
Ethical Bias In AI-Based Security Systems: The Big Data Disconnect

It’s a question that has surfaced at the discussion tables of conferences and social chats everywhere-“Can machines turn on humans?”. It’s a question that often accompanies scenes and visuals from movies like the Terminator. But what we know and what we’ve seen from the use of AI in big data is that certain uncertainties and biases have to be considered when designing systems for larger scales with more complex environments.
What is it that machines feel? What is it that makes them behave the way they are other than the code that’s inserted into their mainframe? Do Isaac Asimov’s three laws still hold ground today in defining the standards for how machines should behave in a convoluted environment? The answers to these questions lie in the way we choose to define the rules of the game and how the machine responds to sudden changes.
Ethical biases are a special zone of uncertainty in Artificial Intelligence studies that concerns the trinkets and levers that pull machines to behave in ways that may seem strange or even detrimental at times. With the rise of autonomous vehicles and AI-driven production methods set to take over the world, an unanswered question demands an answer once again. What do we do about the machines?
Introduction To Biases
Biases and variances from a data perspective are linked to the proximity of the measured values from the actual values. Variance, in this case, is a measure of how far the measured values differ from each other and biases refer to how much the measured values differ from the actual values. In a highly specific case of models with great accuracies, both variance and bias would be small. This may, however, reflect how poorly the model will perform with new data. Nevertheless, having a low bias and variance is difficult to achieve and is the bane of data analysts everywhere. Biases are particularly more difficult to treat for use cases that involve simple decision making where simple binary computations aren’t enough.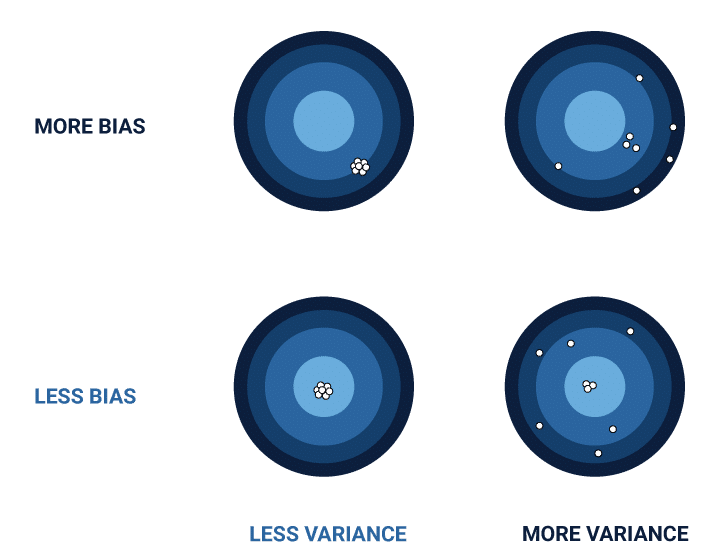
One is tempted to ask, why is it that biases find their way into the system? And if a machine fails to decide at a critical point no worse than humans, then why are they used in the first place? To answer these questions, one has to look at the general methodology of how models are built in the big data realm.
Data is first collected and cleaned from actuators and sensors that provide raw numbers for analysts to work on. These values then undergo a preprocessing step where they are normalized, standardized or converted to a form where dimensions and units are removed. Once the data is converted into a suitable tabular or comma-separated format, it is inserted into a network of layers or functional equations. If the model uses a series of hidden layers, rest assured they will have an activation function that will introduce a bias every step of the way.
However, biases can also enter the system through the many pitfalls of collection methods. Maybe the data wasn’t balanced towards a certain group or class of outputs, maybe the data was incomplete, erroneous or maybe there wasn’t any data, to begin with. As the datasets grow larger and larger with more incomplete records, the possibility of the system filling those gaps with some predefined values is certain. This results in another kind of assumptive bias.
The Black Box Conundrum
Many scholars would also argue that numbers may not mean the same thing without proper context. In the controversial book titled-‘The Bell Curve’ for example, the claim made by the author about IQ variations among racial groups was challenged with the notion of environmental constraints and differences. But if a human can arrive at such resolutions, how long would it take a machine to remove such judgemental lapses in its logic?
Chances are minimal. If the machine has been fed with erroneous or faulty data, it will output faulty values. The problem arises from the ambiguity of how the AI model is built. These are usually black box models that exist as data sinks and sources with no explanation of what goes inside. To the user, such black-box models cannot be interrogated or questioned as to how it arrives at a result. Furthermore, there are additional problems to be tackled with result variations. Due to a lack of understanding of how the black box operates, analysts may arrive at different results even with the same inputs. Such variations may not make a huge difference for values where precision isn’t key, but the data realm is seldom so generous. Industrial manufacturers, for example, would be at a loss if AI systems failed to predict highly specific parameters such as pH, temperature or pressure to large points. However, when the objective is to provide answers to problems like loan compatibility, criminal recidivism or even applicability for college admissions, AI’s lack of crisp values comes at a disadvantage. The onus is however on AI enthusiasts to tackle the issue from another angle.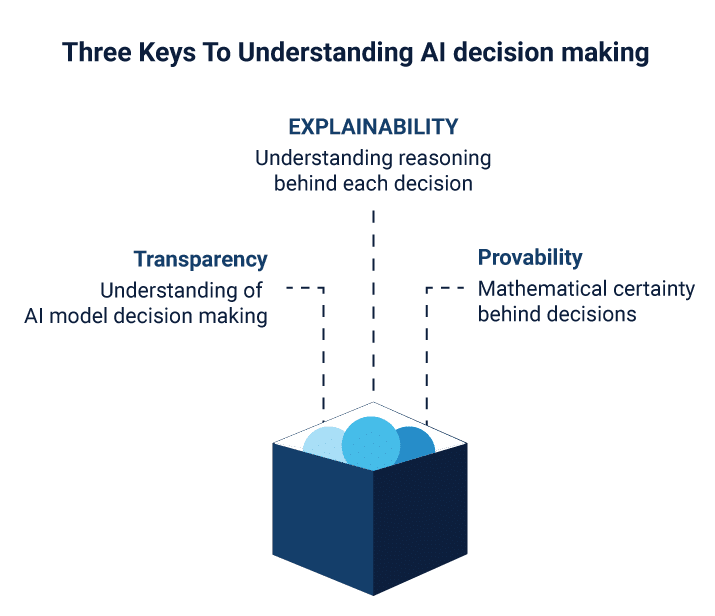
Put, the methods and the rules of the interferences between layers must be resolved to interpret what every line of code and coefficient represents. The black-boxes thus have to be uprooted and dissected to know what makes the machines tick, which is easier said than done. Taking a look at even the simplest of neural network AI is enough to show how complicated such systems are original. Nodes and layers all stack up with individual weights that interact with the weights of other layers.
It may look like a magnificent deal to the trained eye, but it leaves little interpretation for understanding the machines. Can it be simply due to the difference in language levels of humans and machines? Can there be a way to break down the logic of machine language in a format that the layman can understand?
Types of Biases
Covering back the history of biases in data analysis, there can be several biases that are introduced as a result of improper techniques or predefined biases in the entity responsible for the analysis. Misclassification and presumptive biases can be produced from models that are well-positioned towards balanced results because of certain inclinations and interests of the programmer.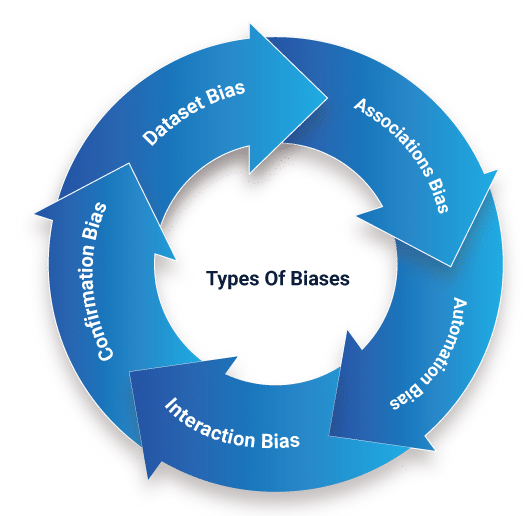
It’s an all too common mistake that certain marketing analysts make when dealing with leads. Collection software provides great data on people who have converted and those who haven’t. Instead of focusing on models that focus on both classes of people, most may be tempted to build models just for the unconverted leads. In doing so, they end up blinding themselves to the richness of available data for those that have become customers.
Another issue that plagues AI models is the inability to properly classify or misclassify data that culminates into a disaster for analysts. In the production industry, such errors fall under the Type I and Type II category-the former being when a classification is made for a record which doesn’t belong and the latter being when it fails to classify which does belong. From the context of the production lot, quality control engineers are quick to stamp the accuracy of goods by testing only a small portion of them. It saves time as well as money. But it can be the perfect environment for such hypothetical biases to occur.
Another similar example has been observed in image detection software where neural networks scan through broken portions of pictures to reconstruct logical shapes. There can be multiple problems caused by the similarity in the orientation of the objects in images that can cause the model to give out strikingly contentious results. Current age Convolutional Neural Networks are capable of factoring such intricacies but require large amounts of testing and training data for reasonable results.
Certain biases are a consequence of the lack of proper data being available were using complex models unwarranted and even unnecessary. It is a commonly held belief that certain models and neural network programming should only be applied to datasets once they reach a statistically significant number of records. This also means that algorithms have to be designed to check the quality of data on a timely basis reiteratively.
Fighting AI With AI
Is the solution to the problem with AI biases hidden within AI itself? Researchers believe that improving the tuning methods by which analysts collect and demarcate information is important and should take into account that not all information is necessary.
That being said, there should be an increased emphasis in removing and eradicating inputs and values that skew the models in completely untoward places. Data auditing is another means by which biases can be checked and removed well in time. This method like any standard auditing procedure involves a thorough cleanup and checkup of the processed data as well as the raw input data. Auditors track changes and note down possible improvements that can be made to the data as well as ensuring that the data has complete transparency to all stakeholders.
Specialized XAI models have been in question as well that can be put to the question table under the right circumstances. These models involve a much detailed parametric model development where every step and change is recorded, allowing analysts to pinpoint likely issues and trigger instances.
AI has also become a frontier for validating the accuracy and confusion matrices of models instead of relying on simpler tools like ROC curves and AUC plots. These models look at performing repeated quality checks before the deployment of the dataset and attempt to cover the data overall classes, regardless of distribution or shape. The nature of such pretesting is made more difficult with datasets where differences in units and ranges vary significantly over the inputs. Likewise, for media-related data, the time taken to break down and condense content to numeric formats can still lead to biases.
However, thanks to a new slew of changes in fundamentals for data transparency and third-party checks, companies are at least acknowledging that something is going wrong. New explainer loops are being inserted between the models as well that intend to accentuate the black boxes that fill most AI models. These are again driven by AI models that are fine-tuned systematically to look for inconsistencies and errors.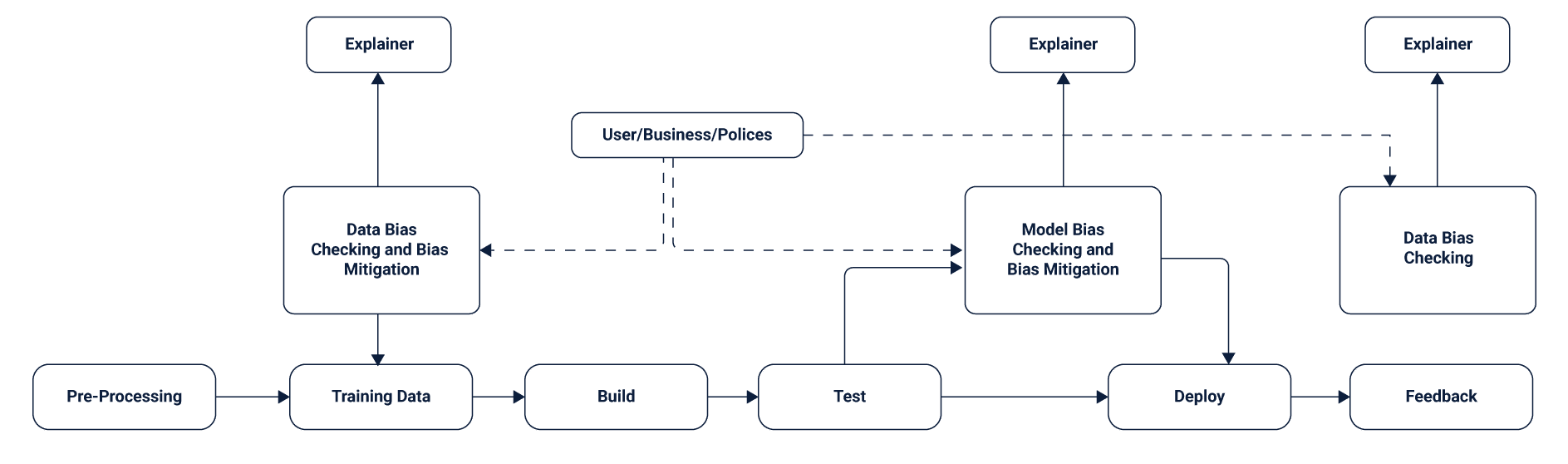
A Few Case Examples In AI Ethical Failures
Data analysts would be familiar with the concepts of false negatives and false positives. These discrepancies in identifying outputs can result in special cases of errors with detrimental effects on people. A false negative put is when the system incorrectly recognizes a positive class as negative. Similarly, a false positive occurs when a negative class is incorrectly recognised to be positive.
The severity of such false cases can be better understood in the context of actual big data studies. In the famous case of CHD(coronary heart disease) being modeled using logistic regression, confusion matrices for the false positives and false negatives yielded large numbers, despite yielding a high accuracy. To the average person, an accurate model may seem like the only important ‘make or break’ check. But even in the early days of data analysis, it was clear that such models would fall flat and even misdiagnose new patients.
The trade-off was made by collecting more data streams and cleaning the columns to induce better data normalization. A step that is becoming the staple for the industry these days.
Uber’s autonomous vehicles suffering crashes in testing phases aren’t the only red flags that industry professionals are concerned about. These fears extend to other spheres such as identification and machine perception as well. Tech giant Amazon came under the scrutiny of the media after its model had learned to develop what the media called a ‘gender bias’ towards women. In a shocking case of applicant bias(seen previously with applicants in tech companies), the models generated negative compliance for the applied job higher for women than men. Problems at the other end of the spectrum have been observed in tech giants like Apple, where the consumer hyped FaceID, allowed different users to access locked phones. One may argue that the models used to identify facial cues for detection might be generating similar results even for different people.
It was only a matter of time that engineers would stick to ironing out faults and conclude that there were assumptive biases produced from questionable inputs. AI’s big leap in the medical world has been set back quite a notch due to the failure in integrating ethical values; values which would have replaced nurses and staff on the go. This is mainly dealt with by construing all the possible number of case examples where a machine can properly replace a human and take the very same decisions. Although philosophy majors may argue that even humans don’t operate under a set of guidelines. There are various schools of ethics- Kantian, egalitarian, utilitarian and so on. How these schools of thought conform to various ethical conundrums is left to the person and his/her interests.
In the famous trolley case, a person’s inclinations to pull or not pull the lever dictated purely by the ethical framework in which the person operates. The question of accountability becomes fuzzy when machines take the place of the decision-maker.
Final Words-How To Make A More Ethical?
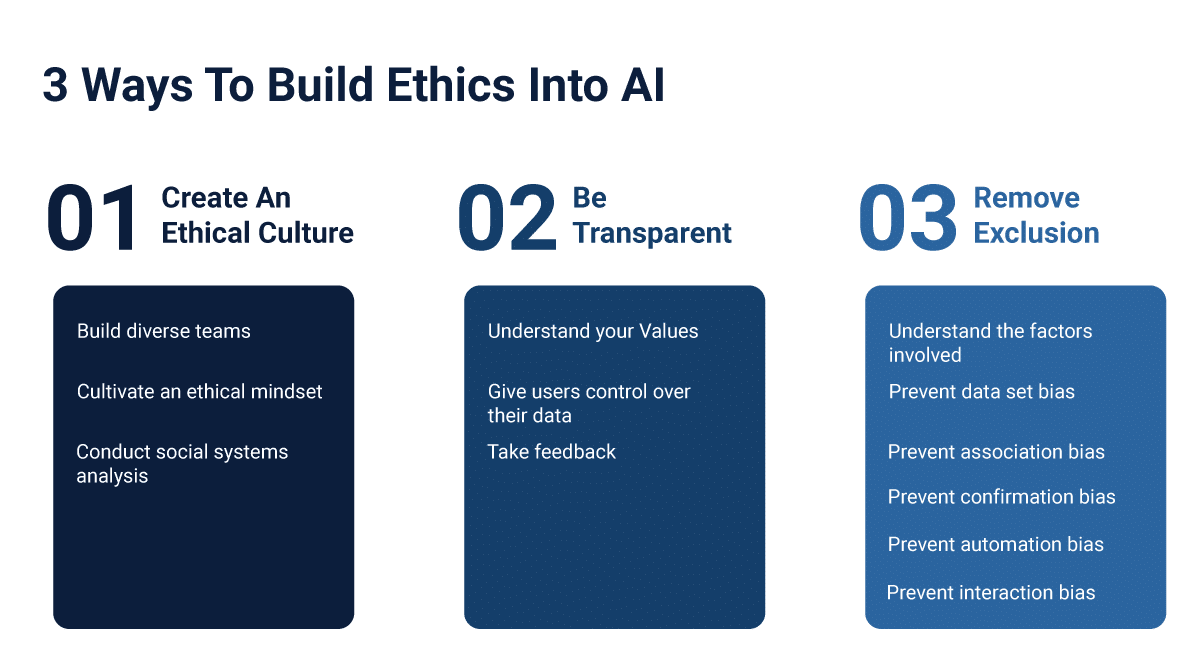
The eternal question of where we draw our tolerance of those systems leads the line for including machines in our day to day activities. AI has been the building block for life-saving and supporting frameworks such as transportation, predictive studies, financial investments, security, communication, and production. It has seeped into all significant aspects of human life without raising many nay-sayers.
The line is drawn when AI fails to embed the very philosophies that the humans who created it operate under. We are far ahead from the days of Yevgeny Zamyatin and Alan Turing when machines were regarded to be impartial. To breathe a new life in machines by teaching AI to be ethical is a challenge that drops to the fundamental question of what it means to be ‘human’?
We now know that to construct a perfect ethical framework, AI has to be stripped down to its bare essentials and needs to be driven a context abled approach that emphasizes on the quality of the results. As with the fundamentals of diversity in the workplace, the steps are simple:-
- Keep a close watch on the data.
- Keep it varied but normalized.
- Have a team monitor the preprocessing steps from time to time.
- Eradicate exclusions of any form in the output.
- Remove junk values that may be erroneous or useless to the model.
- Refine, audit, share and recollect results, incorporating them into the model.
- Eliminate interactions, data silos and always have sanity checks for what the objective ultimately is.
- Knockdown data silos and teach the AI to think rather than modeling it to think.
- Keep the Johari window of awareness in check. Cover unknown knowns and known unknowns. As for the unknown unknowns, such biases will always remain, unfortunately.
Must Reads:[wcp-carousel id=”10004″]