
Mining insights from unstructured data using NLP

What is NLP?
Massive amounts of data are stored in text in natural language, however not all of it directly is machine understandable. The ability to process and analyse this data has a huge scope in our current business and day to day lives. However, processing this unstructured kind of data is a complex task. Natural Language Processing (NLP) techniques provide the basis for harnessing this massive amount of data and making it useful for further processing.
A very simple example of the usage of NLP in our day to day lives is Identifying meaning from textual conversations via email.
For example, if you have received your flight ticket via email it will be added automatically to your Calendar. Another live example that we are currently working on is gathering sales signals from real time data that people are generating.
Let’s take a look at how we can build this.
NLP tasks
NLP tasks are closely braided, some of their categories in the order of processing include
- Tokenization : This task splits the text into roughly words depending on the language being used. It can identify when single quotes are part of a words, or period do or do not imply sentence boundaries.
- Sentence breaking : This task involves splitting text into sub sentences by a predefined boundary. This boundary could be a newline or a regular expression that will match something to be treated as a sentence boundary (eg: ., !, ?, <p>,<html> etc ) or you may specify the whole document to be defined as the sentence.
- Part-of-speech tagging : This next task involves classifying words within a sentence and labelling them with tags of the corresponding parts of speech.

- Lemmatization : For grammatical reasons documents may have multiple words that have similar meaning eg: “read”, “reads”, “reading”. It would be useful for a search for one of those terms to match documents containing the other. The goal of Lemmatization is to break these words down to common base word. Eg all the words will correspond to “read”
- Coreference resolution : Coreference resolution aims to map all the mentions within a text to a named entity. Eg: a person can be referred by “Anthony Hopkins” or by other expressions like “the Welsh actor”, “him”, “his”, “he”, “the 80 year old”. If we want to know the context of the expressions anywhere within a document we can generate the mapping with Coreference resolution
- Named Entity Recognition (NER) : Involves pulling names, locations, people, companies, dates, and things in general from the text and determining their context. The idea is classifying the relevant entities within the document into predefined categories by annotating them with tags. Entity extraction can add a wealth of semantic knowledge to your content. You can also build your own lists of custom entities for tracking or to train your own machine learning models for discovery purposes, to find entities specific to your domain.
- Automatic summarization : The art of creating short coherent and accurate content based on vast knowledge sources could it be articles, documents, blogs social media or anything over the web. For eg in the news feed, summarization of sentences for news articles.

There are a number of open source libraries that support NLP tasks like NLTK(Python) , Stanford Core NLP(Java, Scala), Spacy(Python) etc. However, for the rest of this article we will focus our attention on one of the above NLP tasks i.e. Named Entity Recognition. In our projects that we are currently deploying we have utilized the techniques further with the Stanford Core NLP toolkit in Java.
Named Entity Recognition (NER)
- Stanford NER Annotator
For the English language, by default, this annotator recognizes named (PERSON, LOCATION, ORGANIZATION, MISC), numerical (MONEY, NUMBER, ORDINAL, PERCENT), and temporal (DATE, TIME, DURATION, SET) entities (12 classes). Included with the stanford NER module are 3 models trained on different datasets
3 class: Annotating [Location, Person, Organization]
4 class: Annotating [Location, Person, Organization, Misc]
7 class: Annotating [Location, Person, Organization, Money, Percent, Date, Time]
You can train the models on custom training data as well to suit your custom needs. The default models that are trained on over a million tokens. The more training data you have, the more accurate your model should be. If you have to tag names of people on Indian origin(with the assumption a corpus does not already exist) for example you probably want to train your custom dataset.)
- Stanford REGEX NER Annotator
The intention of building this annotator was to have the ability to annotate those entities that could not be annotated by the Stanford NER, this is done using regular expressions over a sequence of tokens. Regex NER has a simple rule based interface where you may specify rules as labelled Entities. These rules files may have tab delimited regular expressions with the corresponding NERs. For example
Bachelor of (Arts|Commerce|Science) DEGREE
Bachelor of Laws DEGREE
These rules files will be utilised in the annotation phase to annotate matched tokens.
Adding the regexner annotator adds support for the fine-grained and additional entity classes EMAIL, URL, CITY, STATE_OR_PROVINCE, COUNTRY, NATIONALITY, RELIGION, (job) TITLE, IDEOLOGY, CRIMINAL_CHARGE, CAUSE_OF_DEATH (11 classes) for a total of 23 classes, including those of Stanford NER.
However writing explicit rules to cover all case may not always be feasible, in such cases you probably want to have an ML model integrate various sources to learn the classification of entities. Tools like RegexNER is more useful at a higher level to augment such ML models
Example Code in JAVA
//Organizing Imports
import edu.stanford.nlp.pipeline.*;
// set up pipeline properties
Properties props = new Properties();
// set the list of annotators to run in the pipeline
props.setProperty("annotators", "tokenize, ssplit, pos, lemma, ner, regexner, tokensregex");
// build pipeline
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// Prepare the document for annotation
CoreDocument document = new CoreDocument(your_document_text);
// annotate the document
pipeline.annotate(document);
// text of the first sentence
CoreSentence sentence = document.sentences().get(1);
// list of the ner tags for the first sentence
List<String> nerTags = sentence.nerTags();
- Stanford TOKEN REGEX NER Annotator
Typically in NLP systems text is first tokenized and then annotated with information eg: (Part-of-speech tagging or NER tagging). Since regular expressions are more string based, Token regex may be expressed with tokens, or parts of speech tags, or even ner tags, thereby making it more convenient and comprehensible to specify regular expressions. This gives us more abstraction in specifying patterns.
For example, one of the interesting challenges that we came across recently was to develop a market research product for a client who had outsourced software development to us. In the project, organizational data should be extracted by crawling and processing millions of online pages, picture this –
([ner: PERSON]+) /was|is/ /the?/ /CEO/
This expression will match statements with names of people who are the CEO.
The SUTime library was built using Token Regex. It is a library for finding and normalizing time expressions, ie it will convert “next wednesday at 3pm” to something like 2018-06-06T15:00 (depending on the assumed current reference time).
- Semgrex
Semgrex is a query language to query from a dependency graph that represents the grammatical relationships between the words of the text.
In such a graph the nodes in the graph are the words of the text and the edges are grammatical relationships between those nodes. A grammatical relationship holds between a governor and a dependent. The most important part of Semgrex is the ability to query through specifying relations between nodes or group of nodes in a regular expression like format.
Following is the graphical representation for the Stanford dependencies for the sentence “John took the bat.”

| VBD | Verb, past tense |
| NNP | Proper noun, singular |
| NN | Noun, singular or mass |
| DT | Determiner |
You can find the list of other POS tags here.
Following is a code snippet demonstrating the usage of SemgrexPattern in JAVA
String semgrex_pattern = "{} >/nsubj/ {}=subject > /dobj/ {}=object";
SemgrexPattern semgrex = SemgrexPattern.compile(semgrex_pattern);
SemgrexMatcher matcher = semgrex.matcher(semantic_graph);
System.out.println("subject = " + matcher.getNode("subject") + “, object = "+ matcher.getNode("object"));
OUTPUT: subject = John/NNP, object = bat/NN
The semgrex pattern in the code above finds all the pairs of nodes connected by a directed ‘nsubj’ relation in which the first node is the governor of the relation with two other nodes ie: an nsubj relation and a dobj relation. We have captured the nsub relation and named it ”subject” and also captured the dobj relation and named it “object”.
You can find a detailed explanation of the usage of Semgrex in a powerpoint presentation available here. Another Example demonstrating the usage of SemgrexPattern from the Core NLP Source can be found here
[hubspot type=form portal=3432998 id=43c818e9-ba9d-4a5e-a027-8bf8aa4b4481]
Using the NER Annotations
Now, with the extracted entities within the document and information from the other annotators(NLP modules eg POS) we can build a data structure that represents the meaning of our text expressed through the relationships between nodes and edges. This concept of a knowledge graph is a sort of a network of real world entities and their interrelations, organised with a graph.
According to Wikipedia A Semantic graph is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts. You will often hear semantic graphs referred to as “knowledge graphs”.
Building the Semantic Graph
Taking an example with the statement below:
John Lennon was born in Liverpool to Julia and Alfred Lennon
Post the Annotation Phase we get the NER tags

Followed by which we can construct a semantic graph. Below is the Graph representing the information extracted from the NLP phase. We understand that the text “Alfred” and “Julia” are persons, that “Liverpool” is a Location, that “Alfred” and “Julia” are the parents of “John Lennon”.
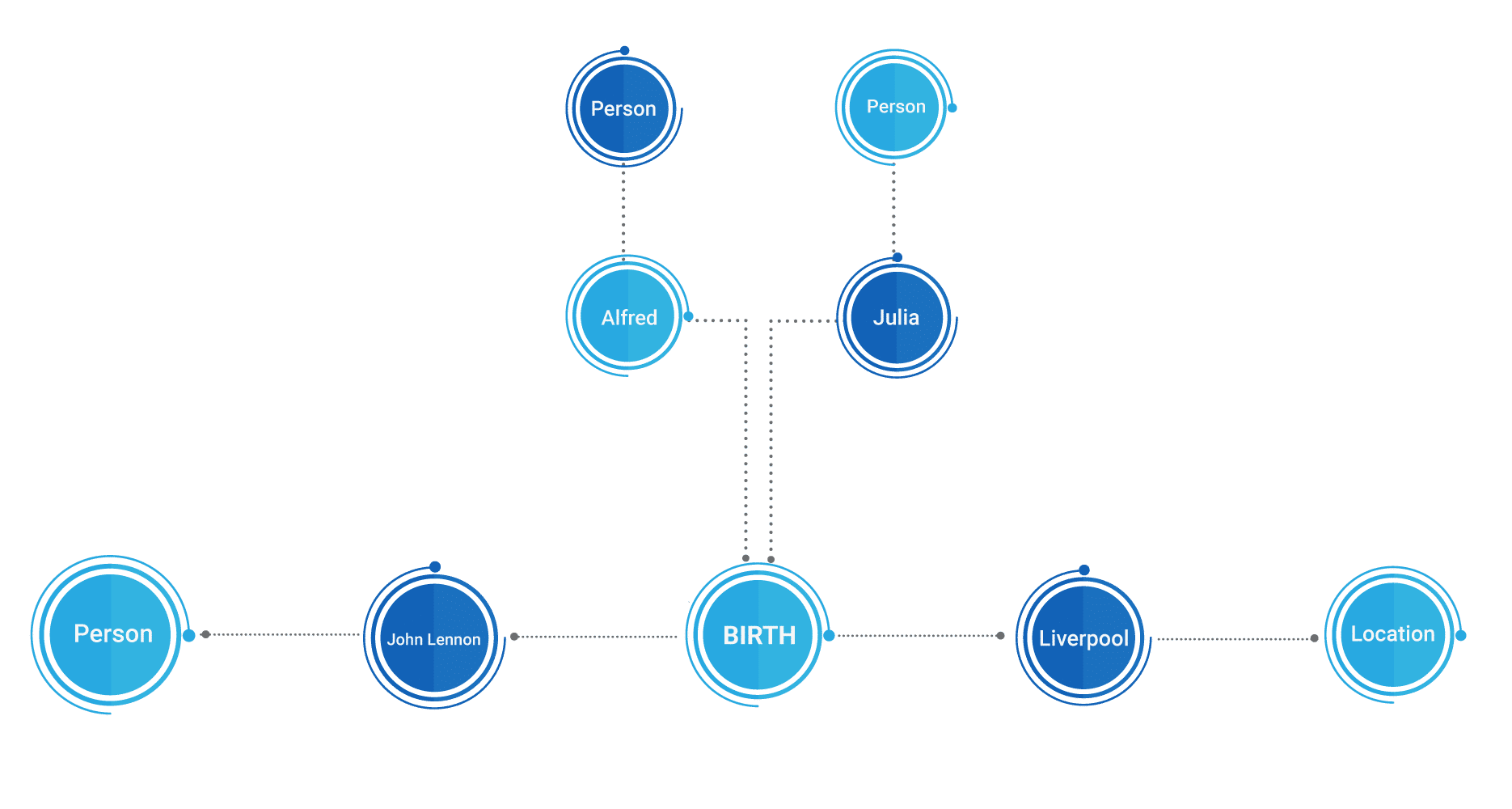
Such a graph would effortlessly help us to run queries like, What are the names of Johns Lennon’s parents? Or where was John Lennon born? Through one statement we are able to get insights, Imagine the kind of knowledge such a graph can hold while it processes and understand news articles, websites, blogs, documents etc.
Conclusion
NLP can be used in combination with other big data technologies like Spark to process and mine insights from large scale data and from multiple sources. The results may also be pipelined to multiple areas, eg: Relational Databases, Graph Databases for performing complex relationship analysis, Monitoring and alerting tools, analytics engine like spark for further big data processing or other custom software development.
In this article we have briefly walked you through –
- NLP and some of its tasks.
- How we can use NER to annotate entities and custom entities.
- An overview of how we can use this data to build a Semantic graph. The kind of insights you can obtain from this Semantic Graph is vastly profound.
Currently we are working on live projects and consulting for wide variety of domains, such as Fintech, Healthcare, Market Research etc. This approach can also be further extended to highly sensitive areas of Security, Military Intelligence, etc., and can be also be extended to other commonly used NLP frameworks, such as NLTK, Spacy etc.
Have you ever worked on unstructured datasets? What framework did you use? Did you find the article useful? Did this article solve any of your existing dilemma? Feel free to leave your comments below.
Note: A major source of inspiration of this article is the The Stanford NLP Group website. [hubspot type=form portal=3432998 id=43c818e9-ba9d-4a5e-a027-8bf8aa4b4481]