
What is Infrastructure as Code and How Can You Leverage It?

Managing IT infrastructure has always been a complex job. In a traditional setup, it fell to system administrators to manually configure and manage the software as well as hardware to get the applications up and running. Even though cumbersome, this approach worked just fine when the quantum of infrastructure that needed to be managed was minimal.
However, as the scale of infrastructure continues to expand, managing infrastructure has come down to handling several smaller instances at the same time, rather than a few large ones. The cyclic nature of modern-day infrastructure has made it imperative to transform the way infrastructure is designed, developed, configured, managed, and maintained. That’s where Infrastructure as Code (IaC) comes in.
Let’s take a closer look at what Infrastructure as Code is all about and how it can be leveraged.
What is Infrastructure as Code (IaC) and What Problems Can It Solve?
Infrastructure as Code (IaC) refers to the process of provisioning and managing IT infrastructures such as networks, load balancers, virtual machines, data centers, and connection topology in a descriptive model through machine-readable definition files with the help of versioning being used by the DevOps team as source code. This makes redundant the use of interactive configuration tools or physical hardware configuration.
Simply put, IaC allows you to manage tech infrastructure just by using configuration files. But why is that necessary or even recommended? To help you understand why you need it, let’s take a look at how IaC can streamline processes.
What Problems can Infrastructure as Code Solve?
The traditional approach of managing IT infrastructure manually was riddled with problems. These problems would only be augmented as the magnitude of the infrastructure around us grows.
Cost is the first problem posed by managing an expansive infrastructure that meets modern-day IT needs. From maintaining a team of professionals comprising technicians such as hardware maintenance and network engineers, to setting up and managing data centers, the complex requirements translate into astronomical costs.
Secondly, the slow and often tedious process of manual configuration can hamper the speed of availability and scalability. With every spike in access or surge in peak loads, system administrators would have to hurry to manage the load. This not only impacts the speed of access but also amplifies the risk of applications being rendered unavailable for long stretches.
Lastly, with different people manually handling configurations and management of IT infrastructure, discrepancies and inconsistencies become an unavoidable part of manual infrastructure configurations.

In contrast, with IaC, all of this can be handled with a single code file. Since the infrastructure is effectively managed and run with just text, you can tweak it as per your requirements and place it under source control, as you would do for any other source code file.
What Benefits Does it Bring?
A lot of the problems posed by manual management of infrastructure were and still can be resolved through cloud computing solutions. But not all. That’s why IaC has emerged as the final piece of the jigsaw needed to support and streamline DevOps as seamlessly as possible.
Let’s take a look at the key benefits of Infrastructure as Code to understand how:
- Speed: Infrastructure as Code gives you the element of speed by enabling users to set up the infrastructure in the shortest time frame possible by simply running a script. This can be done for every environment, right from development to QA, production, and staging, bringing greater efficiency to the entire development lifecycle.
- Accountability: Since Infrastructure as Code configuration files can be versioned like any other source code file, there is total transparency about the impact of each configuration. This transparency helps fix accountability for what’s working and what’s not.
- Consistency: Eliminating the need for manual handling of infrastructure diminishes the risk of human error. That means no discrepancies, inconsistencies, mistakes, or communication lapses in the way infrastructure is designed, deployed, or managed. The configuration files act as a singular source. These can be deployed several times over without risking errors.
Immutable vs Mutable Infrastructure
As cloud computing, Big Data, and the Internet of Things become the new normal in the IT world, the discourse around infrastructure being immutable is growing. But what is immutable infrastructure? How does it differ from its mutable counterpart? And can this bring about a paradigm shift in operations?
To understand this, let’s explore the difference between immutable and mutable infrastructure:
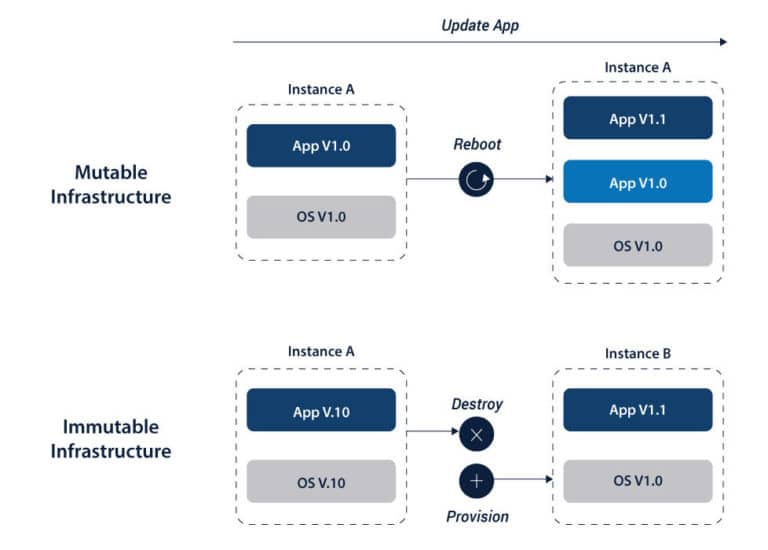
Mutable Infrastructure as Code
Mutable means being prone to change, and hence, easily mutated. In the realm of Infrastructure as Code, mutable describes an infrastructure setup that needs constant change and upgrades to keep up with the changing business demands. To achieve this, IT teams have to address the individual needs of every server and switch. This can be a long-drawn process, where the focus is limited to identifying and resolving problems rather than innovating to build a system free of quirks and limitations.
Mutable Infrastructure as Code creates an ecosystem where only a specific set of professionals can address the problems related to specific servers, also known as snowflakes. This means that the process of issue resolution can get held up or derailed if the designated person or team is unavailable at any given time.
Mutable infrastructure also puts business operations at the risk of configuration drifts. For instance, every time new configuration changes are made to app services, it can lead to executables being intertwined to be able to perform the required function. This can hit project performances in the long haul.
That said, mutable infrastructure creates an environment where issues can be identified and resolved more swiftly. Besides, it makes a great fit when you’re looking to cater to some specific requirements.

Immutable Infrastructure as Code
On the other hand, immutable infrastructure is not capable of change, making it more resilient. Since each component of Infrastructure as Code here is custom-made to precise specifications, it is also a more futuristic solution.
Immutable Infrastructure as Code has no scope for addressing small deviations individually. If a change is needed, the entire infrastructure is re-provisioned to cater to these requirements and the old one is decommissioned. While it may seem like a wasteful exercise, it proves immensely effective in achieving uniformity and consistency in Infrastructure as Code.
Immutable Infrastructure as Code is the outcome of virtualization, largely supported by cloud computing. In this model, both software and hardware are maintained on the cloud, which means businesses don’t have to worry about provisioning new infrastructure or discarding the existing one to meet their changing requirements.
Instead, based on an understanding of infrastructure requirements and the steps needed to meet them, you can simply create code scripts capable of assembling requisite components. In doing so, the entire process can be automated.

Declarative vs Imperative Approach
An Infrastructure as Code framework can be designed and deployed using two different DevOps paradigms – declarative and imperative. In the imperative approach, the responsibility of defining the exact steps necessary to meet an end goal is with the user. This means the user has to specify software installation instructions, database creation, configuration, and so on. While the execution of these steps is fully automated, the results of an operation are determined by the definition and execution sequence specified by the user.
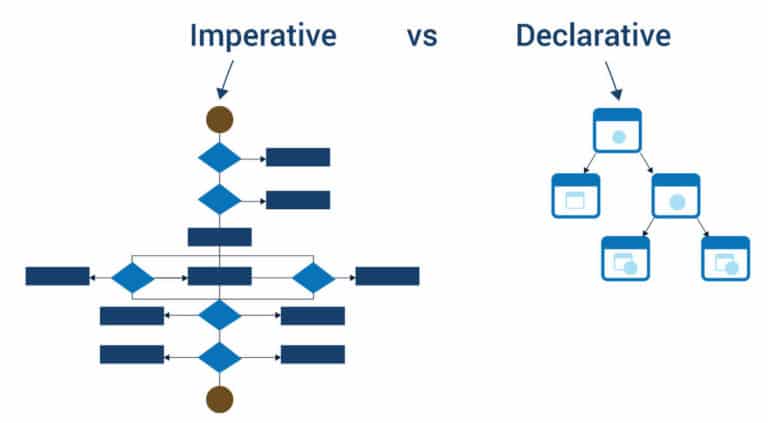
A declarative approach, on the other hand, focuses on defining the ultimate state rather than the exact steps. A user specifies – or declares – the number of workloads to be containerized or virtualized, the application and machines that need to be deployed, and how they will each be configured. However, you don’t have to concern yourself with the exact steps needed to complete these processes. A code is executed to complete the operations necessary to achieve the end state declared by the user.
Now, the question is how these two approaches manifest when designing, deploying, or managing Infrastructure as Code. These key differences hold the answer:
- Configuration Drift: Configuration drift happens when infrastructure goes through small changes over time. Between imperative and declarative Infrastructure as Code, the latter is better equipped to adapt to this drift.
- Repeatability: Repeatability is one of the core elements of Infrastructure as Code. This means a script must create the same changes whether it is being run in a test environment or a production environment. However, in imperative Infrastructure as Code, the same script can trigger different outcomes in different environments, adversely affecting the repeatability.
- Speed and Simplicity: Context is crucial to both imperative and declarative approaches to Infrastructure as Code. That’s where the elements of simplicity and speed brought in by the imperative approach, especially in the case of simple script updates, far outdo its potential downsides.
- Idempotency: The ability to achieve the same results by running a command, known as idempotency, is also a huge drawcard for Infrastructure as Code. Just like repeatability, here too the declarative approach is a more reliable route for achieving this consistency. Imperative infrastructure may only be able to run a command only one time unless there is a code with a specific logic that tells it otherwise.
There is no clear or straightforward answer to which of these two approaches is better suited for Infrastructure as Code. Broadly, imperative infrastructure is a better fit for small deployments whereas declarative is the way to go for big software environments that need massive scalability.
Infrastructure as Code Best Practices
Now that you know what models and approaches you can use to augment the efficiency of your IT operations with Infrastructure as Code, here is a lowdown on the best practices that can help you leverage it optimally:
- Code Everything: The meaning of Infrastructure as Code would be defeated if the element of code is missing from the mix. That’s why you must start by coding all infrastructure specifications. This will help in specifying which cloud components you use, how the cloud environment is configured, and the way components relate to one another. Only then can infrastructure be deployed as code seamlessly and quickly.
- Minimize Documentation: Infrastructure as Code tracks and documents every step and process in great detail, so you don’t have to. Break away from the tendency to top this up with additional instructions or documentation processes that your IT team has to execute.
- Test, Integrate, Deploy, Repeat: To be able to manage changes to infrastructure code and keep it running optimally, you must invest in continuous and repeated testing, integration, and deployment. This can help weed out any post-deployment issues and security risks. Besides, this practice can also make it easier to spot threats and bugs early on in the development life cycle, minimizing their risk after going live.
- Make Infrastructure Code Modular: Microservices architecture is emerging as a popular trend in the software development world owing to its ability to create units that can be built and deployed independently. By applying this concept to Infrastructure as Code, you can create distinct stacks or modules that can be later combined automatedly. This approach gives you better grip and control over who is granted access to different parts of your infrastructure code. Besides, breaking up the infrastructure into smaller bits can make it easier to detect and fix bugs, making your operations more agile.
- Version Control: Just like with any other application code, it is crucial to maintain version control of the infrastructure codebase as all the configuration details exist as code. Therefore, maintaining an audit trail for code changes can help you track and manage the changes in the entire infrastructure.
- Build Immutable Infrastructure: The concept of replacing infrastructure components rather than changing them in-place can go a long way in bringing consistency to your operations. That’s why you should commit to adopting immutable infrastructure as far as possible. With this, code written and deployed for an infrastructure stack can be repeated several times over without any risk of configuration drift. Wherever configuration-level changes are needed, you can simply retire the existing stack and replace it with a new one.
These best practices are the cornerstone of IaC. By using these to manage infrastructure across multiple environments and teams, you can reduce your dependence on manual processes and ensure faster software delivery almost every time.
Conclusion
Infrastructure as Code is a key element of DevOps. In a tech world that is constantly being transformed through disruptive technologies, Infrastructure as Code is the logical next step to make your operations future-ready. It helps you unlock the full potential of cloud computing, eliminates errors associated with manual management of tech infrastructures, and brings agility to the rapid software development lifecycle. And it does all this while lowering operational costs.
If you would like to learn more about how to automate your infrastructure, or if you would like personalized guidance about implementing this in your organization, email us at info@34.200.212.66.