
Kafka Streams: Guide to Apache Kafka’s Core

Kafka Streams is a customer library for preparing and investigating data put away in Kafka. It expands upon important stream handling ideas, for example, appropriately recognizing occasion time and developing time, windowing backing, and necessary yet useful administration and constant questioning of utilization states.

What is Kafka Streams?
Kafka Streams gives purported state stores, which can be utilized by stream preparing applications to store and inquire information. A vital ability while actualizing chained and cascading tasks.
Each undertaking in Kafka Streams installs at least one state stores that can be reached employing APIs to store and question information required for preparing.
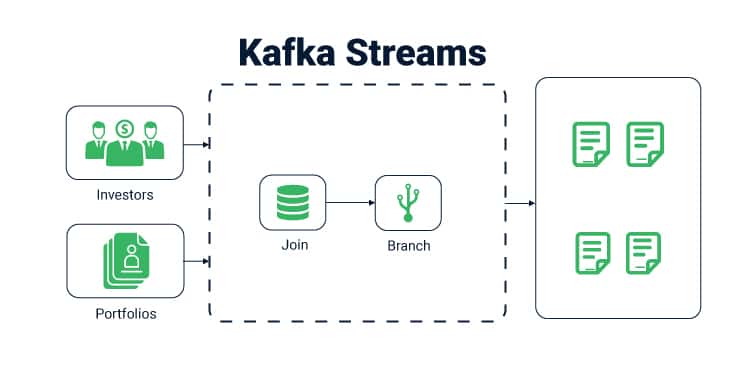
These state stores can either be a persevering key-esteem store, an in-memory hash-map, or another advantageous information structure. Kafka Streams offers adaptation to internal failure and programmed recuperation for neighborhood state stores.
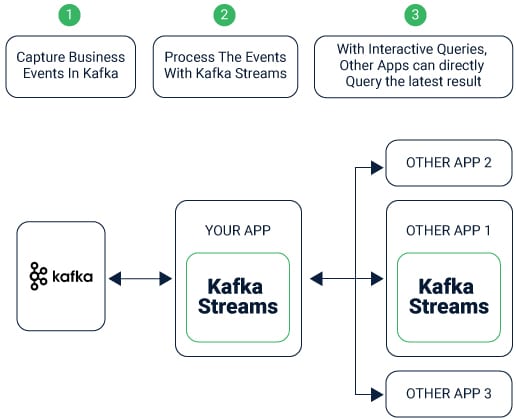
Kafka Streams permits coordinated read-only inquiries of the state stores by strategies, strings, procedures or applications outside to the stream preparing application that made the state stores.
It will be given through a component called Interactive Queries. All stores are named, and Interactive Queries uncovered just the read activities of the fundamental usage.
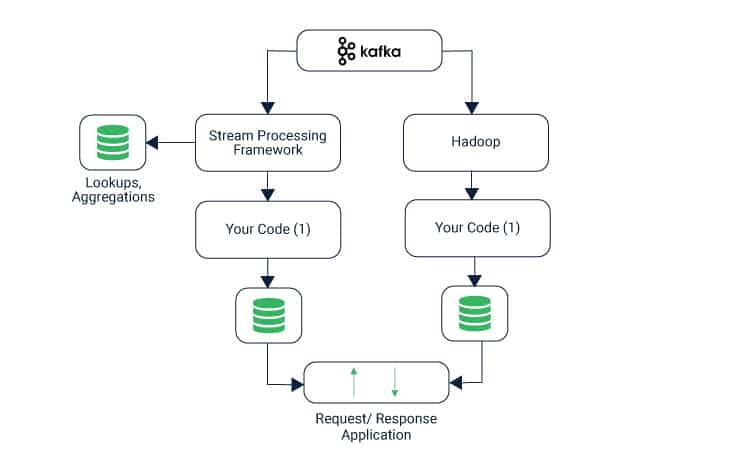
What Kafka Does?
Apache Kafka bolsters an extensive variety of utilization Kafka Streams use cases as a broadly useful data management framework for situations where high throughput, dependable conveyance, and level versatility are imperative. Apache Storm and Apache HBase both work exceptionally well in tandem with Kafka. Typical functions and cases that can be conducted include:
- Stream Processing
- Site Activity Tracking
- Measurements Collection and Monitoring
- Log Aggregation
Kafka Streams have a low hindrance to obstructions and errors.
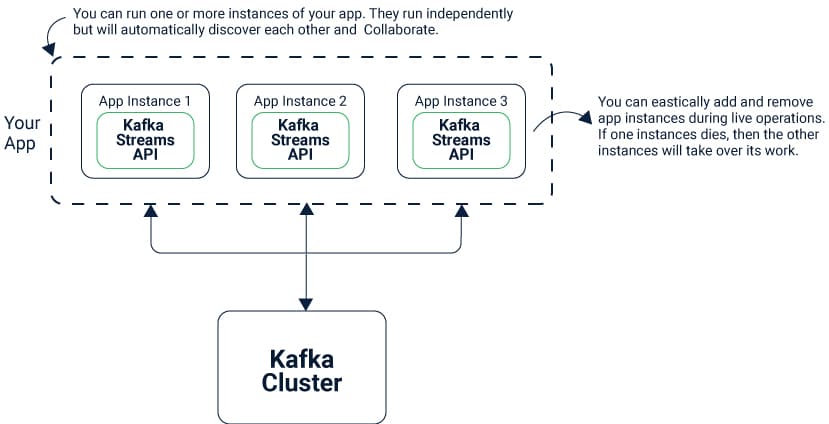
You can rapidly compose and run a little scale confirmations by running extra occasions of your application on different machines to scale up to high-volume generation remaining tasks at hand.
Kafka Streams straightforwardly handles the heap, adjusting various occurrences of a similar application by utilizing Kafka’s unique multitasking functions.
Features of Kafka Streams
Outlined as an essential and lightweight customer library, Kafka Streams can be effectively inserted in any Kafka streams Java application and incorporated with any current bundling. It can be added to any arrangement and operational devices that clients have for their data-centric applications.
- Puts no external conditions on frameworks other than Apache Kafka itself as the inward informing layer.
- It utilizes Kafka’s parceling model on a level plane scale handling while at the same time keeping up steady requesting streams.
- Streams can seamlessly deal with any Kafta streams join operations that are done on the data, which empowers quick and proficient tasks like windowed joins and conglomerations.
- It backs precisely once to prepare semantics to ensure that each record will be handled once and just once notwithstanding when there is an error on either Stream for customers or Kafka intermediaries highly involved with handling.
- Utilizes one-record at any given moment preparing to accomplish millisecond handling inactivity, and backs occasionally based on time-based windowing activities with late entry of records.
- Offers essential stream handling natives, alongside an abnormal state Streams DSL and a low-level Processor API.
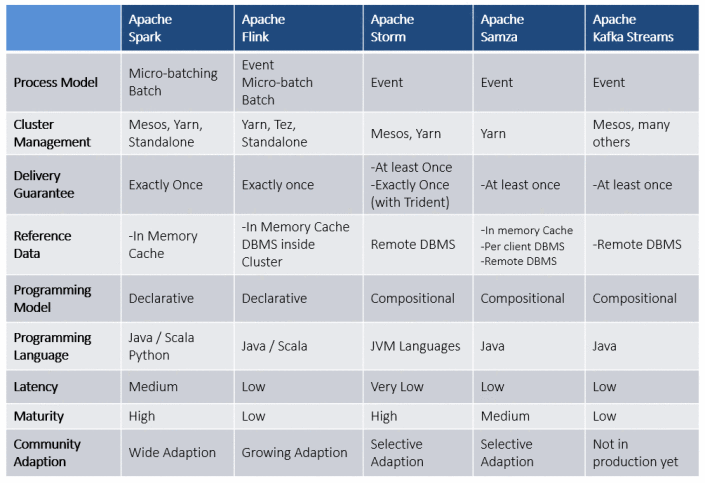 Source: https://dzone.com/articles/features-of-apache-big-data-streaming-frameworks[/caption]
Source: https://dzone.com/articles/features-of-apache-big-data-streaming-frameworks[/caption]
Core and Architecture
Kafka Streams Topology
- A stream is an essential function given by Kafka Streams: it speaks to an unbounded, ceaselessly refreshing informational collection.
- A stream is an arranged, replayable, and blame a tolerant succession of changeless information records, where an information record is characterized as a key-esteem match.
- A stream preparing application is any program that makes utilization of the Kafka Streams library. It portrays its computational rationale through at least one processor topologies, where a processor Kafka Streams topology is a diagram of stream processors (hubs) that are associated by streams (edges). These can exist as a virtual machine on Kafka streams java JVM as well.
- A stream processor is a hub in the processor topology; it speaks to a handling venture to change information in streams by accepting one information record at once from its upstream processors in the topology, applying its activity to it, and may along these lines deliver at least one yield records to its downstream processors.
Processors In the Topology
A source processor is an uncommon kind of stream processor that does not have any upstream processors. It delivers an information stream to its topology from one or various Kafka subjects by expending records from these points and sending them to its down-stream processors.
A sink processor is a different sort of stream processor that does not have down-stream processors. It sends any got records from its up-stream processors to a predetermined Kafka theme.
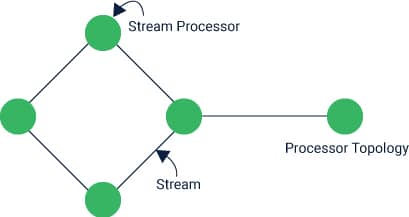
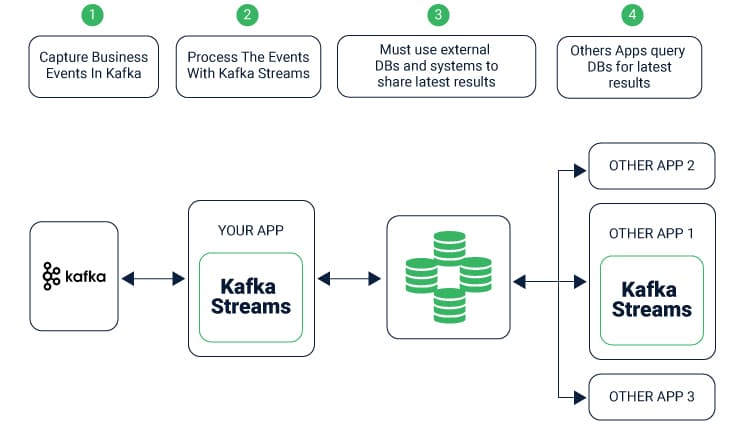
Note that in ordinary processor hubs other remote frameworks can likewise be reached while handling the present record. Consequently, the handled outcomes can either be spilled once again into Kafka or kept in touch with an outer framework.
How Streams Makes Workflow Easier
Kafka Streams offers two different ways to characterize the stream preparing topology that often jumbles the arrangement and handling of data at larger scales.
Kafka Streams DSL gives the most widely recognized information change activities, for example, delineate, Kafka stream join and totals out of the container; the lower-level Processor API permits designers to characterize and associate custom processors and in addition to collaborating with state stores. Similar APIs can be created using a Kafka streams Scala bundle. Kafka streams Scala bundles are often packaged as separate products by providers.
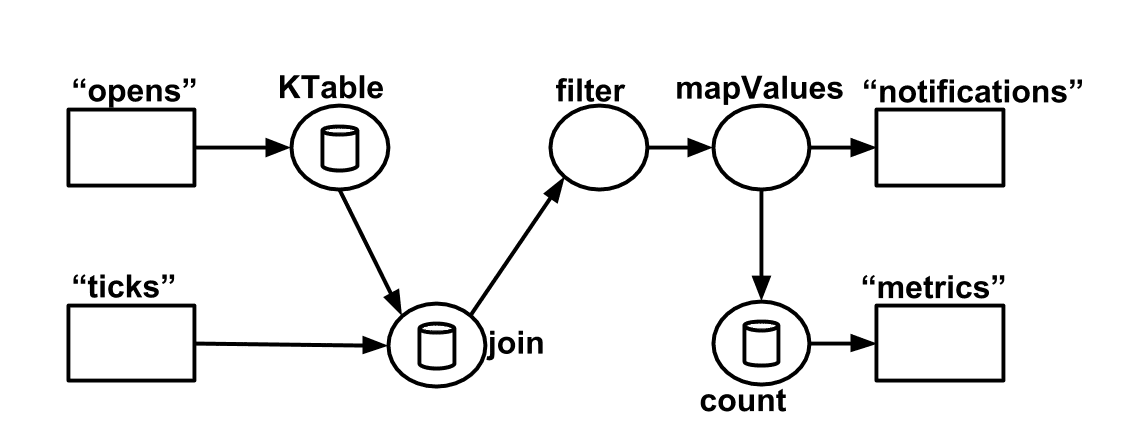
A processor topology merely is a coherent reflection for any stream preparing code. At runtime, the intelligent topology is instantiated and recreated inside the application for parallel computation.
A portion of the critical attributes that make Kafka such an alluring alternative for these utilization cases incorporate the accompanying –
What makes Apache Kafka so useful?
Kafka Streams supports a tightly built framework that eliminates a number of the pesky issues that beguile industries and companies that play around with massive data. It has become a favorite for tech companies mainly due to many factors.
- Versatility
Conveyed framework are scaled effortlessly with no downtime. - Solidness And Memory
Holds on messages on a plate, and gives intra-bunch replication - Unwavering quality
Repeats information underpins different supporters and naturally adjusts purchasers if there should be an occurrence of errors. - Execution
High throughput for both distributing and buying in. - Time
A fundamental viewpoint in stream handling is the thought of the time, and how it is displayed and coordinated. For instance, a few tasks, for example, Kafka streams windowing are characterized because of time limits.
Talking About The Time
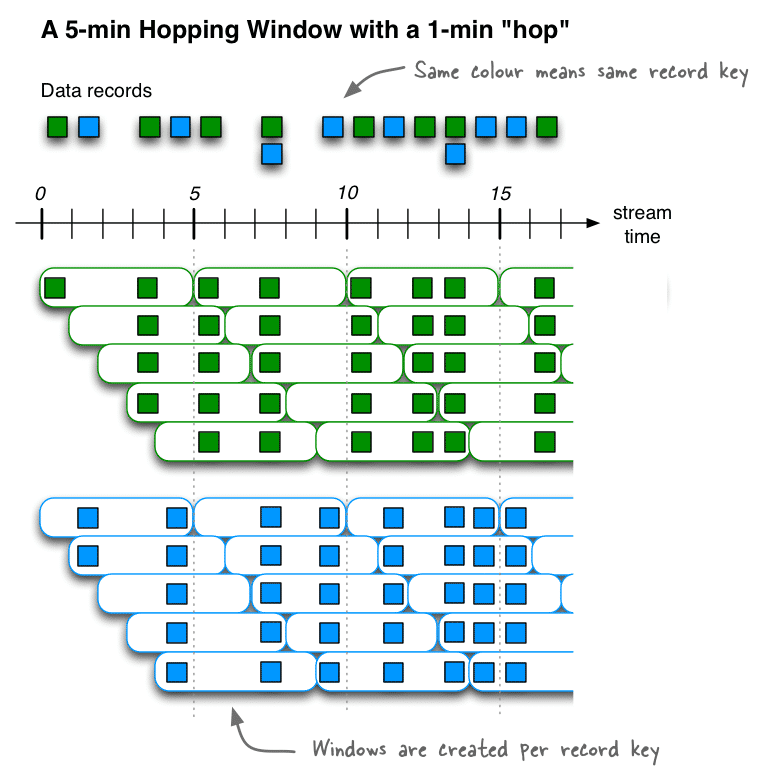
- Occasion Time
The point in time when an occasion or information record happened, i.e., was initially made “at the source” is referred to commonly as the occasion time and is a central idea to Kafka Streams.If the source is a geo-area change revealed by a GPS sensor in an auto, at that point the related occasion time would be the time when the GPS sensor caught the area change. - Handling Time
The point in time when the occasion or information record happens to be prepared by the stream preparing application, i.e., at the point when the record is expanded, is the handling time.The handling time might be milliseconds, hours, or days and so forth later than the first occasion time.Imagine an investigation application that peruses and procedures the geo-area information announced from auto sensors to display it to an administration dashboard.Here, preparing time in the examination application may be milliseconds or seconds (e.g., for continuous pipelines in light of Apache Kafka and Kafka Streams) or hours (e.g., for clump pipelines in light of Apache Hadoop or Apache Kafka streams Spark) after occasion time. - Ingestion timeThe point in time when an occasion or information record is put away in a subject parcel by a Kafka agent is the ingestion time.The distinction to occasion time is that this ingestion timestamp is produced when the record is attached to the actual subject by the Kafka intermediary, not when the record is made “at the source.”The distinction to handling time is that preparing time is the point at which the stream preparing application forms the record. For instance, if a document is not prepared, there is no idea of handling time for it, however despite everything it has an ingestion time.
Craving For Kafka
The decision between occasion time and holding-time is made through the design of Kafka (not Kafka Streams): From Kafka 0.10.x onwards, timestamps are consequently inserted into Kafka messages. Contingent upon Kafka’s design these timestamps speak to occasion time or ingestion-time.
- The particular Kafka design setting can be indicated on the intermediary level or per point. The default timestamp extractor in Kafka Streams will recover these implanted timestamps in its present condition.
- Thus, the powerful time semantics of your application relies upon the successful Kafka design for these implanted timestamps.
- Kafka Streams relegates a timestamp to each datum record through the Timestamp Extractor interface. These per-record timestamps depict the advancement of a stream concerning time and are utilized by time-subordinate tasks, for example, Kafka streams window activities.
Accordingly, this time will propel when another record lands at the processor. We call this information-driven time the stream time of the application to separate with the divider clock time when this application is executing. Substantial usage of the Timestamp Extractor interface will then give different semantics to the stream time definition.
For instance, recovering or figuring timestamps because of the actual substance of information records, for example, an installed timestamp field to give occasion time semantics, and restoring the present divider clock time subsequently yield handling time semantics to stream time. Designers would thus be able to implement diverse ideas of time contingent upon their business needs.
Taking Kafka It A Step Further
At last, at whatever point a Kafka Streams application composes records to Kafka, at that point it will likewise dole out timestamps to these new records. The way the timestamps are allowed relies upon the specific situation:
- At the time when new yield records are produced through handling some information record, for instance, context. Forward () activated all the while() work call, yield record timestamps are acquired from input record timestamps straightforwardly.
- At the point when new yield records are produced using occasional capacities, for example, Punctuator#punctuate(), the yield record timestamp is characterized as the current inner time (acquired through context.timestamp()) of the stream assignment.
- For accumulations, the timestamp of a subsequent total refresh record will be that of the most recent arrived input record that set off the refresh.
Handling User Cases and States
Some stream handling applications don’t require state, which implies the preparing of a message is autonomous from the handling of every other message.
Notwithstanding, having the capacity to keep upstate opens up numerous conceivable outcomes for complex stream preparing applications: you can join input streams, or gathering and total information records. The Kafka Streams DSL gives various administrators.
In-stream handling, a standout question is “does stream preparing framework ensure that each record is prepared once and just once, regardless of whether a few errors are experienced while trying to ?” Failing to ensure precisely once stream process will delineate the entire process against which the framework has multiple layers of protection.
These layers ensure that processing occurs smoothly even in the case when things turn bizarre which is rarely common in such an advanced system.
What The Kafka Streams API Is Made Of?
The Kafka Streams API enables you to make ongoing applications that power your center business. It is the simplest to utilize the most ground-breaking innovation yet to process information put away in Kafka. It gives business the use of standard classes of Kafka.
A distinctive element of the Kafka Streams API is that the applications you work with it are typical applications.
These applications can be bundled, sent, and observed like some other application, with no compelling reason to introduce external groups or unnecessary third-party add-ons.
- Abnormal state DSL
- Abnormal state DSL contains officially actualized strategies prepared to utilize classes and cases. It is made out of two fundamental components: KStream and Kafka Streams KTable or Global KTable
- KStream
- A KStream is a reflection of record stream where every datum is a vital key esteem combine in the unbounded dataset. It gives numerous useful approaches to control stream information like an outline, mapValue, Kafka Streams flatMap, Kafka Streams flatMapValues, and Kafka Streams Ktable.
- It additionally gives joining strategies for joining different streams and collection techniques on stream information.
- KTable or GlobalKTable
- A KTable is a deliberation of a changelog stream.
- In this changelog, each datum record is viewed as an Insert or Update (Upsert) contingent on the presence of the key as any current column with a similar key will be overwritten.
- Processor API
- The low-level Processor API gives a customer to get to stream information and to play out business rationale on the approaching information stream and send the outcome as the downstream information.
- It is done through broadening the unique class AbstractProcessor and superseding the procedure strategy which contains the class strategies.
- This procedure strategy is called once for each key-esteem combine.
- Where the abnormal state Kafka streams DSL furnishes prepared to utilize techniques with useful style, the low-level processor API gives the adaptability to actualize handling rationale as indicated by the company’s needs.
- The trade-off is only the lines of code to be composed for particular situations thus making Kafka Streams DSL important to the final functional capabilities
- Commands for python can be entered through the Kafka streams terminal which makes it more user-friendly without complex coding required for execution.
Final Words
Kafka Streams is a quick, adaptable and error-free framework.
It is regularly utilized instead of conventional message agents like JMS and AMQP because of its higher throughput, consistent quality, and replication.
Kafka works in the mix with Apache Storm, Apache HBase and Apache Kafka stream Spark for regular examination and rendering of enormous information.
Kafka can message geospatial information from an armada of whole deal trucks or sensor information from warming and cooling hardware in places of business.
Whatever the business or project case, Kafka dealers monstrous message streams for low-dormancy examination in Enterprise Apache Hadoop.
It has become a powerful tool in the industry and commands a much broader front by being a common applicator by companies such as Apple, Yelp, Netflix, eBay, Amazon, and even Paypal. Indeed a great custom software to eliminate the common ‘Kafkaesque’ issues of streamlining and processing information.