
Revolutionizing Distributed Systems with Kubernetes

When industry leaders like Cloud Foundry Diego, Amazon ECS, HashiCorp’s Nomad, and Docker Swarm were taking over the container-orchestrator market, Kubernetes was planning its grand entry. In two years, the landscape evolved, and we saw the end of many projects. Most providers either shut down their working or partially supported and integrated to Kubernetes. Many other industry influencers put their stakes on Kubernetes such as Google’s Kubernetes Engine, Microsoft’s Azure Container Service, Oracle’s Container Engine, IBM’s Cloud Container Service, and Red Hat’s OpenShift.
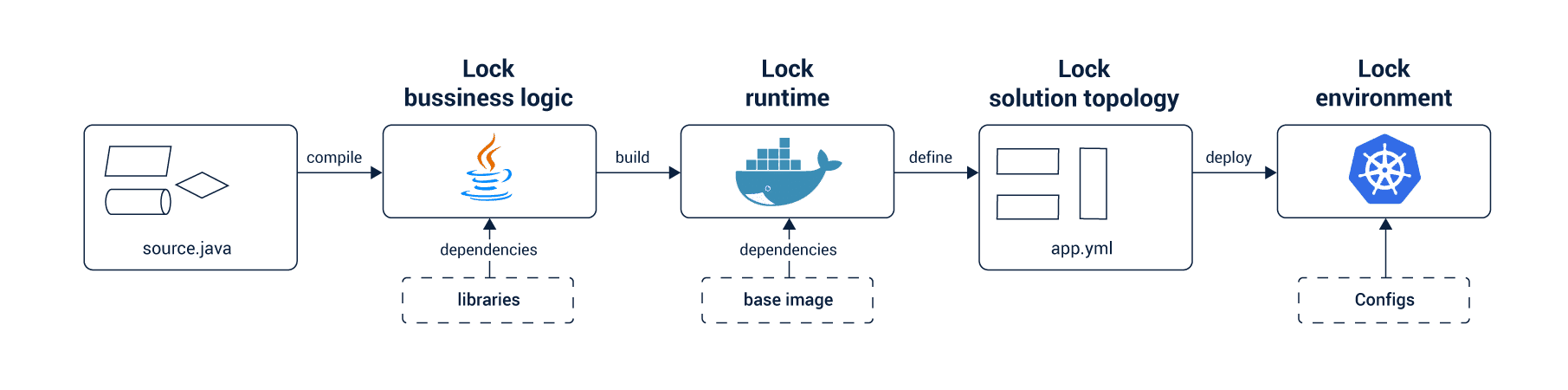
Today, we won’t dare think about any other platform for container-orchestration.
This also indicates that developers can complete 90% of their container-orchestration projects with one platform. Now, that makes a high selling point!
If you are designing or deploying applications on Kubernetes, you are achieving the independence of shifting to several cloud providers, service providers, and Kubernetes distributors. Businesses can directly look for a Kubernetes certification to hire developers who will kick-start the project and manage it.
In a real sense, Kubernetes is the portability layer of the application. Not VM or JVM, Kubernetes is the fundamental driver for automating the deployment of container applications.
The Impact of Kubernetes
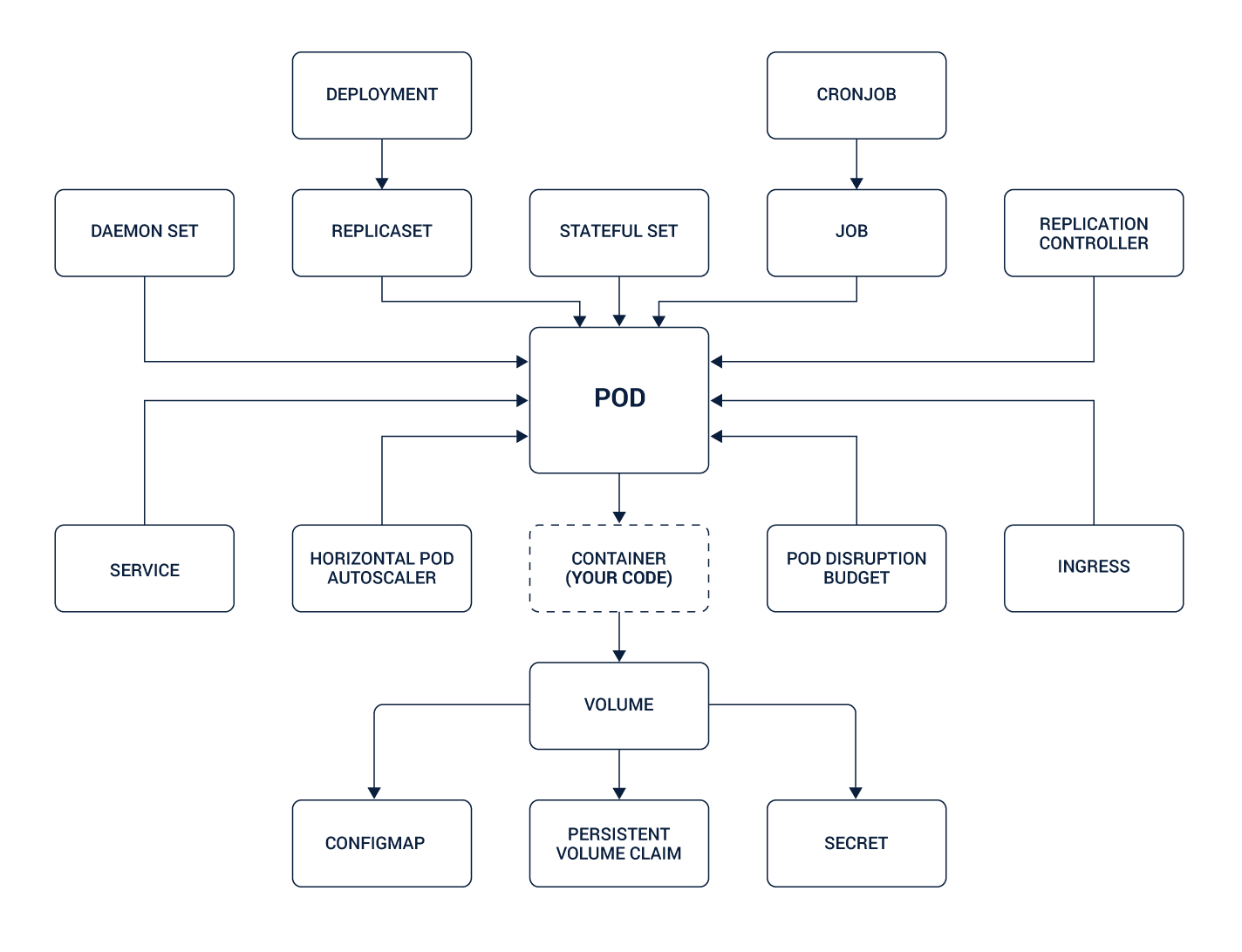
The orchestrator and container features come with a set of new primitives and abstractions. To balance the force of these primitives, we develop new design principles that can guide us. However, as we use these primitives, we solve the repeating problems yet renew the circle.
Design patterns offer a solution by solving repeating issues. Principles are fundamental but resist the change. Habits, on the other hand, change when an alteration impacts first performance. With a new feature, old patterns can become extraneous.
We also use techniques and practices regularly in container orchestrator. The methods are small tricks that help us efficiently execute a task, and practices are extensive measures. Both practices and techniques change when we figure out an enhanced way to perform tasks.
Together, the functioning of Kubernetes and the platform evolve to achieve high value from project implementations.
Let us walk you through the impact of each category given in the image below.
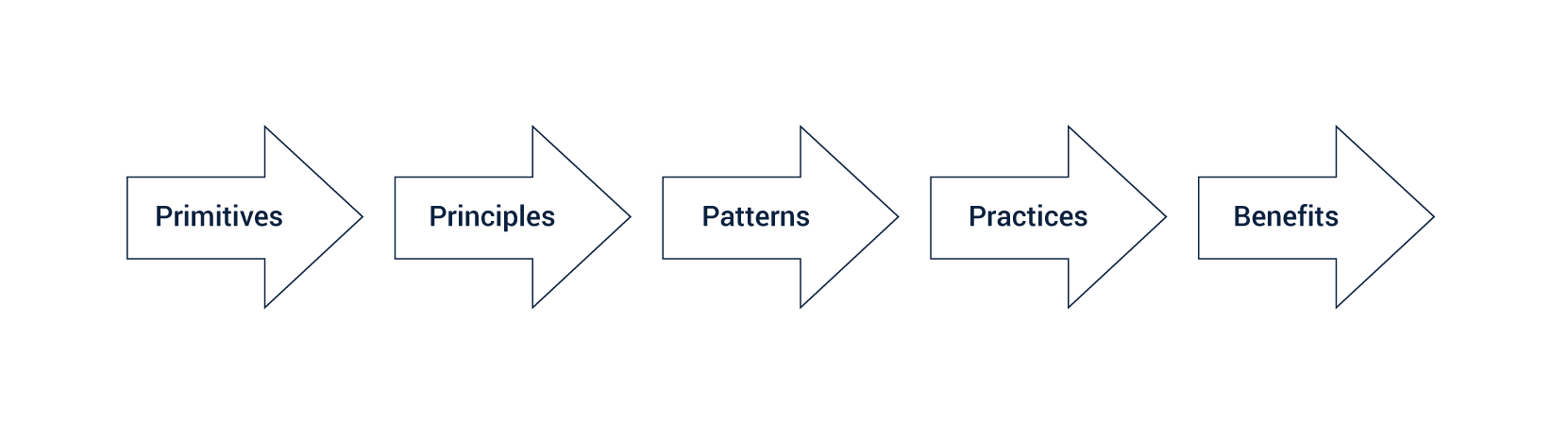
Primitives of Kubernetes
We often use OOP concepts like object, class, inheritance, encapsulation, package, polymorphism, etc. We also use Java to manage the lifecycle of the classes, objects, and the whole project. Along with Java, the JVM offers us the fundamentals for creating an application successfully.
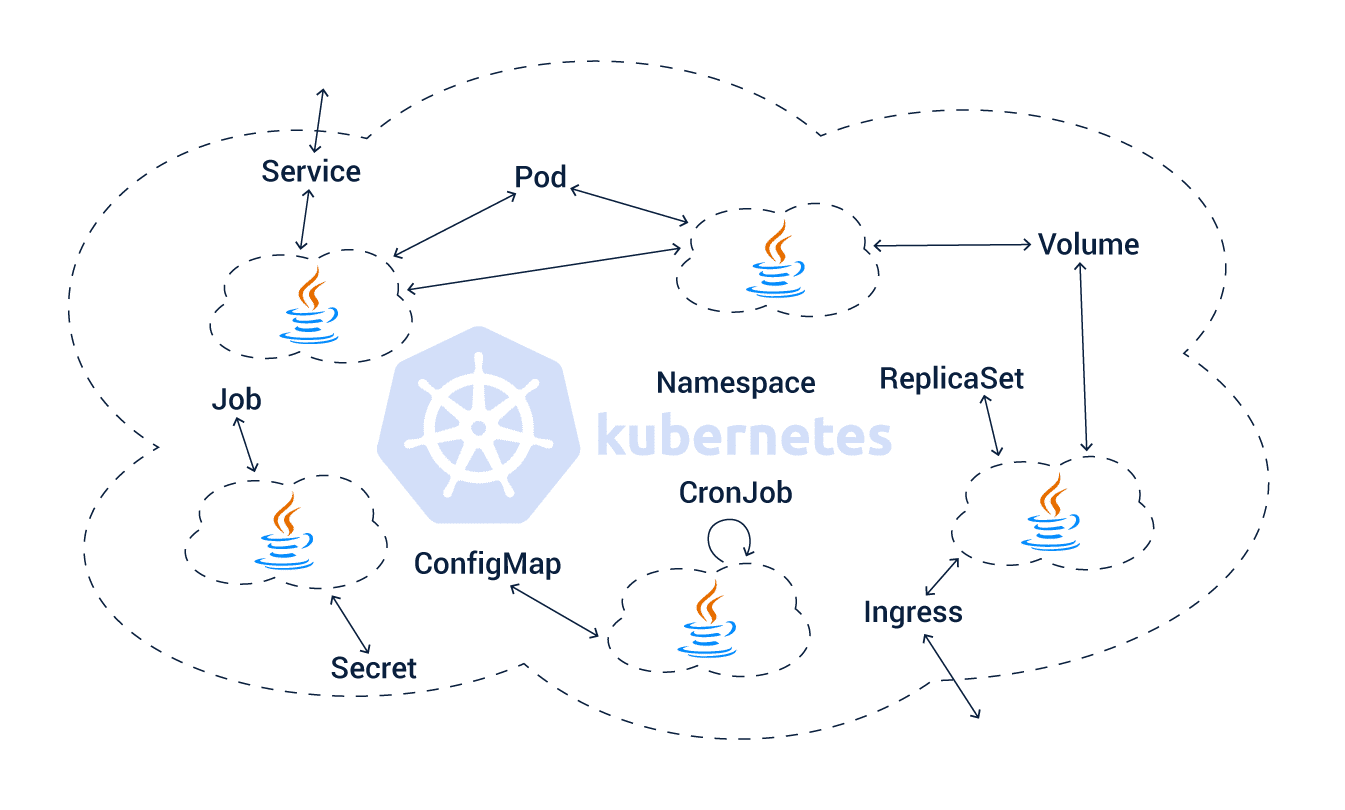
Kubernetes includes a new vertical to this functioning by providing new primitives and abstractions for designing distributed systems which expand to several nodes and processes.
Of course, we still need OOP concepts and its fundamentals to design several components and features of the distributed system. However, you don’t have to count on Java primitives entirely for developing application behavior. You can create some behavioral aspects of the application with Kubernetes primitives.
Just understand how this happens:
- A Pod is a deployment unit that helps in the container collection.
- Service is primitive for load-balancing and service discovery.
- The Job contains asynchronously scheduled work units.
- Cronjob contains periodically scheduled work units.
- Configmap is utilized to distribute configuration data to services.
- The Secret is to handle data with sensitive configuration.
- Deployment is a mechanism for declarative application release.
- A Namespace is utilized when you need to isolate resource pools.
For instance, many developers say that health checkup of Kubernetes help them establish the reliability of the application. Others believe that it is extremely feasible to utilize ConfigMap to set up configuration and CronJob to set up periodic scheduling of work units rather than Quartz library of Java or ExecutorService interface.
However, it is necessary to note that though distributed system primitives and in-process primitives have common factors, these can’t be compared or interchanged. Both primitives have separate preconditions and abstraction levels.
We can’t skip the use of classes or objects. We have to create courses and then objects to place them inside the container. But, if you look at other primitives like CronJob, which was discussed above, it has the power to replace the ExecutorService interface of Java.
The motive is to understand that the developer has a choice to utilize a rich set of global and local primitives that can enhance designing and distributed system. With regular implementations, these primitives lead us to new methods of resolving issues. Some of the routine solutions even end up becoming patterns.
Design Principles of Kubernetes
The design principles form a significant pathway for general guidelines which are necessary for designing quality software. Although these design principles are not definitive rules, these are essential for development.
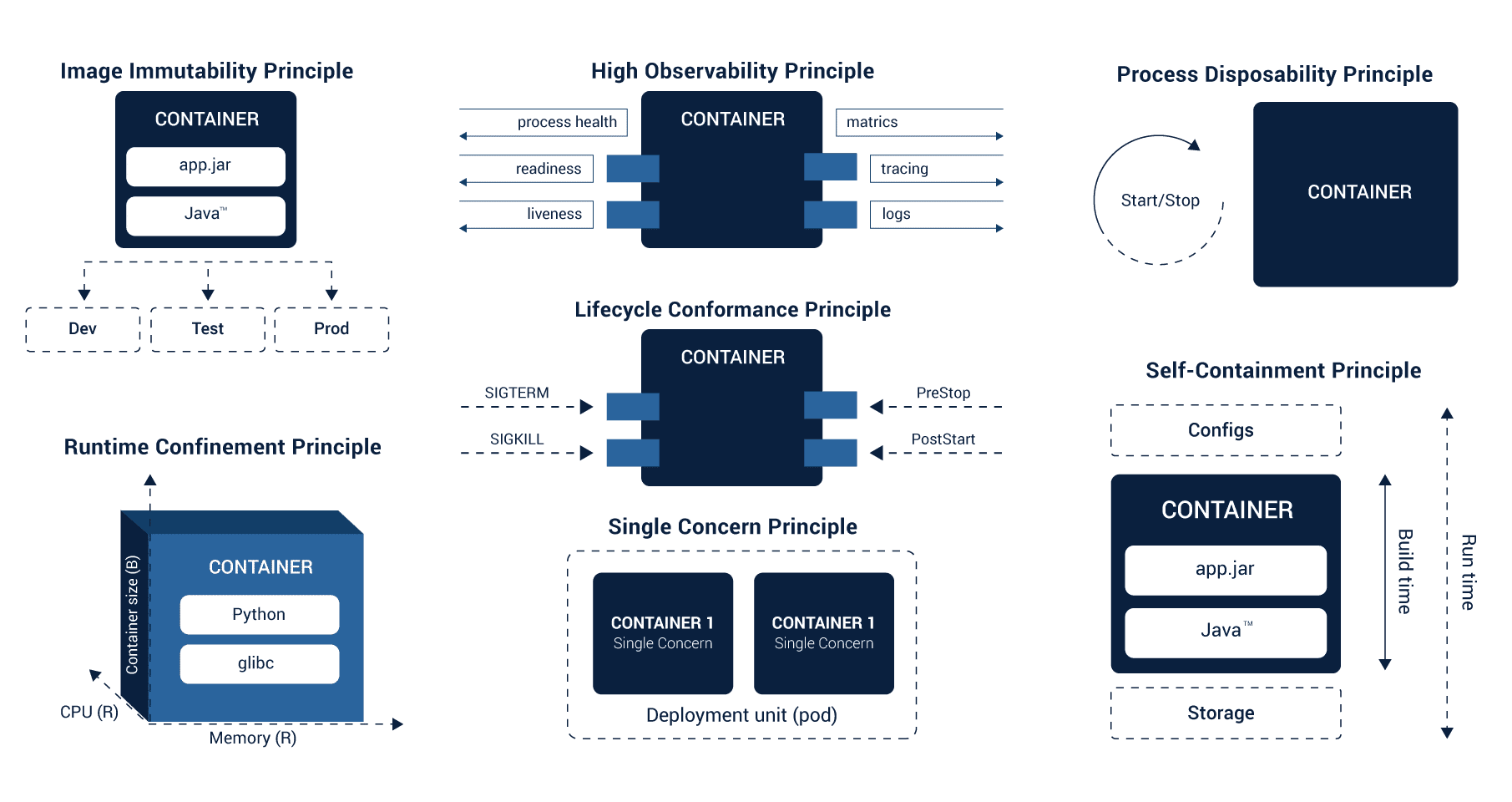
Take SOLID principles, for example. These were first introduced by Robert C. Martin to help developers form enhanced object-oriented structure. These principles use OOP primitives and well-known concepts such as inheritance, interface, and classes to develop OOP designs.
Similarly, we have several principles for containerized applications.
The principles that we have explained below utilize container in the basic primitive form and the container orchestration in the target runtime natural form.
For Building
- Every container in the distributed system should be able to resolve one problem correctly.
- Any container should be able to count on the Linux kernel. When any container is being built, important additional libraries should be added to it.
- The container applications should be developed in a manner to become unchangeable. This means that once this application is designed, it should not vary or change in different environments.
For Runtime
- Every container in the application should implement every API such that the use is managed efficiently.
- Every container should be able to read and react to the events originating from the platform.
- Every container application should be designed such that these are transitory. It means that container applications should be developed in a manner that these can be replaced with any other container instances at any time.
- The resource requirements corresponding to each container should be declared. It is necessary for the application to confine to these resource requirements.
These principles allow developers to design applications which are compatible with native cloud platforms.
You can check these principles in detail at Red Hat.
Design Patterns for Kubernetes
When we use new primitives, new principles come with the deal, as we need them to define the forces driving the primitives. Using primitives only means answering repeating problems. It helps us identify patterns (or recurrent solutions).
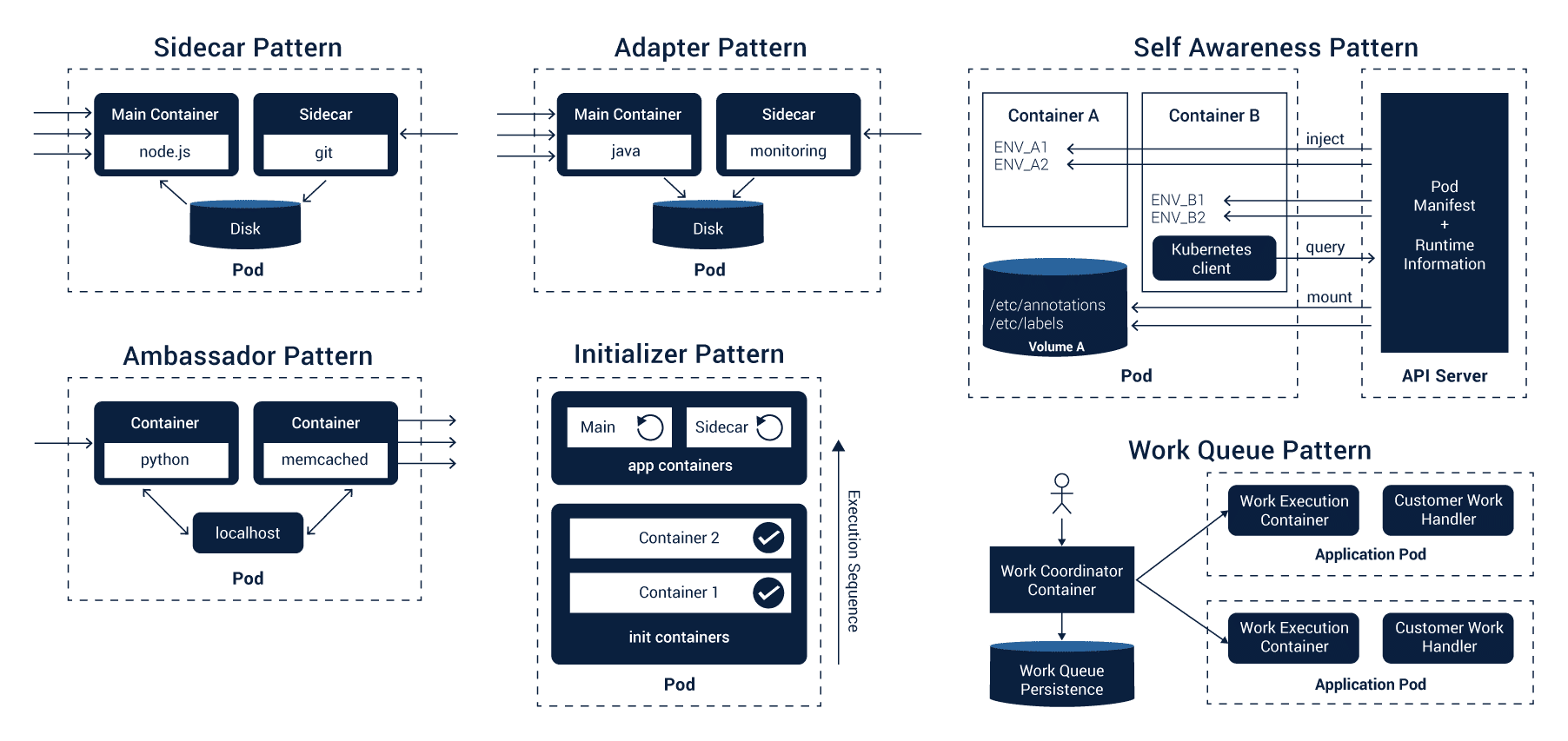
The design patterns for container aim at organizing and solving the issues of container and primitives of a distributed system. We have explained some of these design patterns which are significant for distributed systems.
- In the sidecar pattern, the sidecar container affects a previously existing container by extending its functionality without changing the container.
- The ambassador pattern helps in concealing complexity, which offers an integrated world view to the container.
- The adapter pattern is the opposite of ambassador pattern. Through this pattern, a pod receives an integrated interface fetched from the external world.
- The initialize pattern helps in isolating initialization-specific tasks from the main logic of the application.
- The work-queue pattern allows the system to process arbitrary code in the form of a container and use the random data for building a work-queue system.
- The custom-controller pattern observes the modifications happening in the objects and accordingly responds to these changes to reach the desired cluster state. This pattern is essential when you want to use custom logic and increase platform functionality.
- The self-awareness patterns help an application to figure out its metadata and running environment.
David Oppenheimer and Brendan Burns have given the comprehensive knowledge about container design patterns in their paper. Brendan Burns has also published a book which tells us about models used for developing a distributed system.
Best Practices and Techniques for Kubernetes
Apart from using principles and patterns for developing distributed systems, using industry-recommended techniques and practices help you develop robust, efficient containerized applications.
However, remember that principles and pattern don’t change as frequently. These form the fundamental blocks of containerized applications. Hence, you won’t observe many changes very often.
But, techniques and practices are susceptible to frequent changes. Whenever new, better methods surface in the industry, developers start adopting it.
Let’s discuss some best techniques and practices which are being commonly used for containerized applications currently.
- Small images decrease the size of the container, networking time, and build time. Use small photos for preventing the installation of extra packages and removing temp files.
- It is not suggested to use a pseudo command or particular user id for running your application. Utilize arbitrary user id instead.
- Of course, you mention port numbers at runtime too. But, EXPOSE command specifications makes it a notch easier for software as well as humans to utilize the image.
- If you need to save some data once the container is demolished, write this data to a volume.
- It is feasible to use images when you add image metadata through labels, tags, and annotations.
- It is necessary to synchronize several containerized applications to the host for specific attributes such as machine ID and time.
- When you log in to system streams, STDERR, and STDOUT, you should ensure proper aggregation of container logs.
- While tagging the images, ensure the backward compatibility when specifying the tag. Not achieving this can lead to risky incompatible changes.
- Avoid using more than one service inside one container such as SSHD and database. It is unnecessary as containers are already lightweight and offer to orchestrate several processes.
- If you create temporary files at the time of build process, you should remove it. For example, yum install should be followed by yum clean. You should also clean files added using ADD command.
- Wherever possible, utilize FROM command for images. This will ensure that the image automatically grabs security fixes through the upstream image whenever an update is executed.
- When you want to exclude some files, which are not related to your build, you can use the .dockerignore file. This is convenient when you are not willing to restructure the source repository.
- If you are unable to decrease the files and intermediate layers of the image, use multi-stage builds as it will allow you to reduce the final image’s size.
- Avoid installing packages which are nice to have but not required. For example, a database image doesn’t need a text editor.
- Ensure that all the containers have a single concern. This allows decoupling of applications and increases the reusability of containers.
Benefits of Kubernetes
Kubernetes defines the fundamentals of developing and designing a distributed system. The journey of learning and fully understanding Kubernetes is not short. It takes time, patience, and focus.
We will conclude this article by stating some of the valuable benefits achieved by developers who use Kubernetes regularly. Hopefully, this section will encourage you to maneuver your development strategy.
- Kubernetes offers you self-service settings, which empowers your team to use the cluster to create isolated environments instantly. These are useful for experimentation and CD/CI purposes.
- You can dynamically place your application on the cluster using a predictable pattern. This is achieved with various factors such as available resources, guiding policies, and application demands.
- Kubernetes contains rollback and upgrade processes of various containers. It makes the execution an automatable and repeatable activity. Consider these examples:
- Memory leaks such as Out of Memory (OOM).
- Infinite loops such as quotas and shares.
- Disk hogs such as quotas.
- Fork bombs such as process limits.
- Timeout, circuit breaker, and retry.
- Service discovery and failover.
- Bulkheading processes.
- Bulkheading hardware.
- Self-healing and autoscaling.
- Even without the use of in-application mediators, services can find and consume any other service. Additionally, the sidecar tools like Istio framework empowers developers to shift networking responsibilities to the platform level.
- With the help of API objects, you can define service deployments, dependencies, and resource requisites. This means you can get everything in an executable structure, which enables early testing of the implementation.
Summary
Kubernetes allows container-specific management of the distributed systems. The old method of deploying an application using an operating-system has its share of disadvantages. It entangles configurations, executables, and lifecycles. However, with Kubernetes, we have access to a new world of opportunities that allow virtualization at the OS level. The containers of Kubernetes are easier than VMs. By using Kubernetes, you can increase efficiency and application performance.