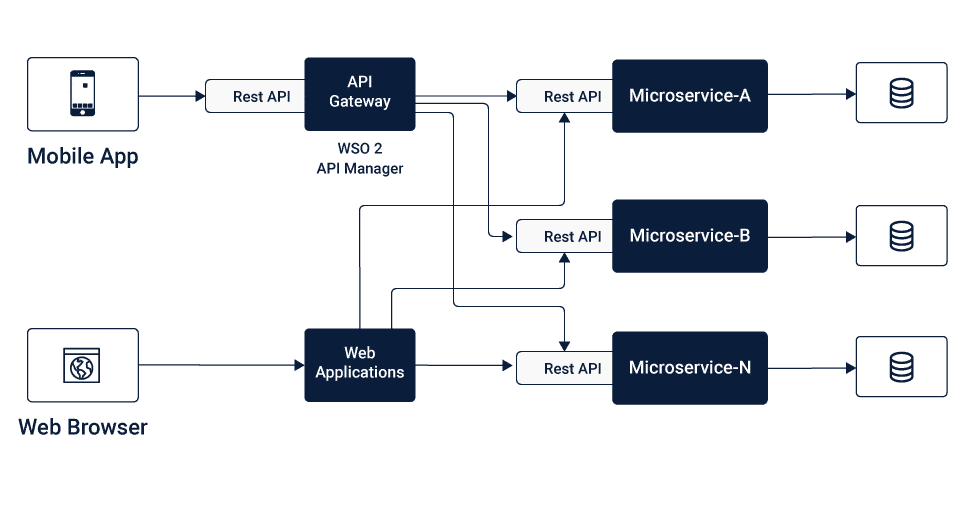
API Gateway Inter-services Communication
In this method of inter-services communication, a lightweight message gateway acts as the main entry point for all the client or consumers, where the standard and non-functional requirements are addressed at the portal itself.
This helps in optimizing the architecture by reducing unnecessary couplings between the Microservices.
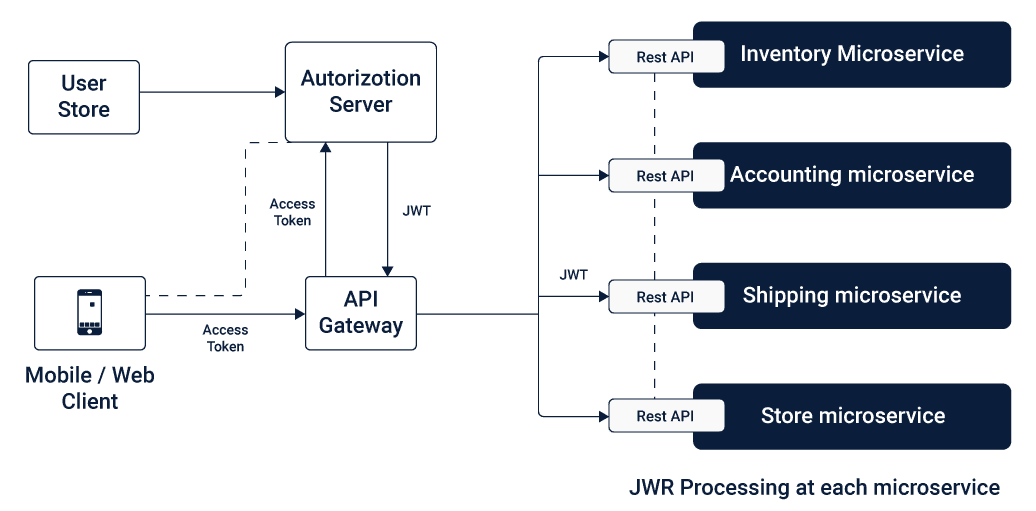
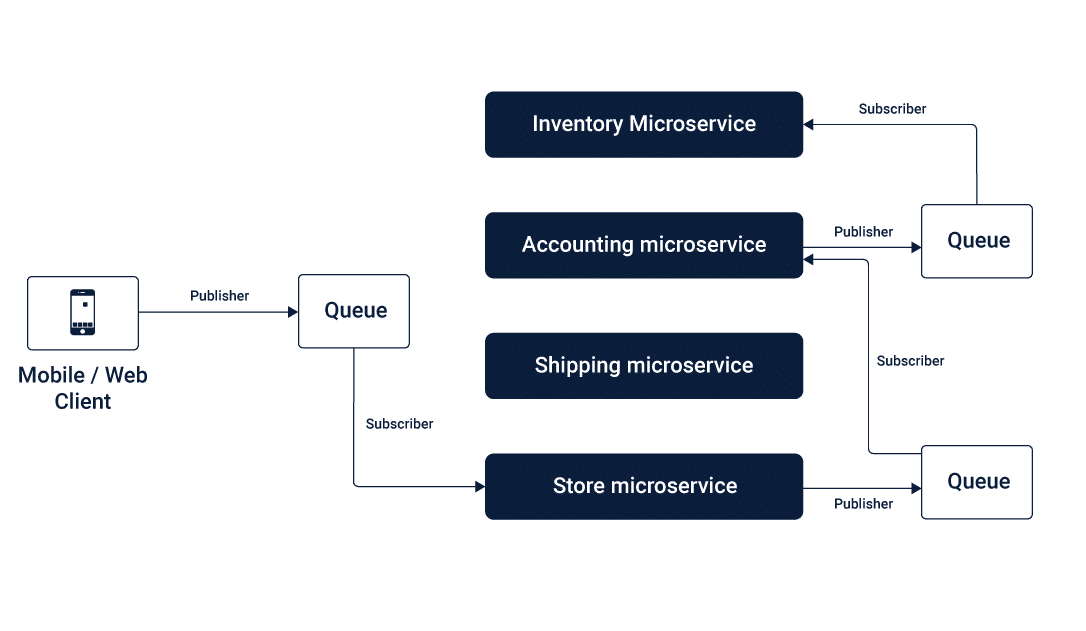
Message Broker Inter-services Communication
In this method of inter-services communication, asynchronous messages with one-way requests and publish-subscribe approach are queued to connect the different Microservices as per the business logic.
 Data Management in Microservices
Data Management in Microservices
For Microservices architecture, each of the Microservices holds their data individually using separate Databases, unlike the Monolithic Applications that have a centralized database, making each of the Microservices utterly independent of each other.
This means each of the Microservices is solely responsible for their Data Integrity, which might raise concerns regarding the consistency. These concerns over Data practice consistency can be addressed by formulating standard protocol and compliances that are to be uniformly practiced across the fleet of Microservices.
Microservices architecture offers you the flexibility to choose different databases for different Microservices depending upon the type of data (whether structured or unstructured) that needs to be managed, making the system optimized.
Governance in Microservices
Since the Microservices work individually on different business requirements in a decentralized fashion, it is better to ensure a Decentralized Governance, where the individual teams are wholly responsible for their respective Microservices.
To ensure consistency among the practices, you can ensure common compliances and standard procedure protocols that have to be followed by each of the teams for uniformity throughout the entire application.
Service Registry and Discovery in Microservices
To maintain coordination among the Microservices to realize several business use cases, it is essential to locate the respective Microservices timely using the Service Registry and Service Discovery, respectively.
Service Registry holds the location instances that could be used to find the available Microservices to fulfill the task.
On the other hand, Service Discovery mechanisms find the available Microservices using the details in Service Registry. Client-side Discovery and Server-side Discovery are two mechanisms of Service Discovery that are used by different Microservices Applications.
Deployment of Microservices
Deployment is very crucial for the functioning of Microservices. Here are the points to keep in mind while deploying the Microservices:
Modularize the self-contained Microservices making them as standalone components that can be reused across the application using automation.
Connect the microservices using bindings that can be manipulated easily.
Deploy the Microservices independently to ensure agility and lower the impact on the application.
You can use Docker to deploy the Microservices efficiently. Each of the Microservices can be further broken down in processes, that can be run in separate Docker containers. These can be specified with Dockerfiles and Docker Compose configuration files.
You can use provisioning tool such as Kubernetes to manage and run a cluster of Docker Containers across multiple hosts with co-location, service discovery and replication control feature making the deployment powerful and efficient in case of large scale deployments.
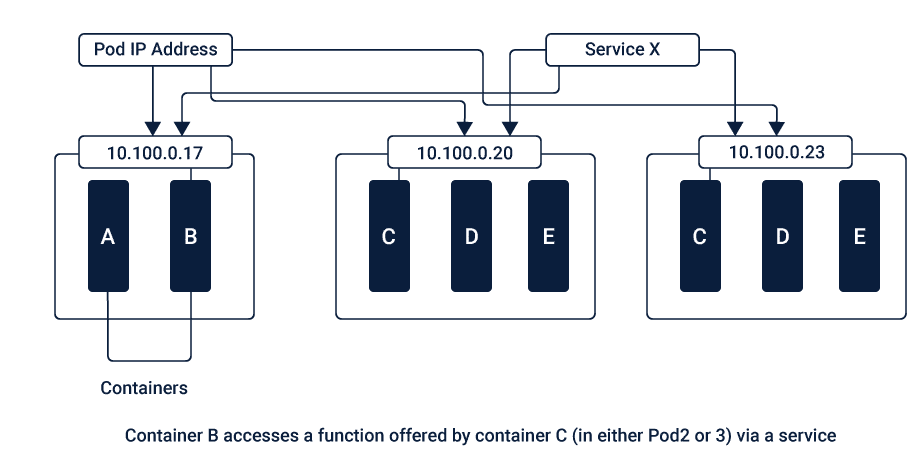
Kubernetes defines resources as Objects such as Pods, Services, Volumes and Namespaces.
Pod, which is the basic unit in Kubernetes consists of one or more containers that are co-located on the host machine and share the same resources. These pods have a unique IP address and can see other seeds within the cluster.
Service combines a set of pods that work together inside a cluster. Service is generally not exposed outside the cluster except onto an external IP address outside the group using one of the behaviors: ClusterIP, NodePort, LoadBalancer, and ExternalName.
Volumes are the persistent storage that exists for the lifetime of their respective pods, that are mounted at specific mount points within the container. These are defined by the pod configuration, which cannot be installed onto or link to other volumes.
Namespaces are non-overlapping sets of resources which are intended to be used in environments with many users that are spread across multiple teams, projects, or environments.
Replication and scaling in Kubernetes is done by running a specified number of a pod’s copies across the cluster using a Replication controller, that also takes care of the pod replacement.
Apache Mesos is another engine that could be used to deploy Microservices apart from Docker and Kubernetes.
Post-Deployment Concerns of Microservices
Unlike the Monolithic Architecture where everything was centralized, Microservices have everything decentralized at the Microservices level, making each of the Microservices entirely responsible for all the end to end concerns.
This includes not just the design and deployment aspects but the post-deployment concerns such as Security, Data Integrity, and Failures. In Microservices, Security and Data Integrity are considered at the Microservices level, where the independent databases follow a uniform compliance and security measures are practiced.
While failures are addressed by lowering the impact on the entire application due to a Microservice failure, this makes the architecture more fault tolerant as compared to the Monolithic architecture.
With concern addressed at the Microservices level, it is essential to make individual Microservices reliable to make the application robust as a whole.
The Bottom Line
Despite the complex nature, Microservices have managed to solve the significant concerns of flexibility and to scale for the software applications in the wake of steady fast-paced growth in the IT landscape.
Keeping the business requirements at utmost priority, Microservices can be designed well and following the best practices while deploying can make a highly functional and productive software application.
Hope you found this article useful, let us know in the comments! And follow us for more insights in technology space.