
When and How to Leverage Lambda Architecture in Big Data

In the present technological scenario, many companies are getting attracted to Big data. But previously Big data used the Hadoop system and faced the problem of latency. To resolve this problem altogether a new architecture came into existence that can work for a large size of data that too at high velocity.
In this piece, we will try to make it simple to understand the architecture that makes it modest to work with Big Data, which is none other than Lambda Architecture. The architecture was created by James Warren & Nathan Marz.
Let us understand a few things about Lambda Architecture
What is this architecture all about?
To make a better business decision and insight Big data systems are built to handle variety, velocity, and volume.
This is a new tactic of Big data that is designed to process, analyze and ingest the data that is complicated and large for the traditional system. The hybrid approach of the architecture helps the Big Data system in real-time and batch processing of data.
In this architecture, one can query both fresh and historical data. To gain insight into the historical data movements the information is sent to the data store.
The principle of this architecture is based on Lambda calculus so it is named Lambda Architecture. The architecture is designed to work with immutable datasets, especially for its functional manipulation.
The architecture has also solved the problem of computation of arbitrary functions. In general, a problem can be segregated into three layers:
- Batch
- Serving
- speed
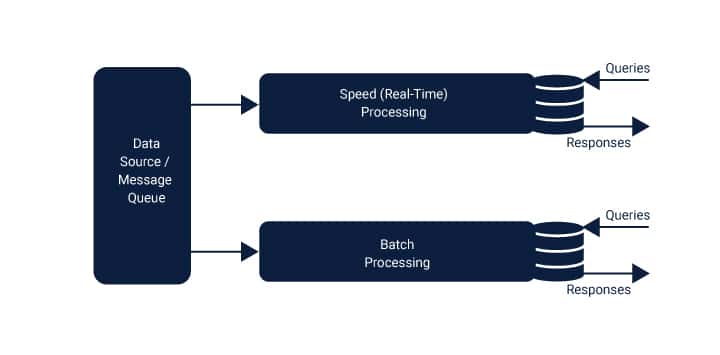
Image given below will give a better understanding of the layers discussed above.Similar to Hadoop, here the Batch layer is termed as “Data Lake”. This layer also acts as a historical archive to hold all the data that has got feed into it. It also supports batch processing of the data and helps to generate analytical results.
For the steaming and queuing of data, the speed layer comes into action. This layer has a similarity with the batch layer as it also computes analogous analytics. Only the exception is in this layer analytics are done on the recent data. The responsibility of this layer is to perform analytical calculations on real-time data. Depending on the movement of the data; the data can be less than or one hour old.
The serving layer is the third layer that combines the result generated from both the layers and produces the result.
When the data gets fed into the system it gets segregated into batch and speed layers. The requests get an answer by integration of both batch view and real-time views.
Although the batch layer has two very important roles.
- Management of master data set.
- Batch view pre-computation.
The batch layer output is in the pattern of batch views whereas the speed layer outcome is in the pattern of real-time views. The results then get promoted to the serving layer. Indexing of the batch views takes place in serving layer so that requests can be done at low latency and on-demand.
The speed layer also termed as stream layer takes the charge of the data that has not been delivered in the batch views because of the latency of the batch layer. This layer only deals with the recent data so that it can deliver a complete view by the creation of real-time views.
In short, we can say in the Lambda architecture pipeline of data is divided into different layers and each layer has a distinctive responsibility. In each layer, provision is there to choose the technology. For example, in the Speed layer, one can choose Apache Storm or Apache Spark streaming or any other technology.
In lambda architecture mistakes can be recovered quickly for that it has to revert to the unaltered version of the data. It can be done as here data is never updated but it is appended so if by mistake the programmer inputs bad data, he can simply remove and recompute the data.
Data Lake:
The best feature of this architecture is that it has nearly unlimited memory capacity and data storage space. It has even an in-memory database that has a capacity in terabytes that is distributed over the entire cluster. Using this architecture can be relatively economical as it has built-in tolerance for faults.
With such a huge cluster Data lake can be created for any company. All the data of the company can be stored in the cluster and can be shared on the cloud. The computing power of the architecture can be used to do the analysis for the cluster. With this fault resistant architecture, one can save a lot of money as a lot of redundant ETL processes can be prevented from interacting with different systems.
Applications of Lambda architecture:
There is always innovation in the area of Big Data. Lambda architecture uses use cases based on log insertion and the analytics accompanying that. Mostly the log messages are unchallengeable and are created at high velocity, so they are sometimes called “fast data”. There is no hard and fast rule that each log ingestion has to get a response from the entity from which the data got delivered; as it is a one-way pipeline.
Data processing in Big data can be differentiated into two data pipelines. One in which data is collected in huge amount from various origins and is then stored in a dispersed manner. That is then analyzed to get the exact view for better business decisions. The process followed can be referred to as batch processing pipeline as well.
In simple words, data pipeline architecture collects the data, routes it to gain insight into the business intelligence and analysis. It extracts and transforms the data and then feeds it into the database.
Another technique of data processing in Lambda architecture followed is an analysis on information is done when it is still in motion and that process is referred to as Streaming Data Pipeline. Here the calculation is done on the live data. The framework can be used for this is Apache Spark. In Spark the data is broken into small batches, it then stores in the memory and processes the data and then finally releases the data from the memory. The process followed here reduces the latency as the computation is done in memory.
Merits of Lambda Architecture
Lambda architecture has a lot of benefits, the significant among them are fault tolerance, immutability and it can also it can perform re-computation and precomputation.
Some of the vital benefits of this architecture are discussed below:
- In this architecture, data is kept in raw format. This helps in the application of new use cases, analytics and a new algorithm to the data by creating a simple batch and speed views. This is a tremendous advantage over traditional data warehousing. Previously data schema needed to be changed for the new use cases and was a time-consuming process.
- Re-computation is another important feature of this architecture. In this fault tolerance can be corrected without much difficulties. When a data lake receives large amounts of data, chances are there that data loss and corruption may happen but it cannot be afforded. This architecture provides the rollback, data flush and re-computation of the data to correct these errors.
- The architecture gives a lot of emphasis to keep the input data unchanged. Model data transformation is another important feature of the architecture. This provides trackability to MapReduce workflows. MapReduce does batch processing on the total data. The data is debugged independently at each stage. In-stream processing of data often faced is reprocessing challenges. The input data re-drives output through this process.
In short, the advantages of this architecture are:
- Human error tolerance
- Tolerance in case of a hardware damage.
Disadvantages of Lambda Architecture
Choosing lambda architecture for an enterprise to prepare data lake may have certain disadvantages as well, if certain points are not kept in mind. Some of these points are discussed below:
- Different layers of this architecture may make it complex. Synchronization between the layers can be an expensive affair. So, it has to be handled in a cautious manner.
- Support and maintenance become difficult because of distinct and distributed layers namely batch and speed.
- A lot of technologies have emerged that can help in the construction of Lambda architecture but finding people who have mastered these technologies can be difficult.
- It can be difficult to apply this architecture for the open-source technologies and the trouble further solidifies if it has to be implemented in the cloud.
- Maintenance of the code of the architecture is also difficult. As it has to produce the same results in the distributed system.
- It becomes furthermore difficult to program in a Big Data frameworks like Hadoop and Storm.
An unified approach to Lambda Architecture
As discussed above one of the disadvantages of Lambda architecture is its complexity. It is indeed a maintenance and implementation challenge as one has to synchronize two distributed systems. To avoid these difficulties there can be three alternative approaches as discussed below:
- Use of flexible framework and adoption of the pure streaming approach. For this Apache, Samza can be a good option. It has a pluggable distributed streaming layer and allows a kind of batch processing.
- An approach opposite to the above-discussed point can also be taken. Choosing flexible batches can be a good option as well. Choose batches small enough so that it becomes close to real-time batches. For this Apache Stark or Storm’s Trident can be adopted.
- Combining both real-time process and batch process using stack technology can be another approach. For this Lambda Loop or SummingBird can be good options. In Summingbird batch and instantaneous data work together and the result gets merged as it is a hybrid system. In Lambda Loop also the same kind of approach is followed.
The image given below will give a better understanding of the points discussed above.
The unified approach addresses the velocity and volume problems of Big Data as it uses a hybrid computation model. This model combines both batch data and instantaneous data transparently.
An outline of the architecture
Big data systems works mostly work on raw and partially structured data. The organizations today need system that has the capability to process both batch and real time data. Lambda architecture has the capability to deal with both these processes and in the meantime, it can build immutability into the system.
The architecture has a good set of guidelines and is a technological agonist. Any technology can be applied into it to get the work done as it is composed of various layers. Ready cloud components are also available that can be implemented in lambda architecture.
The architecture can be better said as a pluggable that can be involved whenever a process is in demand. Various data generation sources can be plugged in or plugged out depending on the demand.
Real-time working examples:
Lambda architecture has found it in multiple use cases some of the working examples are discussed below:
- Twitter and Groupon multiple use cases. Lambda architecture is used to understand the sentiment of tweets, so used for sentimental analysis.
- Crashlytics: here it deals particularly with the mobile analysis used to produce meaningful analytical results.
- Stack overflow: it is a well-known forum with huge user base deals with questions and answers. Here batch views are used to find the analytical results for voting.
Conclusion:
Over the years Big data system has become popular. But for the business needs of a company like Google or Facebook, the existing technology was not fit enough. To meet their demand a standardized and flexible architecture was needed that led to the birth of Lambda architecture.
After the implementation of this architecture, proper planning should be done to migrate the data to Data Lake. As the architecture deals with analytics one can make use of the standard transactional database to put the data to the cluster.
Every year more and more companies are migrating towards Big Data.