
Data Lake & Hadoop : How can they power your Analytics?

How can a combination of Data Lake and Hadoop power Analytics?
Powering analytics through a data lake and Hadoop is one of the most effective ways to increase ROI. It’s also an effective way to ensure that the analytics team has all the right information moving forward. There are many challenges that research teams have to face regularly, and Hadoop can aid in effective data management.
From storage to analysis, Hadoop can provide the necessary framework to enable research teams to do their work. Hadoop is also not confined to any single model of working or any only language. That’s why it’s a useful tool when it comes to scaling up. Since companies can perform greater research, there is more data generated. The data can be fed back into the system to create unique results for the final objective.
Data lakes are essential to maintaining as well. Since the core data lake enables your organization to scale, it’s necessary to have a single repository of all enterprise data. Over 90% of the world’s data has been generated over the last few years, and data lakes have been a positive force in the space.
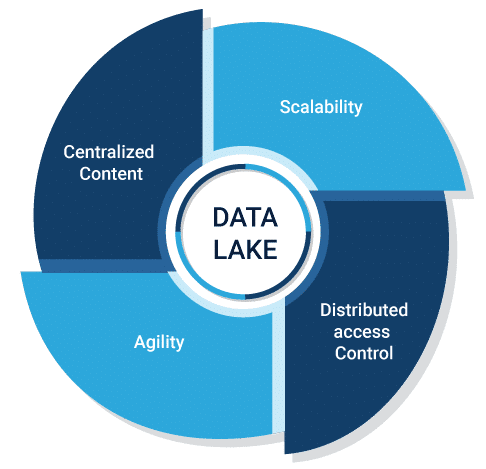
Why Hadoop is effective?
From a research stand-point, Hadoop is useful in more ways than one. It runs on a cluster of commodity servers and can scale up support thousands of nodes. This means that the quantity of data being handled is massive, and many data sources can be treated at the same time. This increases the effectiveness of Big Data, especially in the cases of IoT, Artificial intelligence, Machine Learning, and other new technologies.
It also provides rapid data access across the nodes in the cluster. Users can get an authorized access to a large subset of the data or the entire database. This makes the job of the researcher and the admin that much easier. Hadoop can also be scaled up as the requirement increases over time.
If an individual node fails, the entire cluster can take over. That’s the best part about Hadoop and why companies across the world use it for their research activities. Hadoop is being redefined year over year and has been an industry standard for decades now. Its full potential can be discovered best in the research and analytics space with data lakes.
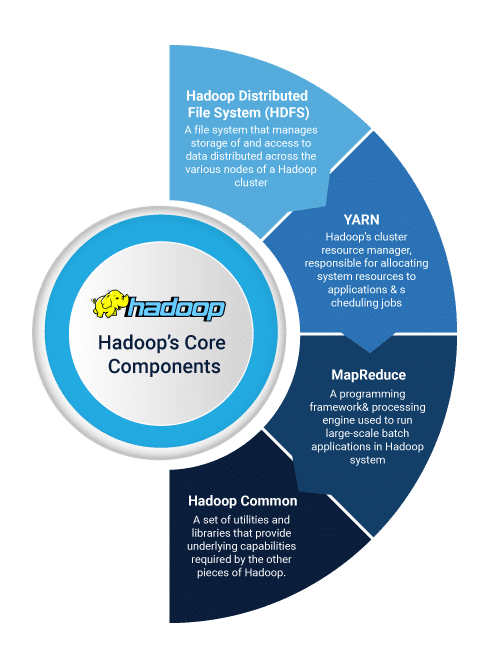
HDFS – The Hadoop Distributed File System (HDFS) is the primary storage system that Hadoop employs, using a NameNode and DataNode architecture. It provides higher performance across the board and acts as a data distribution system for the enterprise.
YARN – YARN is the cluster resource manager that allocates system resources to apps and jobs. This simplifies the process of mapping out the adequate resources necessary. It’s one of the core components within the Hadoop infrastructure and schedules tasks around the nodes.
MapReduce – It’s a highly effective framework that converts data into a more simple set with individual elements broken down into tuples. From here, the data is translated into games and efficiencies are created within the data network. This is an excellent component for making sense of large data sets within the research space.
Hadoop Common – The common is a collection of standard utilities and libraries that support other modules. It’s a core component of the Hadoop framework and ensures that the resources are allocated correctly. They also provide a framework for the processing of data and information.
Hadoop and Big Data Research
Hadoop is highly effective when it comes to Big Data. This is because there are greater advantages associated with using the technology to it’s fullest potential. Researchers can access a higher tier of information and leverage insights based on Hadoop resources. Hadoop can also enable better processing of data, across various systems and platforms.
Anytime there are complex calculations to be done and difficult simulations to execute, Hadoop needs to be put in place. Hadoop can help parallel computation across various coding environments to enable Big Data to create novel insights. Otherwise, there may be overlaps in processing, and the architecture could fail to produce ideas.
From a BI perspective, Hadoop is crucial. This is because while researchers can produce raw data over a significant period, it’s essential to have streamlined access to it. Additionally, from a business perspective, it’s necessary to have strengths in Big Data processing and storage. The availability of data is as important as access to it. This increases the load on the server, and a comprehensive architecture is required to process the information.
That’s where Hadoop comes in. Hadoop can enable better processing and handling of the data being produced. It can also integrate different systems into a single data lake foundation. Added to that, Hadoop can enable better configuration across the enterprise architecture. Hadoop can take raw data and convert it into more useful insights. Anytime there is complexities and challenges, Hadoop can provide more clarity.
Hadoop is also a more enhanced version of simple data management tools. Hadoop can take raw data and insight and present it in a more consumable format. From here, researchers can make their conclusions and prepare intelligence reports that signify results. They can also accumulate on-going research data and feed it back into the central system. This makes for greater on-going analysis, while Hadoop becomes the framework to accomplish it on.
Security on Hadoop and Implementing Data Lakes
There are a significant number of attacks on big data warehouses and data lakes on an on-going basis. It’s essential to have an infrastructure that has a steady security feature built-in. This is where Hadoop comes in. Hadoop can provide those necessary security tools and allow for more secure data transitions.
In the healthcare space, data is critical to preserving. If patient data leaks out, it could lead to complications and health scares. Additionally, in the financial services domain, if data on credit card information and customer SSN leaks out, then there is a legal and PR problem on the rise. That’s why companies opt for greater control using the Hadoop infrastructure. Hadoop is also beneficial regarding providing a better framework for cybersecurity and interoperability. Data integrity is preserved throughout the network, and there is increased control via dashboards provided.
From issuing Kerberos to introducing physical authentication, the Hadoop cluster is increasingly useful in its operations. There is an additional layer of security built into the group, giving rise to a more consistent database environment. Individual tickets can be granted on the Kerberos framework and users can get authenticated using the module.
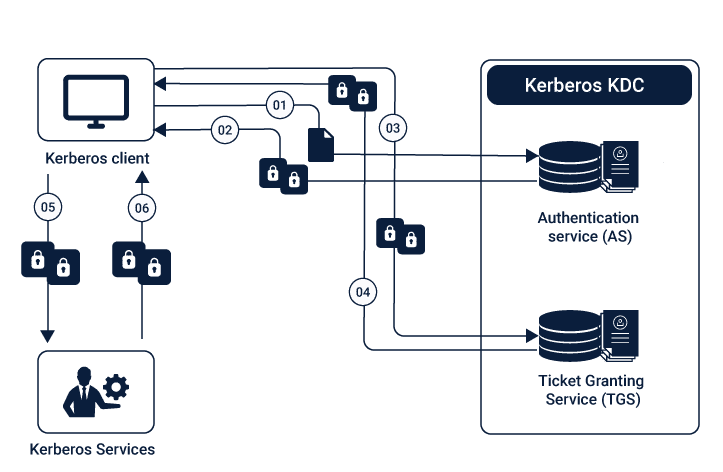
Security can be enhanced by working with third-party developers to improve your overall Hadoop and Data lake security. You can also increase the security parameters around the infrastructure by creating a stricter authentication and user-management portal and policy. From a cyber-compliance perspective, it’s a better mechanism to work through at scale.
Apache Ranger is also a useful tool to monitor the flow of data as well. This is increasingly important when performing research on proprietary data in the company. Healthcare companies know all too well the value of data, which is why the Ranger can monitor the flow of data throughout the organization. Apache YARN has enabled an exact Data lake approach when it comes to information architecture.
That’s why the Ranger is effective in maintaining security. The protocol can be set at the admin level, and companies can design the right tool to take their research ahead. The Ranger can also serve as the end-point management system for when different devices connect onto the cluster.
The Apache Ranger is also a handy centralized interface. This gives greater control to researchers, and all stakeholders in the research and analytics space are empowered. Use-cases emerge much cleaner when there is smooth handling of all data. There is also a more systematic approach to analytics, as there is an access terminal of all authorized personnel. Certain tiers of researchers can gain access to certain types of data and others can get a broader data overview. This can help streamline the data management process and make the analytics process that much more effective.
The Ranger serves as a visa processing system that gives access based on the required authorization. This means that junior researchers don’t get access to highly classified information. Senior level researchers can gain the right amount of insight into the matter at hand and dig deep into core research data. Additionally, analysts can gain access to the data they’ve been authorized to use.
This enables researchers to use Hadoop as an authorization management portal as well. Data can be back-tracked to figure out who used the data portal last. The entire cluster can become unavailable to increase security against outsiders. However, when researchers want a second opinion, they can turn towards consultants who can gain tertiary access to the portal.
Recognizing the analytics needs of researchers and data scientists
It’s important for researchers to understand the need for analytics and vice versa. Hadoop provides that critical interface connect disconnected points in the research ecosystem. Additionally, it creates a more collaborative environment within the data research framework.
Healthcare, Fintech, Consumer Goods and Media & Research companies need to have a more analytical approach when conducting research. That’s why Hadoop becomes critical to leverage, as it creates a more robust environment. The analytics needs are fully recognized by Hadoop, providing more tools for greater analytics.
For forming the right data lake, there needs to be a search engine in place. This helps in streamlining the data and adding a layer of analysis to the raw information. Additionally, researchers can retrieve specific information through the portal. They’re able to perform more excellent analysis of core data that is readily available to them.
Data scientists can uncover accurate insights when they’re able to analyze larger data sets. With emerging technologies like Spark and HBase, Hadoop becomes that much more advanced as an analytics tool. There are more significant advantages to operating with Hadoop and data scientists can see more meaningful results. Over time, there is more convergence with unique data management platforms providing a more coherent approach to data.
The analysis is fully recognized over Hadoop, owing to its scale and scope of work. Hadoop can become the first Data lake ecosystem, as it has a broad range within multiple applications. There is also greater emphasis given to the integrity of data, which is what all researchers need. From core principles to new technology additions, there are components within Hadoop that make it that much more reliable.
Democratizing data for Researchers & Scientists
Having free access to data within the framework is essential. Hadoop helps in developing that democratic data structure within the network. Forecasting to trend analysis can be made that much more straightforward, with a more democratic approach to data. Data can be indeed sorted and retrieved based on the access provided.
Data can also be shared with resources to enable a more collaborative environment in the research process. Otherwise, data sets may get muddied as more inputs stream into the data lake. The lake needs to have a robust democratized approach so that researchers can gain access to that when needed. Additionally, it’s essential to have more streamlined access to the data, which is another advantage of using Hadoop. Researchers need to deploy the technology at scale to obtain benefits that come along with it.
Data scientists can also acquire cleaner data that is error-free. This is increasingly important when researchers want to present their findings to stakeholders as there is no problem with integrity. The democratization of data ensures that everyone has access to the data sets that they’re authorized to understand. Outsiders may not gain access and can be removed from the overall architecture.
Scientists can also study some aspects of the data lake and acquire unique insights that come with it. From a healthcare perspective, a single outbreak or an exceptional case can bring in new ideas that weren’t previously there before. This also adds immense value to distributed instances wherein there is no single source identified. Unique participants can explore the data like and uncover what is required from it.
It’s essential to have a more democratic approach when it comes to data integrity and data lake development. When the data lake is well maintained, it creates more opportunities for analysis within the research space. Researchers can be assured that their data is being presented in the best light possible. They can also uncover hidden trends and new insights based on that initial connection. The information is also sorted and classified better, using Hadoop’s extensive line of solutions and tools built-in.
Researchers have an affinity for using Hadoop, owing to its scale-readiness and great solution base. They can also be used to present information via other platforms, providing it with a more democratic outlook. The data can also be transmitted and shared via compatible platforms across the board. The researchers present within the ecosystem can even compile data that is based on your initial findings. This helps in maintaining a clean record and a leaner model of data exploration.
Benefits & Challenges of Hadoop for enterprise analysis
Hadoop is one of the most excellent solutions in the marketplace for extensive research and enterprise adoption. This is because of its scale and tools available to accomplish complex tasks. Researchers can also leverage the core technology to avail its benefits across a wide range of solution models.
The data can also be shared from one platform to another, creating a community data lake wherein different participants can emerge. However, overall integrity is maintained throughout the ecosystem. This enables better communication within the system, giving rise to an enhanced approach to systems management.
Hadoop benefits the research community in the four main data formats –
Core research information – This is data produced during trials, research tests and any algorithms that may be running on Machine Learning or Artificial Intelligence. This also includes raw information that is shared with another resource. It also provides information that can be presented across the board.
Manufacturing and batches – This data is essential to maintain as it aids in proper verification of any tools or products being implemented. It also helps in the check of process owners and supplies chain leads.
Customer care – For enterprise-level adoption, customer care information must be presented and stored effectively.
Public records – Security is vital when it comes to handling public records. This is why Hadoop is used to provide security measures adequately.
One of the main problems with Hadoop is leveraging massive data sets to one detailed insight. Since Hadoop requires the right talent to uncover insights, it becomes a complicated procedure. Owing to its complexities it also needs better compliance frameworks that can define specific rules based on instances.
Additionally, as Hadoop is scaled up, there are challenges with storage and space management. That’s why cloud computing is emerging as a viable solution to prevent data loss due to storage errors. Hadoop is also facing complexities regarding data synchronization. That’s why researchers need to ensure that all systems are compliant with Hadoop and can leverage the scope of the core platform. For best results, it’s ideal to have a more holistic approach to Hadoop.
Conclusion
With the vast quantities of data being generated every day, there is a need for greater analytics and insight in the research space. While every industry, from Healthcare to Automobile, relies on data in some form, it’s essential to have a logical research architecture built into the system. Otherwise, there may be data inefficiencies and chances of the data lake getting contaminated. It’s best to opt for a hybrid Hadoop model with proper security and networking capabilities. When it comes to performing accurate research, it’s essential to have all the right tools with you.