
Unraveling Detection Methodologies: Indicators vs. Anomalies vs. Behaviors

In the information age we live in, online computing, transacting and storage of all data or information related to any field and work is the expected norm. With all businesses moving to the cloud, security of the data held in terms of authentication and authorization become key. Several companies have lost their credibility overnight due to security leaks and virus attacks and hence the order of the day is to establish trusted security norms and continuously test and strengthen them to prevent malware attacks and other intrusions.
This article talks in detail about the concept of IOC or the Indicators of Compromise and their importance in computer forensics.
All about IOC (Indicators of Compromise)
Indicators of Compromise, as the name suggests is a computer legal terminology for an artifact or an entry in the log which strongly indicates that the operating system or the network has been compromised and is prone or has already undergone a malware attack. These are descriptions of indicators, for example, the presence of an executable file in a specific file location.
Some standard Indicators of compromise include:
- Unfamiliar files, processes or applications running on the system. This indicates that the security of the system has been compromised.
- Network traffic or requests sent to important and usually unused ports are suspicious and an indicator of compromise.
- Irregular activities like requests sent from places which are not part of the company’s business. This usually indicates the presence of proxy servers to make the source of the application undetected.
- Brute force attacks, like suspicious login attempts, unauthorized entry into the server, network attacks, etc. are all indicators of compromise.
- Suspicious and unusual activity on admin and root user accounts.
- Large amounts of malicious read traffic, usually for the same file or information, virtually bringing the application down is an indirect indicator of compromise.
- Unusual Increase in the DB reads requests.
Though the above IOCs all indicate vulnerability in the system, there is a problem of plenty wherein, there are too many categorized IOCs which make the defense mechanisms slow and long drawn and as a result vulnerable again.
Another issue we currently face concerning most IOCs is that it is more of a forensic postmortem tool which discovers attacks after they happened and is not very useful in preventing the first wave of attacks which can be lethal to a system. The data breach if not stopped, must be notified to all users as per the latest EU GDPR (General Data Protection Regulation) law. This is an indication that the organization has failed in its fight to control data piracy and hence calls for a more proactive and preemptive method to handle security issues.
The techniques used for IOCs are alerting based on indicators and blocking requests.
To summarize, the below picture can provide a handy reference regarding IOCs:

Anomalies Identification
As outlined above, indicators are not enough to fully safeguard an organization’s data and applications and transactions. Detection must be capable of identifying and preventing new attacks on the system and security must be organization specific. For example, a telecom BSS product might have different requirements when compared to a social networking website.
To summarize:
- Detection must be organization specific
- Attacks come with several different modus operandi, intentions, speed, and security threat.
- For detection to prevent attacks, Indicators of compromise is not enough.
To augment and add to the indicator analysis is the Anomaly detection paradigm which works differently. First, for the application/ process/ program, a pattern or a trend is established or baselined. Average sales hit count, activity per user is usually within the average, and any spike or fall in action must arouse suspicion and initiate an investigation into the security of the application. This calls for continuous monitoring of the system health and reactionary approach to an ongoing suspicious event. Deviation must cause immediate suspicion and must invite the attention of the network engineers who safeguard the system against attacks.
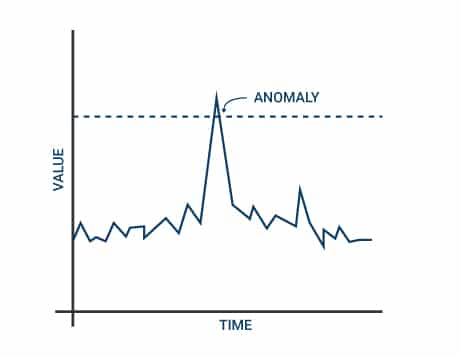
The baselining activity is specific to the concerned parties, and care and foresight must be exercised before arriving at the baselines, and these must continuously be revisited to ensure a secure system.
The best way to carry out anomaly monitoring is to look at metrics measurement from the system and to decide a minimum and maximum value limit on it. If the present value is within the selected range, then the system is healthy. If the value is outside the normal range, then the system is unhealthy and hence, an alarm must be raised, flagging a potential and ongoing security threat.
This standard practice of enforcing hardcoded alarm limits is a cause of concern as it is known to raise a substantial number of sadly false alarms, which means that even healthy systems have several alarms raised. There is also the case of missing alarm notifications, i.e., in situations which are problematic but do not cause the bell to be built. The false alarms raised wastes not only valuable effort and time but also caused unavailability of the server or application. The second issue, i.e., the absence of alarms is much more critical, as it prevents the detection of attacks.
Both of the issues described above are a result of the same underlying problem- The overall health of an application cannot be reliably predicted based on analysis of each metric on its own. We must hence consider a prudent combination of the many parameters and measurements to get an accurate picture of the present situation of the application
Below are a few pointers to ensure proper anomaly identification:
- Use of statistical analysis and tools: Using statistical methods like principal component analysis (PCA), Gaussian distribution and other techniques of multivariate statistics, can help understand live anomaly readings and understand which events are anomalies in a better way. There are however some challenges in this method like time sampling, use cases used, etc. There are machine learning tools like H2O’s autoencoder and R solution which tries to automate this process.
- Random forest modeling: This method constructs several decision trees based on different samples and then displays the average output. This improves classification techniques and is a form of supervised learning.
- Artificial Neural Network: If the reconstruction loss in this method exceeds a certain limit, then an anomaly is said to exist. Softwares like ELKI exist to perform several anomaly detection tests and produce an outlook on which anomaly can be considered as a threat.
To troubleshoot anomalies, better information enrichment must be carried out so that all the above techniques can be more effective in their outcomes. Though there are several tools to automate machine learning and anomaly detection, skilled human intervention in the form of system analysts are required to ensure that the right anomaly is getting the correct attention.
The primary techniques used for anomaly detection are Data gathering, storage, analysis and decision making. This entire process but take minimum time as the ongoing threat must be identified quickly and blocked.
Limitations of Anomalies:

Though, in theory, anomalies seem to make complete sense, the reality is different. The baseline needs to be updated continuously, and modeling can go completely wrong and leave the intrusions undetected.
Also, there is the same problem of alert fatigue. If all parameters combined in an anomaly turns out to be a false alarm. Then the modeling went wrong, or the baseline needs to be changed. Though anomalies are an excellent way to detect potential intrusions, these techniques alone are not enough to ensure a secure system.
Behavior Detection and Analysis:
The next and the better approach to solving the security problem is behavior detection and analysis. In this technique, the organization involved in securing the security aspects of the system must have an understanding of the primary threat level and the potential threat environment. It must have done an analysis and arrived at a list of probable threats it can face in terms of data breach and system security. It must have a team dedicated for security analysis so that the Tactics, Techniques, and Procedures of the adversary are researched and understood so that appropriate response can be given.
Some Features of TTP (Tools, techniques and procedures) based detection are:
- Privilege escalation: A process in the system, running with an allowed low privilege user, ironically contains a child thread in the very same order, running with a higher privileged user. This is suspicious and not acceptable behavior.
- Pass the Hash attacks: Malware based caches store the authentication and authorization credentials of another user and then reuse them in Pass-the-Hash attacks. This attack describes the behavior of a particular user who misuses the identity of another different user, but on the same system to get access to a specific resource.
- Domain Generating Algorithms (DGA): Behavior of a system or an application or a process that uses the methodology of dynamically generating domain names, where the majority of them don’t resolve during a lookup, and a few do determine during the search but not in a manner that can be cached and used.
What behavior analysis essentially means is that instead of entirely relying on the automatic security-related solutions and mechanisms, the organization or the defender needs to first understand all the Tactics, Techniques, and Procedures (TTP) of its enemy entity, and then start planting clever obstacles which could stop attacks from even a very highly motivated and resourceful attacker, such as an APT (Advanced Packet tool), which is basically a free software interface.
This result can be achieved by constant and relentless studying the occurring attacks which are in the wild, analyzing their Techniques Tactics and processes, forming and training of experienced blue teams to get into the mind of an Advanced Persistent Threat (APT) actor, and directly engaging the organization’s own blue outfit with the adversary red team, in order to actually keep up with the sharp and anti-hacking skills for the detection of intrusion attempts, and implementing several counter mechanisms which prevent these attacks from happening.
While there is no metaphoric silver bullet to arrest cyber-attacks, which cause a significant amount of agony and pain for an adversary, the organization can drastically reduce the probability of a security breach. Hence, it is essential to fully clarify and understand the critical concepts in HTTP as exposing TTP like the pattern, which will have a direct impact on the adversary.
It can be argued that behaviors are backward looking too, but if we assume that no attack can be a complete innovation from what is already known, then we can understand that we prevent most attacks.
Kill Chain Coverage
One concept of behavior analysis is killed chain coverage wherein a preemptive action of destroying the adversaries defense and shutting them down before they can carry out their plans. The dependency which the attacker has can also be identified and eliminated into order to ensure that a malicious attack does not occur. This is a form of behavior analysis, and though many critics do not prefer this approach and there are chances to hurt systems which are not the adversaries, this presents a viable action to prevent malicious attacks.
The technique used for behavior detections is a correlation engine, which combines and understands several events together. This is a slightly expensive method compared to the other ones and needs continuous updation of the feedback loop for it to be effective.
Limitations of behavior analysis:

Behavior analysis, as stated above is complicated to implement. It might need a huge effort to analyze the breadcrumbs left by the malicious attacks and get an overall picture of how the opponent operates. Behavior analysis, like IOC, makes a lot of assumptions and the methods to set traps and prevent malware attacks might not be effective.
Credential Thefts
Credential thefts are one of the most common security breaches, which makes applications vulnerable and open to scrutiny. Credential theft might lead to identity theft which might have long drawn implications.
These thefts are logged in authentication records and can be missed entirely in the IOC way of doing things. Several invalid login attempts can give a clue but tools to identify credential thefts employ vague and fuzzy algorithms which can do little to prevent them from happening.
Anomaly detection can prove slightly more useful as new logins to a host, from a host with a set of credentials can be flagged. However, the issue with this approach is too many false positive and false negatives.
Credential theft behaviors can give the best approach to preventing identity thefts by contextualizing theft attempts and provides a complete picture to security analysts when some investigation is done.
Credential thefts can be in many forms. One-Many, Many-One, and Many-Many. The primary purpose of these attacks is to identify vulnerabilities in remote systems and try to enter into them, gaining access and entry.
Security Best Practices
All the behaviors explained above attempt different approaches and can be combined and used to create a formidable line of defense. These approaches complement each other and can together tighten considerably, if not provide airtight protection. This is, however, only in theory. Reality is a bit different. Vast resources cannot be spent on modeling and organizations might find it very hard to implement all of the above effectively.
The best tested and proven way to deal with security is for each organization to do a security audit during requirement gathering phase itself, understand what kind of protection is required for the application or process and then go on to do a threat analysis and find effective ways to guard against them. Depending on the financial resources available, the current and the future security roadmap can be determined.
To summarize, the best economical way is as below, based on the organizations needs only:

In the above diagram, the behaviors of adversaries are identified first, and then methods to determine if there are any attacks are determined. The two are then mapped to find the best way an adversary is capable of attacking the system.
This process must be repeatedly done as the threat landscape changes very often. To fully secure the offerings provided, the data of the users and the system online, the need of the hour is for organizations, big and small, to invest in their security needs and to understand the security risks and act against them. Employees of the organization must also be educated about the vulnerability so that they do not leave room for attacks.