
IoT Architecture: How To Build A Scalable Architecture

Building a scalable structure for the mainframe architecture in most IT spheres involves a more directive approach in working out the kinks and formulating a unique plan. Such an architecture plan should incorporate the opinions and suggestions of all significant stakeholders before being executed at larger scales.
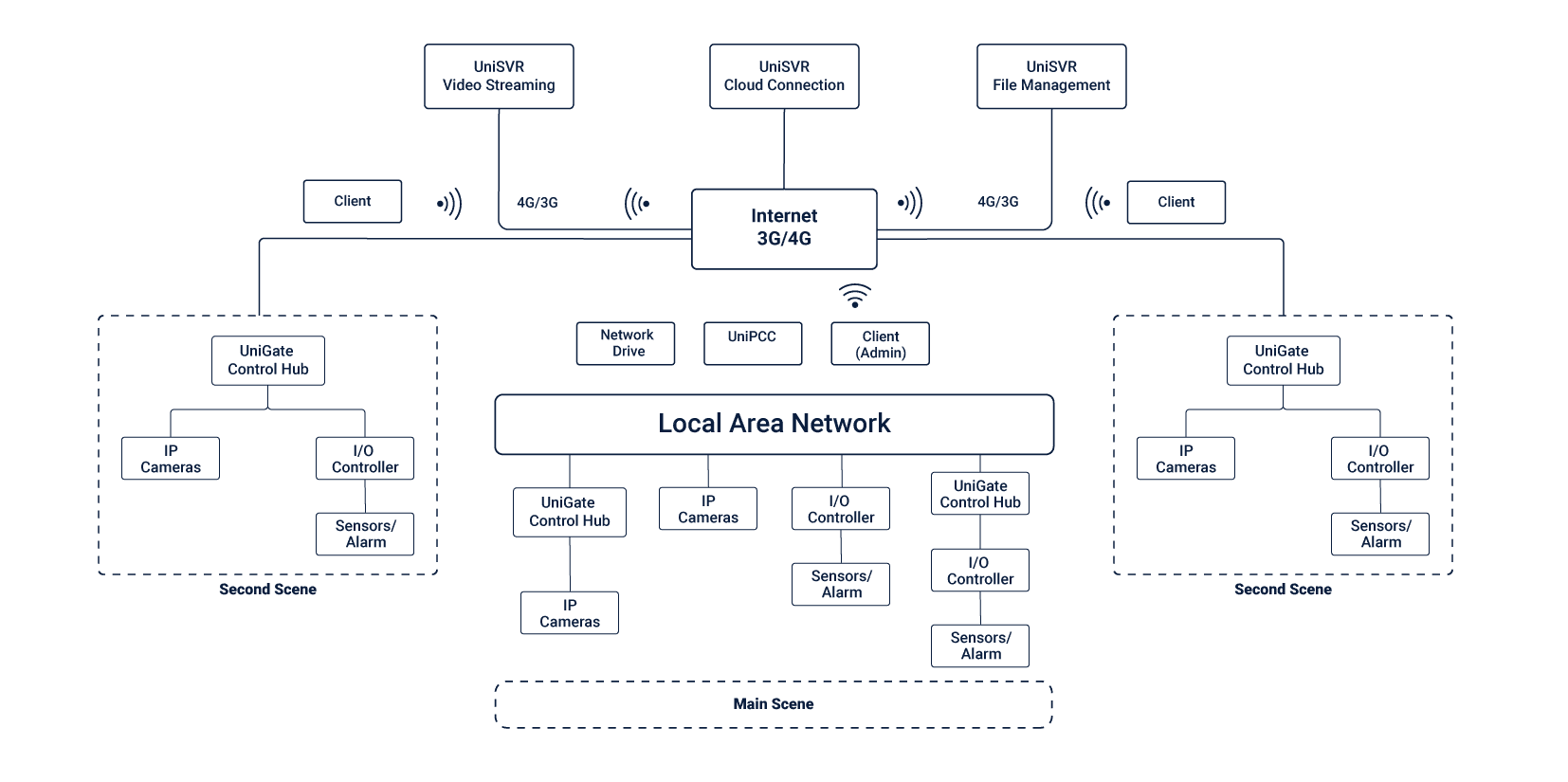
So how does a company go about building a scalable architecture from ground zero? It starts by getting everyone together and creating a thorough breakdown of what to do with the company’s IT holdings.
Starting From The Basics
- The first and foremost thing to do is to design for scale reliably from day one. All IoT systems are supposed to deal with a massive barrage of data grasped by sensors and sources from the company’s data routes.
- There’s always a chance of data coming in due to a sudden growth in clients, business groups or simply online consumers. Such a system is not supposed to stay idle but instead take up any requests, regardless of the traffic.
- While taking care of the scalability aspects, the IoT system should also make sure that the data received is reliably processed. The objective here thus should be to buffer as much data as possible while ensuring reliability.
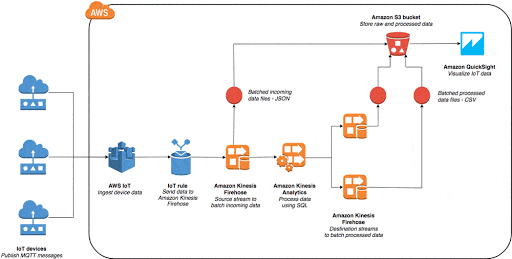
- Use any AWS IoT rules to route large data volumes into the rest of AWS. Amazon web services are a pretty huge deal in the industry right now because of the multitude of features they have. AWS allows for data to be inputted from some streams without any faults or errors that may prevent the system from reaching full sufficiency. The AWS IoT Rules Engine is a great tool to connect the external endpoints to the IoT Core.
- Additionally, AWS IoT Rules Engine takes part in the triggering of multiple different actions in parallel once the IoT system captures the data streams. IoT architecture firms can thus store various datasets simultaneously.
- Always invest in automated devices that controls primary devices together. As the IoT system grows through the company, the smart IoT devices tend to increase as well. Manual processes thus become easier such as device provisioning, security setups, bootstrapping. This ultimately reduces the human interactions involved to cut down on time and money.
- Companies must also deal with managing the IoT data pipelines to make good sense out of them and investing in a scalable building tool like Intel’s data platform or Eclipse empowered by Azure.
- Architects should also keep in mind that not all data may be required for the processing stage in IoT which is where the need for filtering inputs become necessary. Architects should thus stick to keeping the data type specific to the pipeline during the design phase.
- Teams should start building on custom software components by making sure that they don’t turn into bottlenecks that affect the final results. Additionally, they must accommodate system expansions easily.
- Due to the sheer volume of data being used to process in any architecture, it’s never a good idea to store all the information in a single data store or data repository. Keep in mind that different types of data sets may not go well together in the same stream so look for multiple sources.
- For filtering and storage techniques, steps can be facilitated by using AWS Greengrass. Teams can select unnecessary data that is not required by the system immediately and build around this to accept the data in smaller packets promptly. Cloud integrations are a must as well.
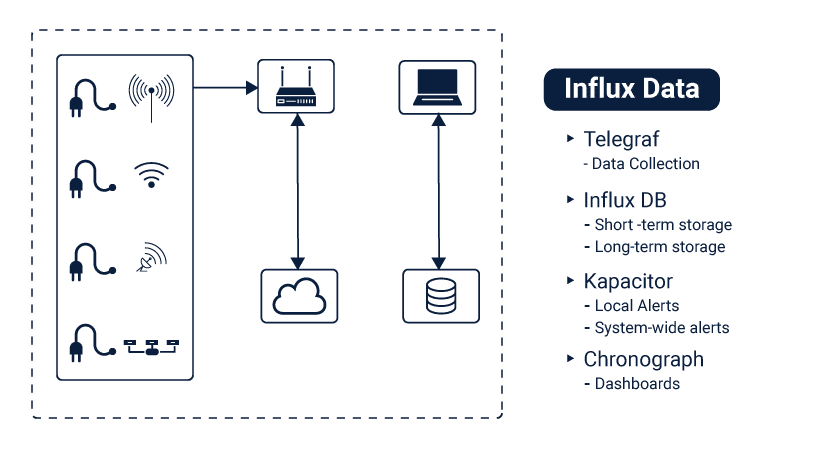
Some Tools To Use
- MACHINNA.io
- This IoT platform has a web-enabled, modular and extensible JavaScript that uses a C++ runtime environment for developing IoT gateway applications.
- DeviceHive
- DeviceHive is another IoT setup that uses a feature-rich open source platform that is currently distributed under the Apache 2.0 license.
- It’s free to use, edit and change with compatibilities available for some system platforms.
- Distributed Services Architecture
- Users would love DSA for their simple design use and how many separate devices can be connected without many complications.
- The applications are structured to deal with real-time data modelling while also facilitating decentralised device inter-communication for logic and applications.
- KAA IoT
- Kaa IoT is undoubtedly one of the most efficient and open source Internet of Things cloud platform that allows teams to bring their smart product concepts to reality.
- KAA IoT has features for both consoles is driven commands and more straightforward drag and drop architectures for new users.
- The IoT platform has a bundle of add-ons and tools that makes scalability a lot simpler when compared to other softwares for IoT architectures.
- Eclipse
- A commonly used platform popular amongst the JAVA community with easy cross-compatibility for Windows and Android devices.
- This IoT platform is built around the java/OSGi based Kura API container. It also uses the aggregation platform for M2M applications running on service gateways.
- ThingSpeak
- An excellent tool for the MATLAB crowd that loves combining cloud-based approaches to leveraging IoT data.
- ThingSpeak is another IoT platform that lets you analyse and visualise the data even for devices that are nonfunctioning in the mainframe.
Tips for Scaling IoT on Other Devices
- The web and mobile interfaces are usually the first stop for developers for IoT solutions due to the number of people who interact with them. One particular approach to building web and mobile apps is to use a standard API for both, rather than scattering the workloads on separate systems.
- This is done to cut down on redundant code that helps separate the API from the web applications, often executed through Single Page Applications.
- Since APIs are heavily tasked from both web app and mobile app users, it will likely be the first place a load balancer, and parallel servers will be required. This also helps eliminate problems of buggy UI on web platforms and user interfaces.
- Scalable IoT systems should use separate systems called web workers where the pool can dynamically grow for data storage and analysis.
- IoT infrastructures become more scalable if the communication stack from the end devices to the cloud are made asynchronous, so that load times are cut down.
- Asynchronous message paths help in increasing the scale to which data can be accepted and how the communication protocols receive and generate queries, either through MQTT or messages.
- Companies are also becoming more aware of terms such as Edge computing and Fog computing where the computational tasks are all aligned to servers at the edge or intermediate stages (like internet gateways). This is a shift from the conventional model where large clusters carry out cloud services.
- Concurrency is another major area where multiple tasks are performed simultaneously with shared resources. Companies should also consider creating setups for running parallelisation runs where a single function is further cut short to some various independent tasks taking place at the same simultaneously.
- System distribution about the tasks should occur on independent servers that ultimately run like a single hive. Distributed systems offer great scalability and high availability by adding more servers.
Simple Principles To Keep In Mind
- Ensure that the design works primarily in the face of significant scaled changes such as the scale changing by 5 or 10 times in a short period.
- Keep away from using any bleeding edge technologies and optimise the design to include the most critical tasks first in the workload.
- While there are several kinds of scalability options available, horizontal scalability should be the preferred schema.
- Always leverage other items in the scalability such as commodity systems, cloud, cache servers and so on.
- If the team is running on a budget, then performing I/O operations should be avoided due to the expense occurred in standard processes for input and output. Transactions as well are costly.
- Use back of the envelope calculations to select the best design.
Building Scalable Systems On DC/OS
The following is a simple sample code for scaling architectures using the MQTT algorithm(for device scalability) coupled with the Eclipse Paho Python library. Details such as the name of the gates along with the access names of the user(username and password) are established way before the Arduino sensor kit is linked to the mainframe:-
#!/usr/bin/env python
MQTT generator
import random
import time
import uuid
import json
from argparse import ArgumentParser
import paho.mqtt.client as mqtt
parser = ArgumentParser()
parser.add_argument(“-b”, “–broker”, dest=”broker_address”,
required=True, help=”MQTT broker address”)
parser.add_argument(“-p”, “–port”, dest=”broker_port”, default=1883, help=”MQTT broker port”)
parser.add_argument(“-r”, “–rate”, dest=”sample_rate”, default=5, help=”Sample rate”)
parser.add_argument(“-q”, “–qos”, dest=”qos”, default=0, help=”MQTT QOS”)
args = parser.parse_args()
uuid = str(uuid.uuid4())
topic = “device/%s” % uuid
mqttc = mqtt.Client(uuid, False)
mqttc.connect(args.broker_address, args.broker_port)
while True:
rand = random.randint(20,30)
msg = {
‘uuid’: uuid,
‘value’: rand
}
mqttc.publish(topic, payload=json.dumps(msg), qos=args.qos)
time.sleep(float(args.sample_rate))
mqttc.loop_forever()
Creating a docker file:-
$ pip freeze > requirements.txt
$ cat requirements.txt
paho-mqtt==1.3.1
$ cat Dockerfile
FROM python:2
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install –no-cache-dir -r requirements.txt
COPY device.py .
CMD [ “/bin/bash” ]
Build a Docker image
$ docker build -t device .
Sending build context to Docker daemon 12.78MB
Step 1/6 : FROM python:2
2: Pulling from library/python
0bd44ff9c2cf: Pull complete
047670ddbd2a: Pull complete
ea7d5dc89438: Pull complete
ae7ad5906a75: Pull complete
0f2ddfdfc7d1: Pull complete
85124268af27: Pull complete
1be236abd831: Pull complete
fe14cb9cb76d: Pull complete
cb05686b397d: Pull complete
Digest: sha256:c45600ff303d92e999ec8bd036678676e32232054bc930398da092f876c5e356
Status: Downloaded newer image for python:2
—> 0fcc7acd124b
Step 2/6 : WORKDIR /usr/src/app
Removing intermediate container ea5359354513
—> a382209b69ea
Step 3/6 : COPY requirements.txt ./
—> b994369a0a58
Step 4/6 : RUN pip install –no-cache-dir -r requirements.txt
—> Running in 1e60a96f7e7a
Collecting paho-mqtt==1.3.1 (from -r requirements.txt (line 1))
Downloading https://files.pythonhosted.org/packages/2a/5f/cf14b8f9f8ed1891cda893a2a7d1d6fa23de2a9fb4832f05cef02b79d01f/paho-mqtt-1.3.1.tar.gz (80kB)
Installing collected packages: paho-mqtt
Running setup.py install for paho-mqtt: started
Running setup.py install for paho-mqtt: finished with status ‘done’
Successfully installed paho-mqtt-1.3.1
Removing intermediate container 1e60a96f7e7a
—> 3340f783442b
Step 5/6 : COPY device.py .
—> 72a88b68e43c
Step 6/6 : CMD [ “/bin/bash” ] —> Running in a128ffb330fc
Removing intermediate container a128ffb330fc
—> dad1849c3966
Successfully built dad1849c3966
Successfully tagged device:latest
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
device latest dad1849c3966 About an hour ago 903MB
python 2 0fcc7acd124b 9 days ago 902MB
Publish the Docker image
docker push mattjarvis/device
The push refers to repository [docker.io/mattjarvis/device]
d52256b6a396: Pushed
6b19db956ca6: Pushed
cd0c68b16296: Pushed
812812e9c2f5: Pushed
05331f1f8e6f: Layer already exists
d8077e47eb94: Layer already exists
5c0800b60a4e: Layer already exists
ebc569cb707f: Layer already exists
9df2ff4714f2: Layer already exists
c30dae2762bd: Layer already exists
43701cc70351: Layer already exists
e14378b596fb: Layer already exists
a2e66f6c6f5f: Layer already exists
latest: digest: sha256:8a1407f64dd0eff63484f8560b605021fa952af00552fec6c8efb913d5bba076 size: 3053
$ cat mongogw.py
#!/usr/bin/env python
MQTT to MongoDB Gateway
import json
from argparse import ArgumentParser
import paho.mqtt.client as mqtt
import pymongo
import datetime
import os
parser = ArgumentParser()
parser.add_argument(“-b”, “–broker”, dest=”broker_address”,
required=True, help=”MQTT broker address”)
parser.add_argument(“-p”, “–port”, dest=”broker_port”, default=1883, help=”MQTT broker port”)
parser.add_argument(“-m”, “–mongouri”, dest=”mongo_uri”, required=True, help=”MongoDB URI”)
parser.add_argument(“-u”, “–mongouser”, dest=”mongo_user”, required=True, help=”MongoDB user”)
parser.add_argument(“-w”, “–mongopwd”, dest=”mongo_password”, required=True, help=”MongoDB password”)
args = parser.parse_args()
def on_message(client, userdata, message):
json_data = json.loads(message.payload)
post_data = {
‘date’: datetime.datetime.utcnow(),
‘deviceUID’: json_data[‘uuid’],
‘value’: json_data[‘value’],
‘gatewayID’: os.environ[‘MESOS_TASK_ID’]
}
result = devices.insert_one(post_data)
# MongoDB connection
mongo_client = pymongo.MongoClient(args.mongo_uri,
username=args.mongo_user,
password=args.mongo_password,
authSource=’mongogw’,
authMechanism=’SCRAM-SHA-1′)
db = mongo_client.mongogw
devices = db.devices
# MQTT connection
mqttc = mqtt.Client(“mongogw”, False)
mqttc.on_message=on_message
mqttc.connect(args.broker_address, args.broker_port)
mqttc.subscribe(“device/#”, qos=0)
mqttc.loop_forever() Deployment And Results
$ cat demo.json
{“mongodb-credentials”: {
“backupUser”: “backup”,
“backupPassword”: “backupuserpassword”,
“userAdminUser”: “useradmin”,
“userAdminPassword”: “useradminpassword”,
“clusterAdminUser”: “clusteradmin”,
“clusterAdminPassword”: “clusteradminpassword”,
“clusterMonitorUser”: “clustermonitor”,
“clusterMonitorPassword”: “monitoruserpassword”,
“key”: “”
}
}
$ cat mongouser.json
{
“user”: “mongogw”,
“pwd”: “123456”,
“roles”: [
{ “db”: “mongogw”, “role”: “readWrite” }
]
}
$ dcos percona-server-mongodb user add mongogw mongouser.json
{
“message”: “Received cmd: start update-user with parameters: {MONGODB_CHANGE_USER_DB=mongogw, MONGODB_CHANGE_USER_DATA=eyJ1c2VycyI6W3sidXNlciI6Im1vbmdvZ3ciLCJwd2QiOiIxMjM0NTYiLCJyb2xlcyI6W3sicm9sZSI6InJlYWRXcml0ZSIsImRiIjoibW9uZ29ndyJ9XX1dfQ==}”
}
$ dcos package install percona-server-mongodb –options=demo.json
Default configuration requires 3 agent nodes each with: 1.0 CPU | 1024 MB MEM | 1 1000 MB Disk
To view the inserted data
rs:PRIMARY> db.devices.findOne();
{
“_id” : ObjectId(“5b9a6db71284f4000452fd31”),
“date” : ISODate(“2018-09-13T14:01:27.529Z”),
“deviceUID” : “f5265ed9-a162-4c72-926d-f537b0ef356c”,
“value” : 22,
“gatewayID” : “mqtt.instance-565e6b1f-b75d-11e8-9d5d-fe0bc23c90b8.mongogw”
}
$ cat device.json
{
“id”: “device”,
“instances”: 3,
“cpus”: 0.1,
“mem”: 16,
“cmd”: “./device.py -b mqtt.marathon.l4lb.thisdcos.directory -r 2”,
“container”: {
“type”: “MESOS”,
“docker”: {
“image”: “mattjarvis/device”,
“forcePullImage”: true,
“privileged”: false
}
},
“requirePorts”: false
}
Conclusion And Future
Seeing how popular IoT systems are to become in the future, there’s only so much that the machines themselves can do to keep themselves optimal and efficient. It is expected to become an instrumental tool in integrating the use of the internet over a wider landscape of products and devices, all linked to the same chain.
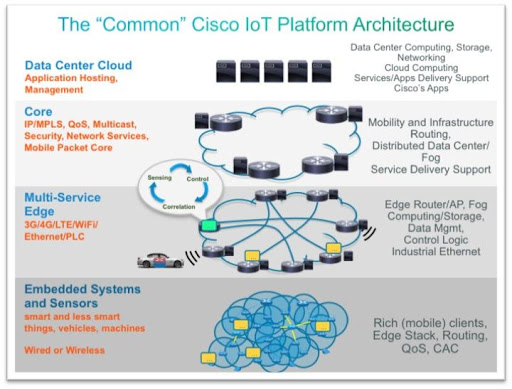
Source:- https://www.cisco.com[/caption]
It thus becomes essential to impart specific thoughts regarding scaling the systems for all sorts of businesses and that also have reliability and security. Amazon’s AWS and the DC/OS seem to be the most sought-after platforms but must be combined with server add-ons with multiple source vectors to allow for maximum efficiency and security.
As far as scalable IoT architectures go, the emphasis should remain on retaining and rationalising elements and code that seems useful while discarding anything unnecessary or bulky to the mainframe.
Must Reads:[wcp-carousel id=”10027″]