
Evaluation of Machine Learning Algorithms for Intrusion Detection System

The last decade has seen rapid advancements in machine learning techniques enabling automation and predictions in scales never imagined before. This further prompts researchers and engineers to conceive new applications for these beautiful techniques. It wasn’t long before machine learning techniques were used in reinforcing network security systems.
The most common risk to a network’s security is an intrusion such as brute force, denial of service or even an infiltration from within a network. With the changing patterns in network behaviour, it is necessary to switch to a dynamic approach to detect and prevent such intrusions. A lot of research has been devoted to this field, and there is a universal acceptance that static datasets do not capture traffic compositions and interventions.
We need the modifiable, reproducible and extensible dataset to learn and tackle sophisticated attackers who can easily bypass basic intrusion detection systems (IDS). This is where machine learning comes into play. We will discover the various machine learning techniques that can be employed to build robust IDS.
What is an IDS?
‘Immense’ network assault takes down Yahoo
This is an excerpt from CNN describing the first ever DoS (Denial of Service) Attack.
“At 10:30 a.m. (Pacific Standard Time), it appears a Yahoo router experienced a distributed denial-of-service attack,” a Yahoo spokesperson said on condition of anonymity. “We believe it was coordinated, coming from multiple points on the Internet.”
Incidents like these can lead to potential loss in millions in revenue in the modern digital economy.
Intrusion Detection Systems(IDS) are precisely present to prevent the above scenario from affecting the organization.They monitor network traffic for suspicious activities and issue alert in case of issues.
Types of IDS
Intrusion Detection Systems can use a different kind of methods to detect suspicious activities. It can be broadly divided into:
- Signature-based intrusion detection – These systems compare the incoming traffic with a pre-existing database of known attack patterns known as signatures. Detecting new attacks is difficult. The vendors supplying the systems actively release new names. (similar to anti-virus software)
- Anomaly-based intrusion detection – It uses statistics to form a baseline usage of the networks at different time intervals. They were introduced to detect unknown attacks. This system uses machine learning to create a model simulating regular activity and then compares new behaviour with the existing model.
IDS detect intrusions in different places. Based on where they discover, they can be classified into:
- Network intrusion detection (NIDS) – It is a strategically placed (single or multiple locations) system to monitor all the network traffic.
- Host intrusion detection (HIDS) – It runs on all devices in the network which is connected to the internet/intranet of the organization. They can detect malicious traffic which originates from within (for example, when malware is trying to spread to other systems from a host in the organization)
IDS can also be classified based on their action:
- Active – it is also known as an intrusion detection and prevention system. It generates alerts and logs entries along with commands to change the configuration to protect the network
- Passive – it just detects malicious activity and generates an alert or logs, but it doesn’t take any action.
We will discuss hybrid intrusion systems using machine learning after listing out the general limitations of the IDS.
Limitation of traditional IDS
- Several real attacks are far less than the number of false alarms raised. This causes real threats to go often unnoticed.
- Noise can severely reduce the capabilities of the IDS by generating a high false-alarm rate.
- Constant software updates are required for signature-based IDS to keep up with the new threats.
- IDS monitor the whole network, so are vulnerable to the same attacks the network’s hosts are. Protocol-based attacks can cause the IDS to fail.
- Network IDS can only detect network anomalies which limit the variety of attacks it can discover.
- Network IDS can create a bottleneck as all the inbound and outbound traffic passes through it.
- Host IDS rely on audit logs, any attack modifying audit logs threaten the integrity of HIDS
Machine Learning in IDS
Before we get to the crux of the matter, here are a few things you should know:
Machine Learning is the field of study that gives computers the capability to learn and improve from experience without being programmed explicitly automatically. Machine learning focuses on the development of programs that can use data to discover themselves.
The process of learning begins with observations or data to look for patterns in data and make better predictions based on the examples provided. The primary aim is to allow the computers to learn without human assistance and adjust actions accordingly.
Machine Learning Algorithms can be broadly classified into:
- Supervised machine learning algorithms: can apply what has been learned in the past to predict future events using labelled examples. The algorithm analyses are known as a training dataset to produce an inferred function to make predictions about the output values. After sufficient training, the system can provide targets for new inputs. The machine is equipped with a new set of examples, so that supervised learning algorithm analyses the training data and produced a correct outcome from labelled data
- Unsupervised machine learning algorithms: are used when the information used to train is neither marked nor classified. Unattended learning studies how systems can infer a function to describe a hidden structure from unlabeled data. Here the task of machine is to group unsorted information according to patterns, similarities and differences without any prior training data. The device is restricted, and the structures don’t reflect
- Semi-supervised machine learning algorithms: makes use of unlabeled data for training – with a blend of less labelled data and a lot of unlabeled data.
- Semi-supervised learning falls between unsupervised learning and supervised learning: These are used when you don’t have enough labelled data to produce an accurate model, or you lack the ability/resources to obtain more, semi-supervised techniques can be used to increase the size of the training data.
Evaluating ML for an IDS
Unsupervised learning algorithms can “learn” the typical pattern of the network and can report anomalies without any labelled dataset. It can detect new types of intrusions but is very prone to false positive alarms. Hence, only one unsupervised algorithm K-means clustering is discussed ahead. To reduce the false positives, we can introduce a labelled dataset and build a supervised machine learning model by teaching it the difference between a normal and an attack packet in the network. The supervised model can handle the known attacks deftly and can also recognise variations of those attacks. Standard supervised algorithms will be discussed (Bayes Network, Random Forest, Random Tree, MLP, Decision Table).
Dataset
The most important and tedious process of getting started with machine learning models is getting reliable data. We use KDD Cup 1999 Data to build predictive models capable of distinguishing between intrusions or attacks, and valuable connections. This database contains a standard set of data, which includes a wide variety of interventions simulated in a military network environment. It consists of 4898431 instances with 41 attributes.
Each connection is labelled as either normal or as an attack, with exactly one specific attack type. Each connection record consists of about 100 bytes.
Attacks fall into four main groups:
- DOS: denial-of-service
- R2L: unauthorized access from a remote machine
- U2R: unauthorized access to local root privileges
- probing: surveillance and another probing
Each group has various attacks, and there are a total of 21 types of attacks.
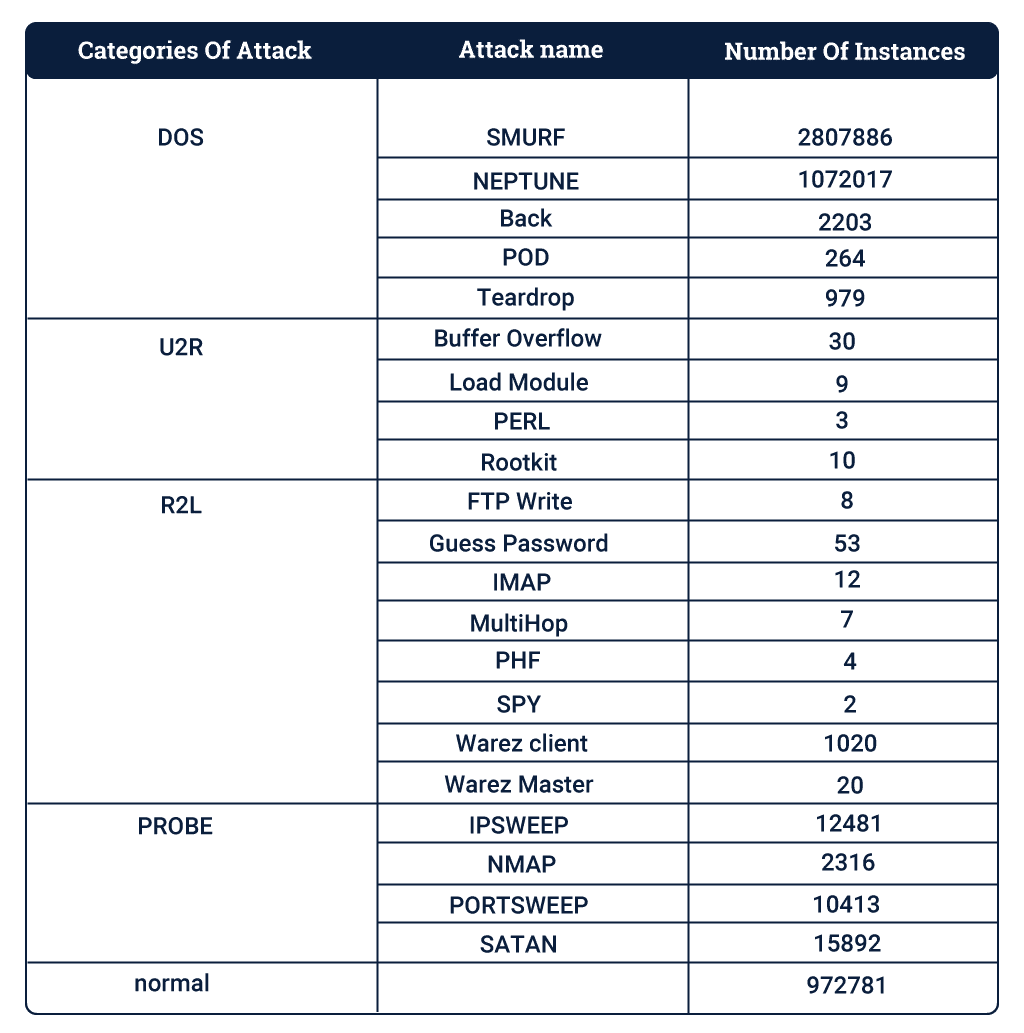
KDD Set Summary
The attributes categorized as necessary information which is collected using any connection implemented based on TCP/IP are also shown below:
Basic Features

Data has to be processed before it can be used within a machine learning algorithm. This means that the features have to be chosen. Some elements can be easy to find; other have to found by experimenting and running tests. Using all the features of a dataset does not necessarily guarantee the best performances from the IDS. It might increase the computational cost as well as the error rate of the system. This is because some features are redundant or are not useful for making a distinction between different classes.
The main contribution of this dataset is the introduction of expert suggested attributes which help to understand the behaviour of different types of attacks, the essential characteristics to detect DOS, PROBE, R2L and U2R are included. Here is a list of a few content features suggested by domain knowledge.
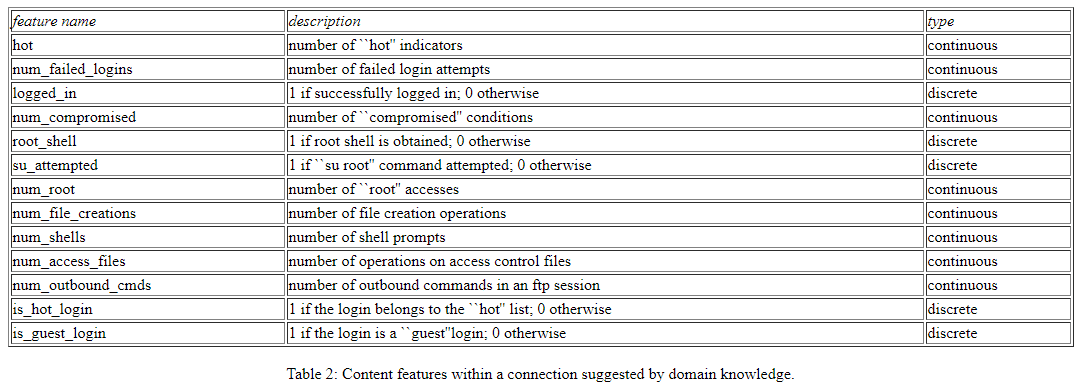
Expert features
Other few other datasets are also mentioned here:
- ISCX 2012 Dataset collected by the Canadian Institute for Cybersecurity (labelled)
- CTU-13 Dataset captured in the CTU University, Czech Republic, in 2011 (unlabelled)
Overview of Machine Learning Algorithms
K-Means Clustering
As mentioned earlier, K-means clustering is an unsupervised learning technique. It is one of the simplest and most popular machine learning algorithms. It finds groups in the data, where the number of groups is represented by the variable K. The algorithm assigns the data points to one of the K groups based on the features of the dataset. Data points are clustered based on the similarity of features.
Bayes Network
Bayesian networks are a type of probabilistic graphical model. It aims to take advantage of conditional dependence by plotting the dependencies on the edge of a directed graph. It assumes all nodes not connected by an edge are conditionally independent and exploits this fact in the creation of the directed acyclic graph.
Random Forest Classifier
Random Forest is an ensemble classifier, which means it combines many algorithms for classification purposes. They create multiple decision trees on a random subset of data. It then aggregates the total votes of each tree to decide the class of the test, or it assigns weights to individual trees’ contribution.
Multi-Layer Perceptron (MLP)
MLP is a feed-forward neural network. It consists of at least three layers: the input layer, the hidden layer(s) and the output layer. During training, the weights or parameters are adjusted to minimize error in classification. Non-linearity is introduced in each hidden node. Backpropagation is used to make those weight and bias adjustments relative to the error.
Implementation
We will work with the IDS using Python and its extensive libraries available. Pandas, numpy,scipy need to be installed before we begin the application. If you are working in an Ubuntu shell use:
sudo pip install numpy scipy pandas
First preprocessing of the dataset needs to be done. The dataset needs to be downloaded and extracted to the folder where you will write the program.
The dataset should be in the .csv format which can be easily read by python.
# Import pandas
import pandas as pd
# reading csv file
dataset = pd.read_csv(“filename.csv”)
The machine learning algorithms mentioned earlier are all present in the fantastic scipy library. You can quickly run the dataset through different models by following the steps given below:
K-MEANS
import numpy as np
from sklearn.cluster import KMeans
print(dataset.describe()) # to view the summary of the dataset loaded
kmeans = KMeans(n_clusters=2) # You want cluster the threats into 5: Normal, DOS,PROBE, R2L and U2R
kmeans.fit(X)
prediction = kmeans.predict(dataset[0]) # predicts the type for the first entry
RANDOM FOREST
#Import Random Forest Model
from sklearn.ensemble import RandomForestClassifier
#Create a Gaussian Classifier
clf=RandomForestClassifier(n_estimators=50)
#Train the model using the training dataset
clf.fit(dataset,dataset[:,LAST_COLUMN]) #LAST_COLUMN is the index of the column with the labelled type of threat or normal
pred=clf.predict(dataset)
NAIVE BAYES NETWORK
from sklearn.naive_bayes import GaussianNB
#Create a Gaussian Naive Bayes Classifier
gnb = GaussianNB()
gnb.fit(dataset,dataset[:,LAST_COLMN])
pred=predict(gnb,dataset[0])
MULTI_LAYER PERCEPTRON
From sklearn.neural_network import MLPClassifier
#Create a Multi-Layer Perceptron
clf = MLPClassifier(solver=’lbfgs’, alpha=1e-5,
hidden_layer_sizes=(5, 2), random_state=1)
clf.fit(dataset,dataset[:,LAST_COLMN])
pred=clf.predict(dataset[0]);
Results
To gauge the accuracy of machine learning models we use various parameters. The metrics used here will be Average Accuracy, False Positive Rates and False Negative Rates. K-Means is excluded from this metric as it is an unsupervised algorithm.
Average Accuracy is defined as the ratio of the correctly classified data points to the total number of data points.
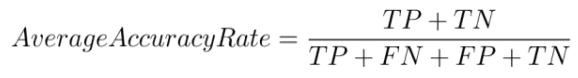
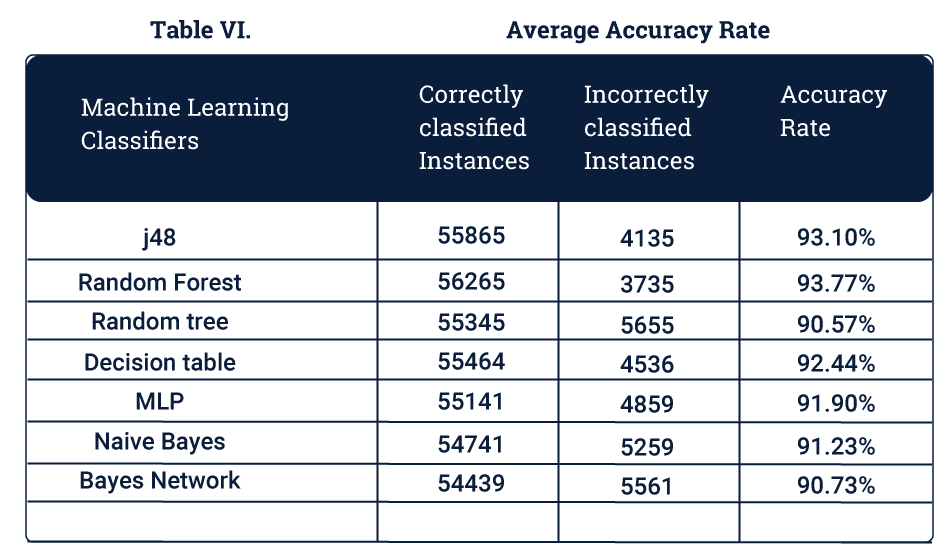
False Positives are those cases which were supposed to be returned as threats but aren’t.
False negatives are just the opposite. The cases which were supposed to be returned as usual but were reported as threats
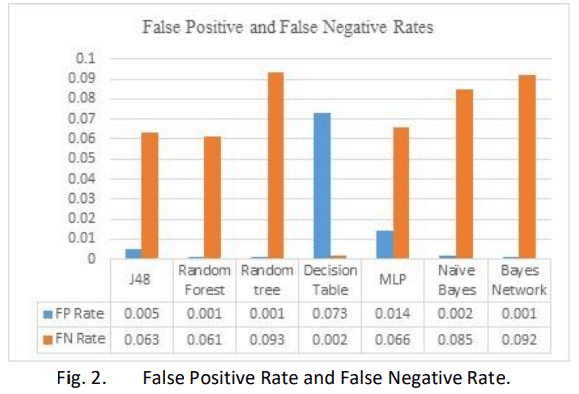
A few other metric comparisons are given below :
Precision and True Positives
Precision is the ratio of the perceived threats to total threats.
True positives are those packets which were threats and correctly identified as threats.
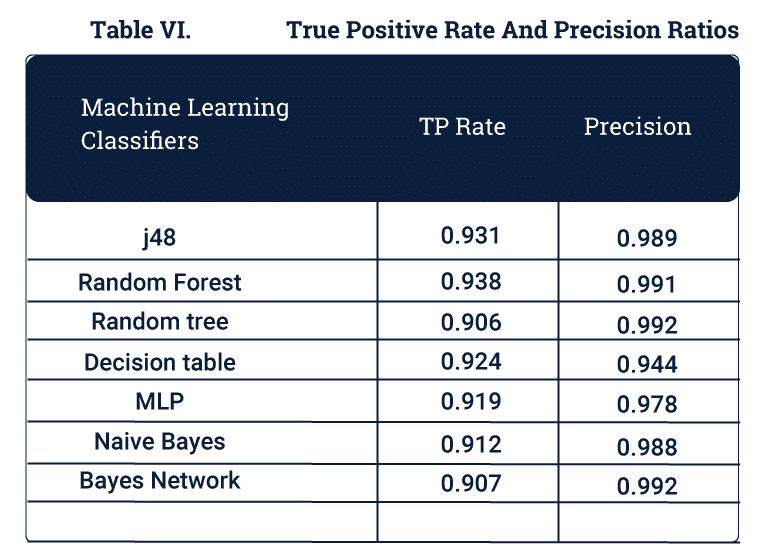
How it benefits your business
All current IDS are switching to Machine Learning Techniques to combat ever-increasing security threats to networks. This not only automates the process of intrusion detection but does so with astonishing accuracy. Businesses can use these results to target the source of attacks, block further attempts and optimize their network. Another significant advantage is that companies don’t have to pay for specific proprietary signatures to protect themselves from new attacks.
Conclusion
IDS using many Machine Learning Techniques were discussed in here:
● K-means
● Bayes Network
● Random Forest Classifier
● Multi-Layer Perceptron
Different techniques perform better in various metrics. The IDS should provide the most effective solutions based on the requirements. One thing is sure, any company failing to adopt these techniques now or in the immediate future risk compromising data or worse servers. Stay safe, adopt ML. As a CTO, these are the techniques which you can use and through which you can stand out effectively.