
Analyzing Data Streaming using Spark vs Kafka

Before we draw a comparison between Spark Streaming and Kafka Streaming and conclude which one to use when, let us first get a fair idea of the basics of Data Streaming: how it emerged, what is streaming, how it operates, its protocols and use cases.
How Data Streaming came into existence?
Data has ever since been an essential part of the operations. Data forms the foundation of the entire operational structure, wherein it is further processed to be used at different entity modules of the system. That is why it has become quintessential in the IT landscape.
As technology grew more substantial, the importance of the data has emerged even more prominently. The methodologies that are used in data processing have evolved significantly to match up with the pace of growing need for data inputs from the software establishments.
As time grew, the time frame of data processing shrank dramatically to an extent where an immediately processed output is expected to fulfill the heightened end-user expectations. With the emergence of Artificial Intelligence, there is a strong desire to provide live assistance to the end user that seems much like humans.
This requirement solely relies on data processing strength. The faster, the better. Thus, as a result, there has been a change brought in the way data processed. Earlier there were batches of inputs that were fed in the system that resulted in the processed data as outputs, after a specified delay.
Currently, this delay (Latency), which is a result of feeding the input, processing time and the output has been one of the main criteria of performance. To ensure high performance, the latency has to be minimum to the extent of almost being real time.
This is how the streaming of data came into existence. In Data Streaming process, the stream of live data is passed as input that has to be immediately processed and deliver a flow of the output information in real time.
What is Data Streaming?
Data Streaming is a method in which input is not sent in the conventional manner of batches, and instead, it is posted in the form of a continuous stream that is processed using algorithms as it is. The output is also retrieved in the form of a continuous data stream.
This data stream is generated using thousands of sources, which send the data simultaneously, in small sizes. These files when sent back to back forms a continuous flow. These could be log files that are sent in a substantial volume for processing.
Such data which comes as a stream has to be sequentially processed to meet the requirements of (almost) continuous real-time data processing.

Why is Data Streaming required?
With the growing online presence of enterprises and subsequently the dependence on the data has brought in, the way data has been perceived. The advent of Data Science and Analytics has led to the processing of data at a massive volume, opening the possibilities of Real-time data analytics, sophisticated data analytics, real-time streaming analytics, and event processing.
Data Streaming is required when the input data is humongous in size. One needs to store the data before we move it for the batch processing. This involves a lot of time and infrastructure as the data is stored in the forms of multiple batches. To avoid all this, information is streamed continuously in the form of small packets for the processing. Data streaming offers hyper scalability that remains a challenge for batch processing.
Another reason, why data streaming is used, is to deliver a near-real-time experience, wherein the end user gets the output stream within a matter of few seconds or milliseconds as they feed in the input data.
Data streaming is also required when the source of the data seems to be endless that cannot be interrupted for the batch processing. IoT sensors contribute to this category, as they generate continuous readings that need to be processed for drawing inferences.
How Data Streaming takes place?
For making immediate decisions by processing data in real-time, data streaming can be done. Depending upon the scale, complexity, fault tolerance and reliability requirements of the system, you can either use a tool or build it yourself.
Building it yourself would mean that you need to place events in a message broker topic such as Kafka before you code the actor. An actor here is a piece of code that is meant to receive events from problems in the broker, which is the data stream, and then publish the output back to the broker.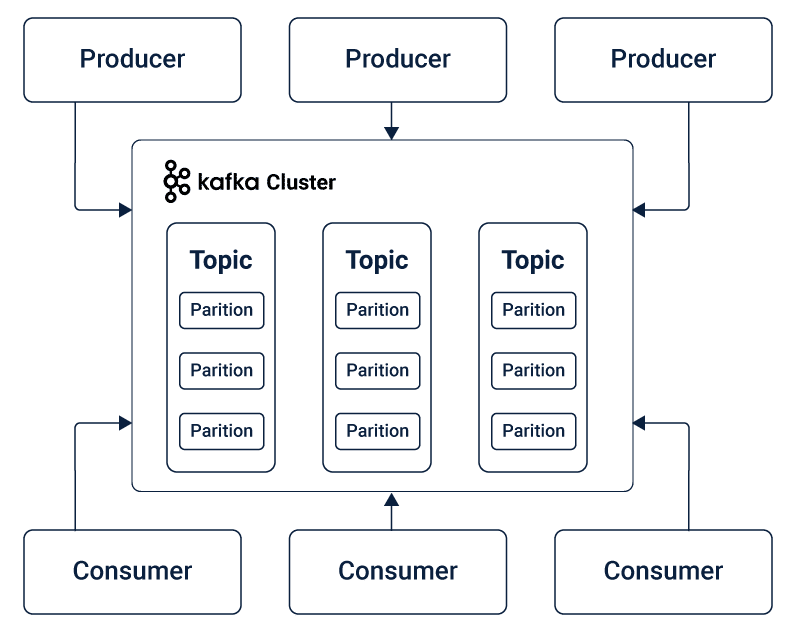
Spark is a first generation Streaming Engine that requires users to write code and place them in actor, and they can further wire these actors together. To avoid this, people often use Streaming SQL for querying, as it enables the users to ask the data easily without writing the code. Streaming SQL is extended support from the SQL to run stream data. Moreover, as SQL is well practiced among the database professionals, performing Streaming SQL queries would be much easier, as it is based on the SQL.
Here’s the streaming SQL code for a use case where an Alert mail has to be sent to the user in an event when the pool temperature falls by 7 Degrees in 2 minutes.
@App:name(“Low Pool Temperature Alert”)
@App: description(‘An application which detects an abnormal decrease in swimming pools temperature.’)
@source(type=’kafka’,@map(type=’json’),bootstrap.servers=’localhost:9092′,topic.list=’inputStream’,group.id=’option_value’,threading.option=’single.thread’)
define stream PoolTemperatureStream(pool string, temperature double);
@sink(type=’email’, @map(type=’text’), ssl.enable=’true’,auth=’true’,content.type=’text/html’, username=’sender.account’, address=’sender.account@gmail.com’,password=’account.password’, subject=”Low Pool Temperature Alert”, to=”receiver.account@gmail.com”)
define stream EmailAlertStream(roomNo string, initialTemperature double, finalTemperature double);
–Capture a pattern where the temperature of a pool decreases by 7 degrees within 2 minutes
@info(name=’query1′)
from every( e1 = PoolTemperatureStream ) -> e2 = PoolTemperatureStream [e1.pool == pool and (e1.temperature + 7.0) >= temperature]
within 2 min
select e1.pool, e1.temperature as initialTemperature, e2.temperature as finalTemperature
insert into EmailAlertStream;
Spark SQL provides DSL (Domain Specific Language) that would help in manipulating DataFrames in different programming languages such as Scala, Java, R, and Python. It lets you perform queries on structured data inside the Spark programs using SQL or DataFrame API.
New generations Streaming Engines such as Kafka too, supports Streaming SQL in the form of Kafka SQL or KSQL.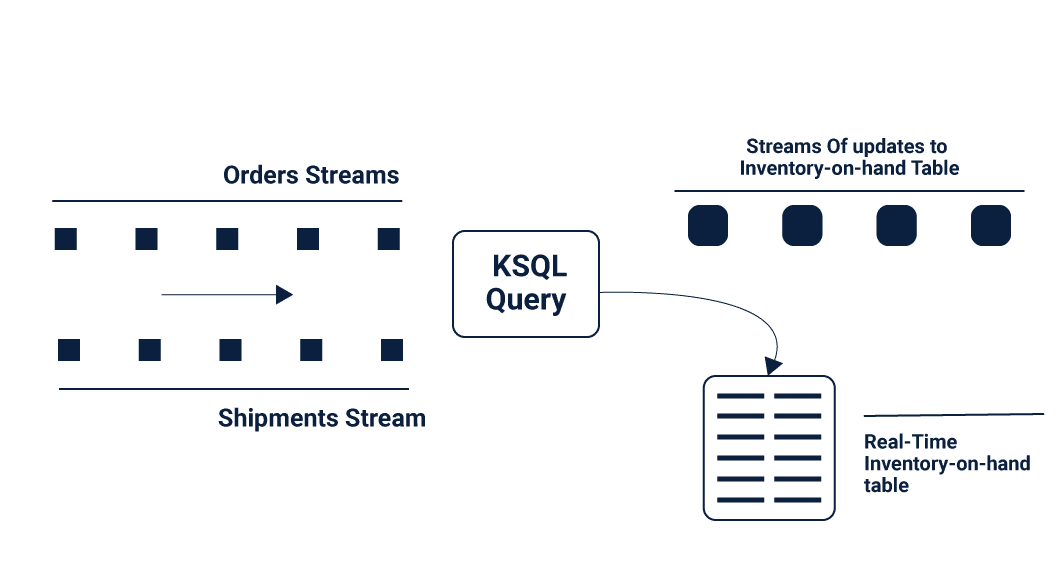
While the process of Stream processing remains more or less the same, what matters here is the choice of the Streaming Engine based on the use case requirements and the available infrastructure.
Before we conclude, when to use Spark Streaming and when to use Kafka Streaming, let us first explore the basics of Spark Streaming and Kafka Streaming to have a better understanding.
What is Spark Streaming?
Spark Streaming, which is an extension of the core Spark API, lets its users perform stream processing of live data streams. It takes data from the sources like Kafka, Flume, Kinesis or TCP sockets. This data can be further processed using complex algorithms that are expressed using high-level functions such as a map, reduce, join and window.
The final output, which is the processed data can be pushed out to destinations such as HDFS filesystems, databases, and live dashboards.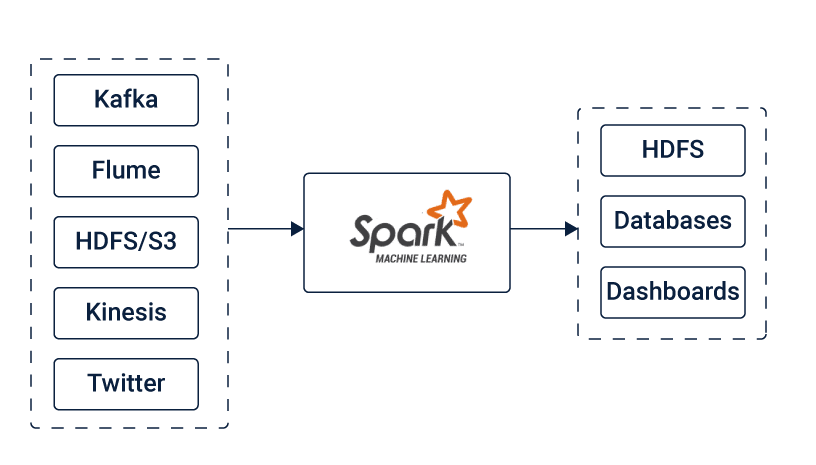
Let us have a closer look at how the Spark Streaming works. Spark Streaming gets live input in the form of data streams from the data sources and further divides it into batches that are then processed by the Spark engine to generate the output in quantities.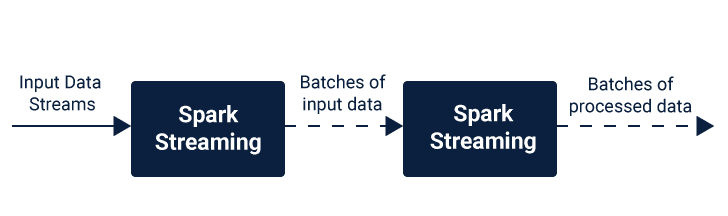
Spark Streaming allows you to use Machine Learning and Graph Processing to the data streams for advanced data processing. It also provides a high-level abstraction that represents a continuous data stream.
This abstraction of the data stream is called discretized stream or DStream. This DStream can either be created from the data streams from the sources such as Kafka, Flume, and Kinesis or other DStreams by applying high-level operations on them.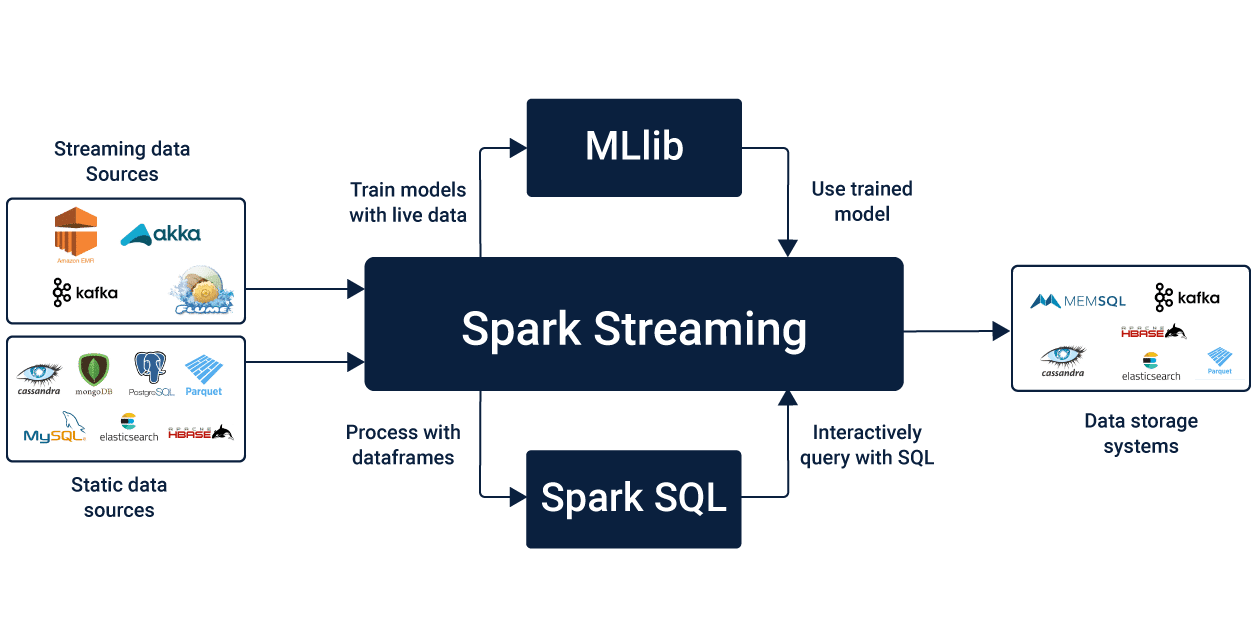
These DStreams are sequences of RDDs (Resilient Distributed Dataset), which is multiple read-only sets of data items that are distributed over a cluster of machines. These RDDs are maintained in a fault tolerant manner, making them highly robust and reliable.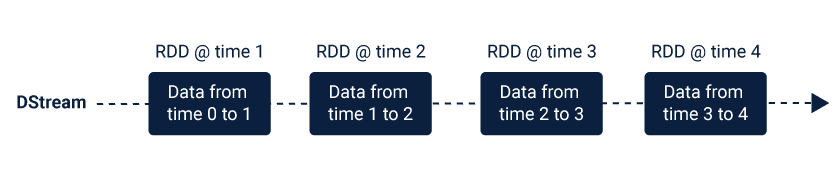 Spark Streaming uses the fast data scheduling capability of Spark Core that performs streaming analytics. The data that is ingested from the sources like Kafka, Flume, Kinesis, etc. in the form of mini-batches, is used to perform RDD transformations required for the data stream processing.
Spark Streaming uses the fast data scheduling capability of Spark Core that performs streaming analytics. The data that is ingested from the sources like Kafka, Flume, Kinesis, etc. in the form of mini-batches, is used to perform RDD transformations required for the data stream processing.
Spark Streaming lets you write programs in Scala, Java or Python to process the data stream (DStreams) as per the requirement. As the same code that is used for the batch processing is used here for stream processing, implementation of Lambda architecture using Spark Streaming, which is a mix of batch and stream processing becomes a lot easier. But this comes at the cost of latency that is equal to the mini batch duration.
Input sources in Spark Streaming
Spark supports primary sources such as file systems and socket connections. On the other hand, it also supports advanced sources such as Kafka, Flume, Kinesis. These excellent sources are available only by adding extra utility classes.
You can link Kafka, Flume, and Kinesis using the following artifacts.
- Kafka: spark-streaming-kafka-0-10_2.12
- Flume: spark-streaming-flume_2.12
- Kinesis: spark-streaming-kinesis-asl_2.12 [Amazon Software License]
What is Kafka Streaming?
Kafka Stream refers to a client library that lets you process and analyzes the data inputs that received from Kafka and sends the outputs either to Kafka or other designated external system. Kafka relies on stream processing concepts such as:
- Accurately distinguishing between event time and processing time
- Windowing Support
- Efficient and straightforward application state management
It simplifies the application development by building on the producer and consumer libraries that are in Kafka to leverage the Kafka native capabilities, making it more straightforward and swift. It is due to this native Kafka potential, that lets Kafka streaming to offer data parallelism, distributed coordination, fault tolerance, and operational simplicity.
The main API in Kafka Streaming is a stream processing DSL (Domain Specific Language) offering multiple high-level operators. These operators include: filter, map, grouping, windowing, aggregation, joins, and the notion of tables.
The messaging layer in the Kafka, partitions data that is further stored and transported. The data is partitioned in the Kafka Streams according to state events for further processing. The topology is scaled by breaking it into multiple tasks, where each task is assigned with a list of partitions (Kafka Topics) from the input stream, offering parallelism and fault tolerance.
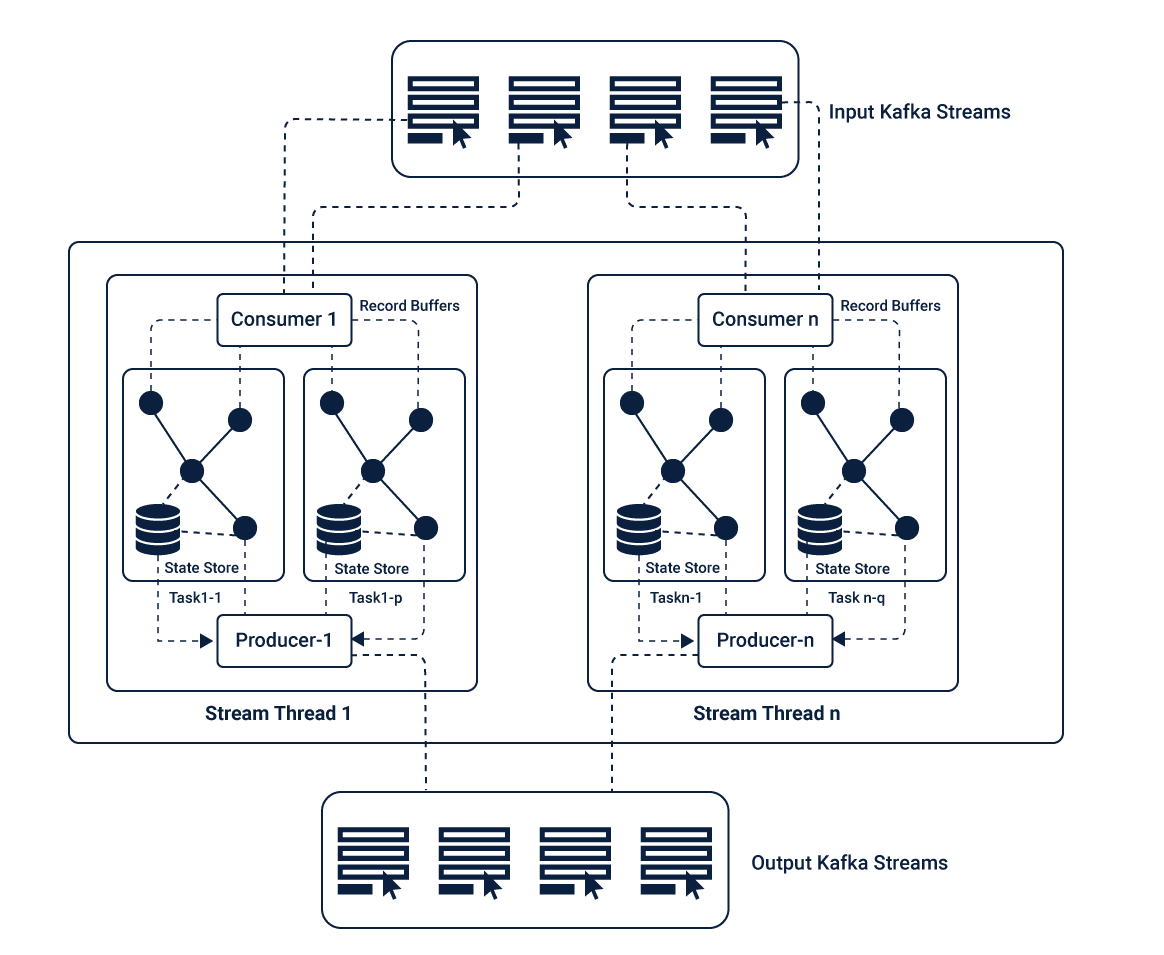 Kafka works on state transitions unlike batches as that in Spark Streaming. It stores the states within its topics, which is used by the stream processing applications for storing and querying of the data. Thereby, all its operations are state-controlled. These states are further used to connect topics to form an event task.
Kafka works on state transitions unlike batches as that in Spark Streaming. It stores the states within its topics, which is used by the stream processing applications for storing and querying of the data. Thereby, all its operations are state-controlled. These states are further used to connect topics to form an event task.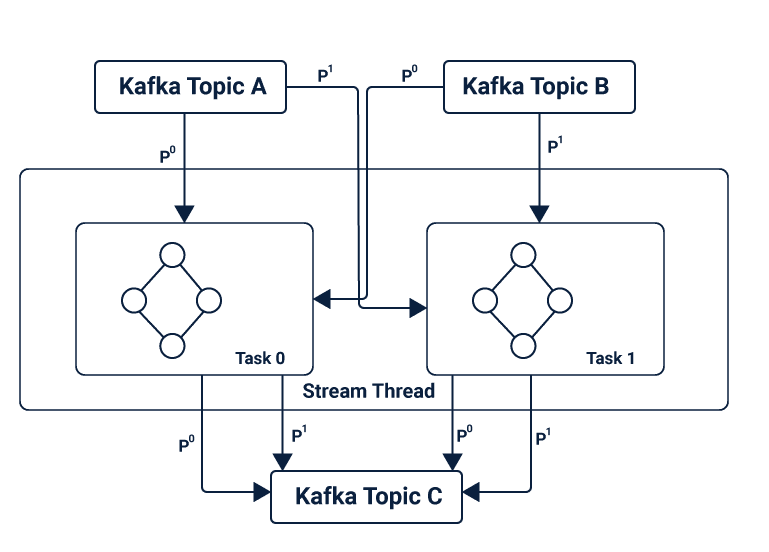
It is due to the state-based operations in Kafka that makes it fault-tolerant and lets the automatic recovery from the local state stores. Data Streams in Kafka Streaming are built using the concept of tables and KStreams, which helps them to provide event time processing.
Spark Streaming vs. Kafka Streaming: When to use what
Spark Streaming offers you the flexibility of choosing any types of system including those with the lambda architecture. But the latency for Spark Streaming ranges from milliseconds to a few seconds.
If latency is not a significant issue and you are looking for flexibility in terms of the source compatibility, then Spark Streaming is the best option to go for. Spark Streaming can be run using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or Kubernetes as well.
It can access data from HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and many other data sources. It offers fault tolerance and offers Hadoop distribution too.
Moreover, you do not have to write multiple codes separately for batch and streaming applications in case Spark streaming, where a single system works for both the conditions.
On the other hand, if latency is a significant concern and one has to stick to real-time processing with time frames shorter than milliseconds then, you must consider Kafka Streaming. Kafka Streaming offers advanced fault tolerance due to its event-driven processing, but compatibility with other types of systems remains a significant concern. Additionally, in cases of high scalability requirements, Kafka suits the best, as it is hyper-scalable.
If you are dealing with a native Kafka to Kafka application (where both input and output data sources are in Kafka), then Kafka streaming is the ideal choice for you.
While Kafka Streaming is available only in Scala and Java, Spark Streaming code can be written in Scala, Python and Java.
On a closing note
As technology grew, data also grew massively with time. The need to process such extensive data and the growing need for processing data in real-time has led to the use of Data Streaming. With several data streaming methods notably Spark Streaming and Kafka Streaming, it becomes essential to understand the use case thoroughly to make the best choice that can suit the requirements optimally.
Prioritizing the requirements in the use cases is very crucial to choose the most suitable Streaming technology. Given the fact, that both the Spark Streaming and Kafka Streaming are highly reliable and widely recommended as the Streaming methods, it largely depends upon the use case and application to ensure the best results.
In this article, we have pointed out the areas of specialization for both the streaming methods to give you a better classification of them, that could help you prioritize and decide better.