
DataSecOps – Key to Data as a Product Enablement

Most companies for the past few decades have kept their organizational data in a silo.
Analytics teams served business units, and even as data became more crucial to decision-making and product roadmaps, the teams in charge of data pipelines were treated more like plumbers and less like partners. However, now data is no longer a second-class citizen. With better tooling, more diverse roles, and a clearer understanding of data’s full potential, many businesses have come to view the entire ecosystem as a fully formed element of the company tech stack. And the most forward-thinking teams are adopting a new paradigm: treating data like a product.
What is Data as a Product
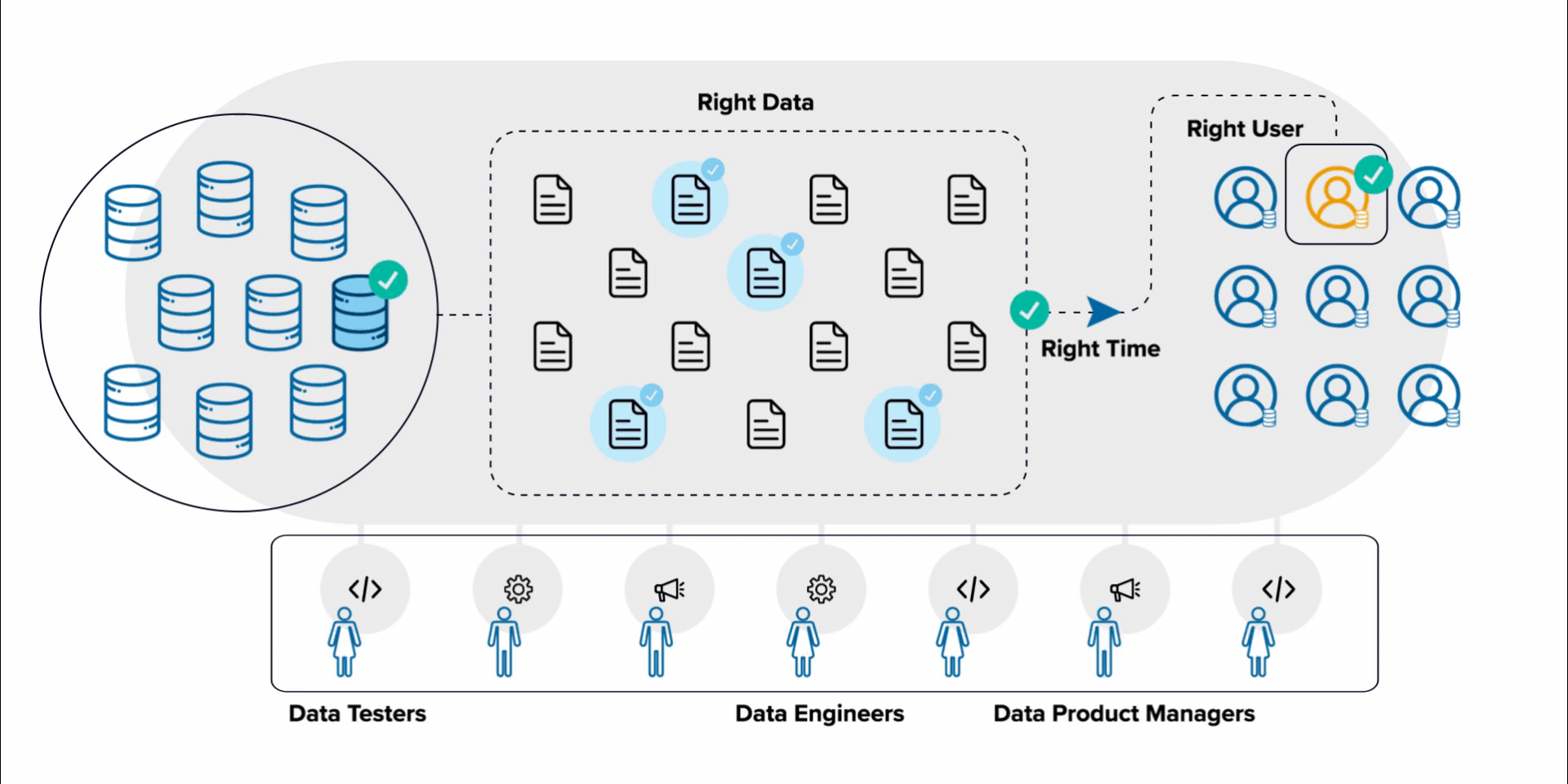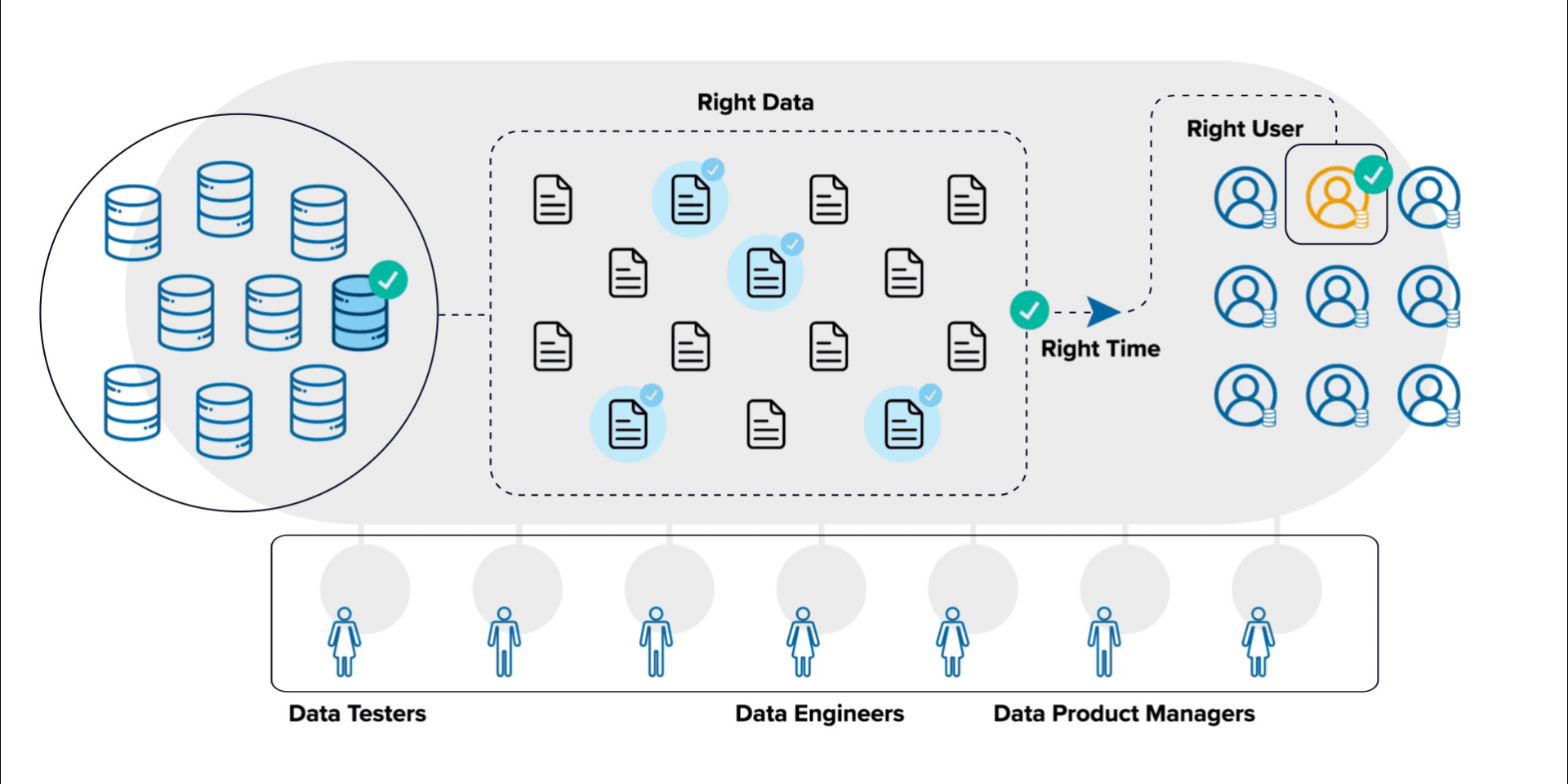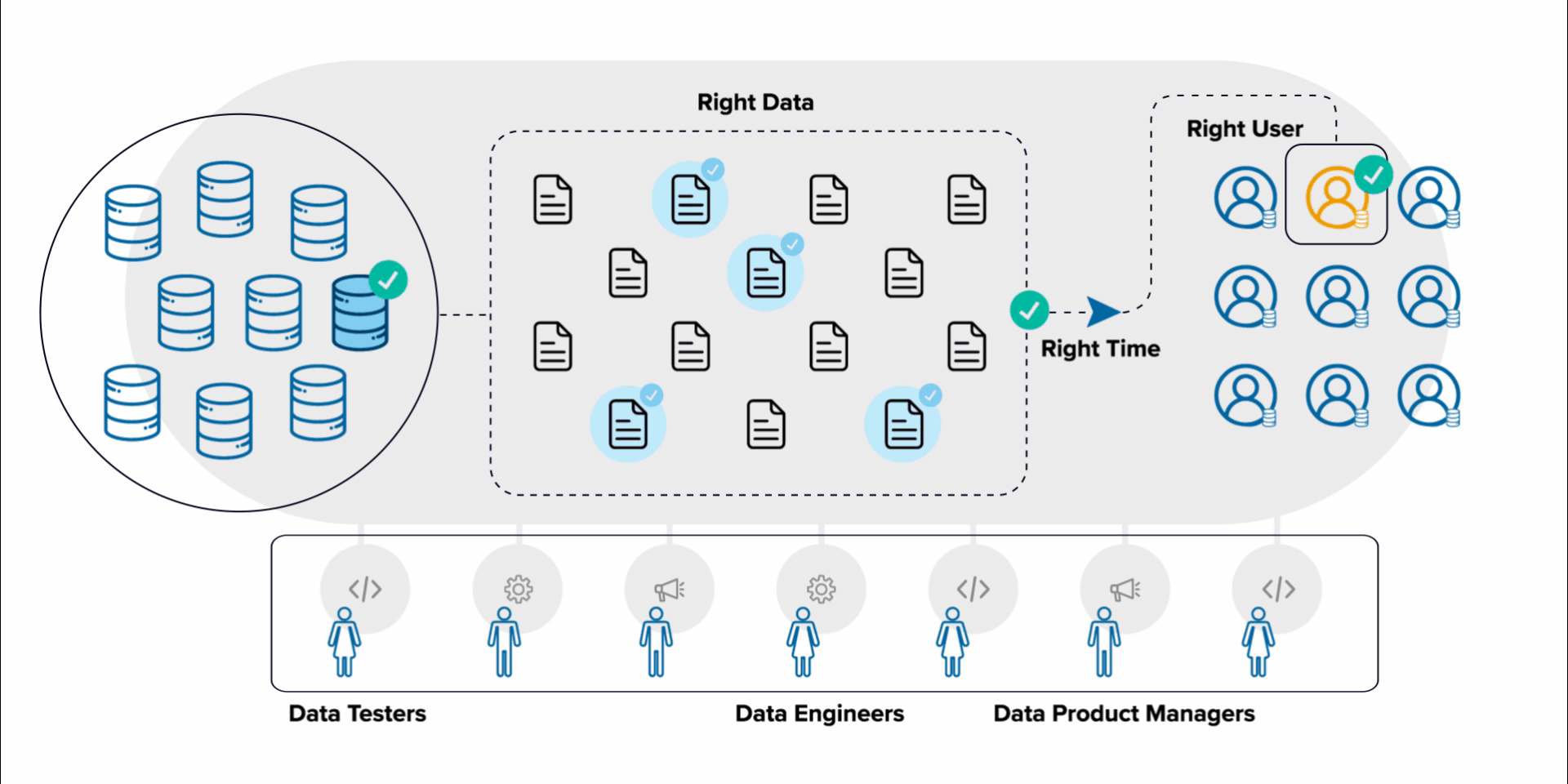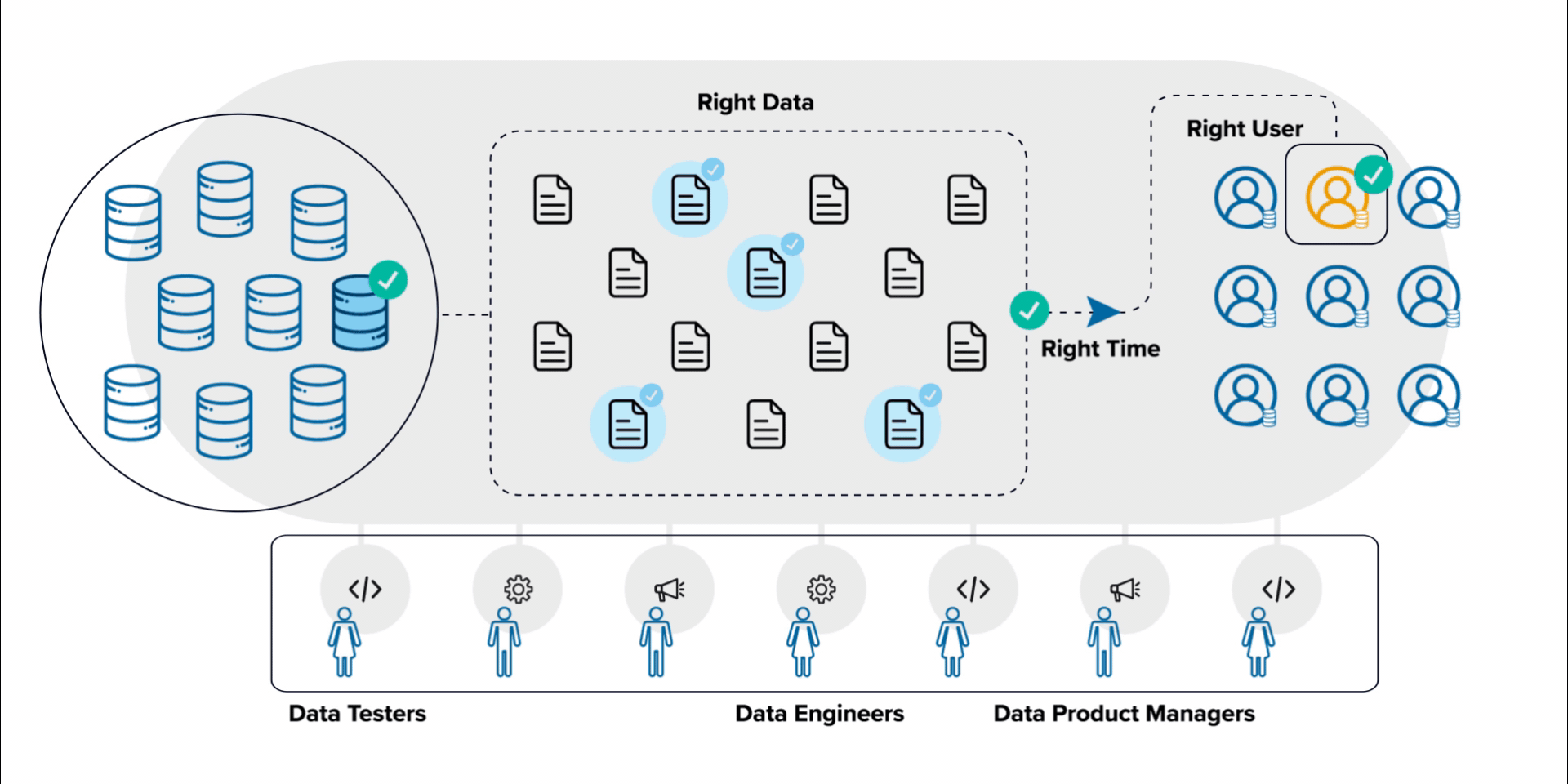
- Product thinking: A mindset that’s outcome-oriented, business-capability aligned, long-lived, and cross-functional with the intention to solve problems and improve business outcomes. Additionally, there should be a focus on discoverability, security, explorability, understandability, trustworthiness, etc.
- Data products: Using “raw data, derived data, [and] algorithms” to automate and/or guide decisions to improve business outcomes.
Data as a product is the concept of applying key product development principles (Identifying and addressing unmet needs, agility, iterability, and reusability) to data projects. It is about applying the principles of product thinking. Data as a product is a mindset that applies the principles of product thinking to create data products.
Why DataSecOps?
“History repeats itself” – things often happen in the same way as they did before, and I feel the same about DataSecOps. Before talking about what DataSecOps is and why it matters, let’s have a fast recap of what happened to application security when the industry moved to CI/CD and DevOps.
Development of software in a more agile way and transition of applications to the cloud brought DevOps, which in a few years and with several data breaches & gaps in security later sparked the realization for security that has to be embedded in the DevOps process and should not be an add-on to everything that is in place. Companies that used controlled software development life cycles had to adjust their security to the new continuous and agile deployment. This drove the philosophy or methodology and thus DevSecOps was born.
But it took a while for data to follow applications and move to the cloud. But cloud adoption for data & applications is a sure-shot deal. Even though not 100% of the organizations or 100% of the data, but data is in the cloud. And here I’m not talking about RDBMSs, key-value storage, or other databases that moved to the cloud to support the applications that migrated to the cloud.
What is Data Democratization?
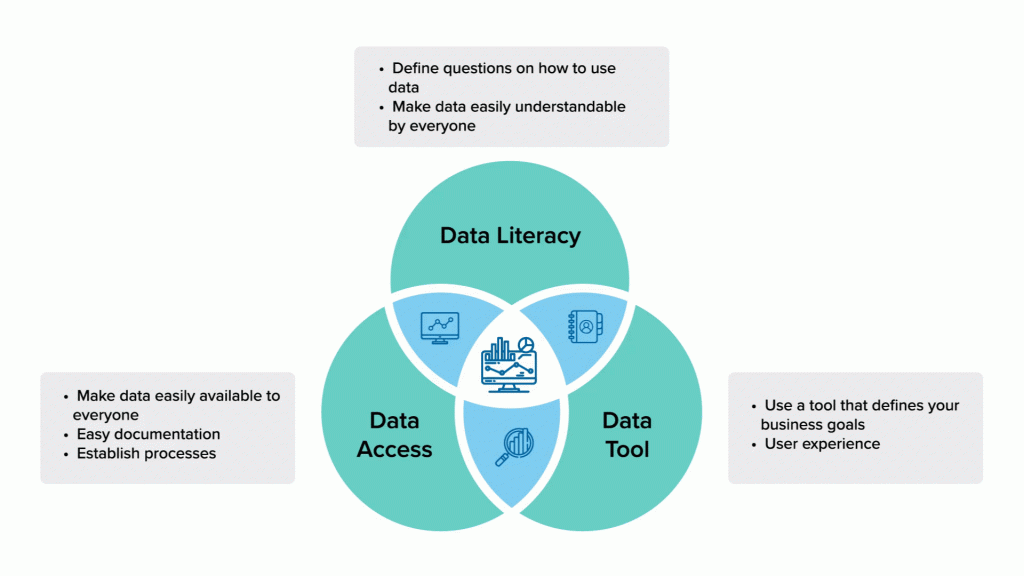
There’s no wonder that organizations are building large-scale data warehouses, data lakes, and data lake houses to the cloud as the elasticity and ability to store and process extremely large amounts of data without prior investment in servers are some of the best catalysts for data-driven innovation in the last decade. The data consumers, in many cases (such as those in Redshift, BigQuery, Athena, and Snowflake), only have to write simple queries like “select” to query data from huge tables, as if they are working on a small database. In other words, with a basic SQL skillset and capabilities of powerful BI tools, many people within the organization can make use of the organization’s data, this is what’s called “Data Democratization.”
DataOps vs. DataSecOps
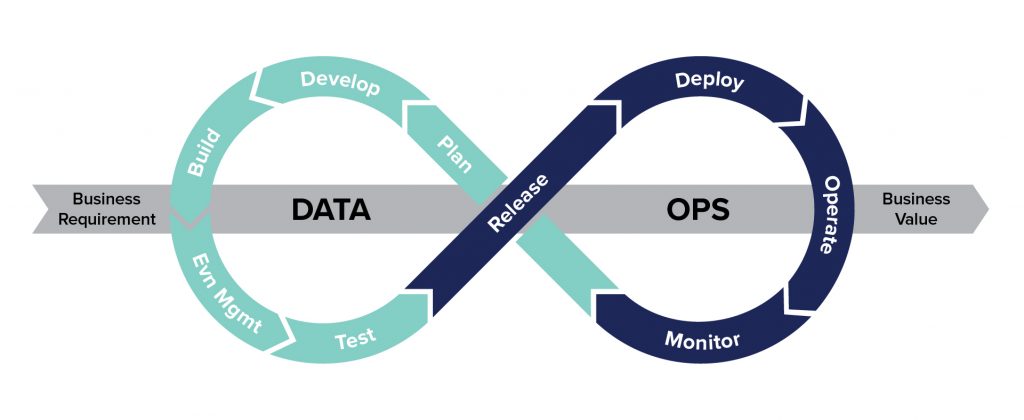
There is a widespread use of data for analytics, insights, and prediction across all teams in an organization. For example, marketing, sales, customer success, and other teams are now actively seeking new data within the organization or outside of the organization to help them achieve their business goals. This means there are both small data consumers, but also more producers, and data that is continuously changing and it’s much more agile in nature. This leads to organizations having a DataOps methodology.
There are, of course, some slightly different definitions of DataOps, but according to Gartner, DataOps is the collaborative data management practice focused on improving the communications, integration, and automation of data flows between data managers and data consumers across the organization.
The impact of DataOps adoption by organizations is a more streamlined data service that supports the data-related value propositions and is an enabler for data use as a business enabler. So, having a more continuous data life cycle with more rapid changes from DevOps and applications sounds familiar, right?
I think it’s pretty clear that what happened with DevOps is the same as what’s happening with DataOps. Operationally, the business must use its data in new ways, which means more people who put data in data stores and more people who read this data or need access to this data.
As we learned from companies diving headfirst into DevOps, we can’t allow DataOps to come without security bolted into it. In other words, without DataSecOps.
What is DataSecOps?
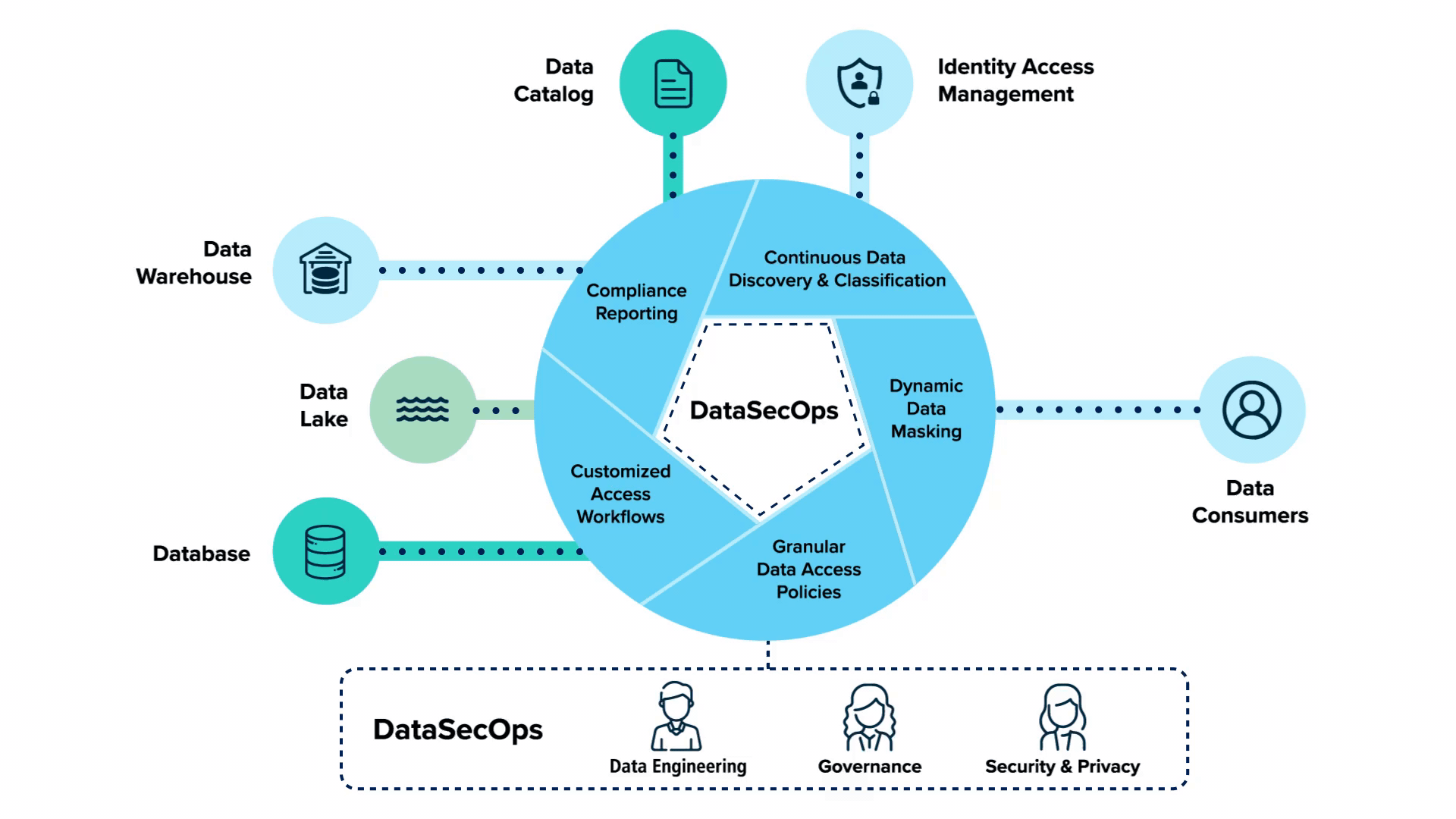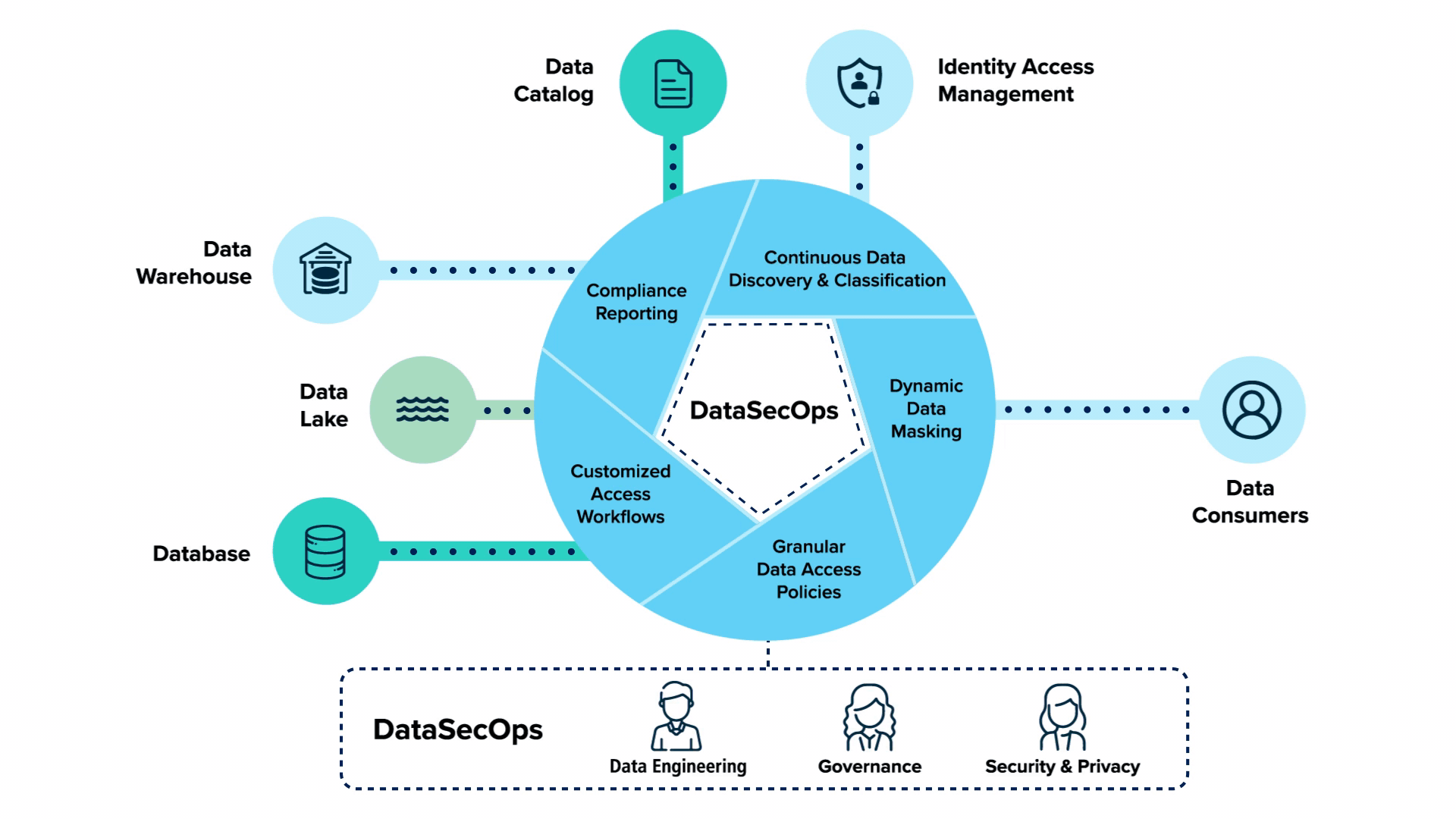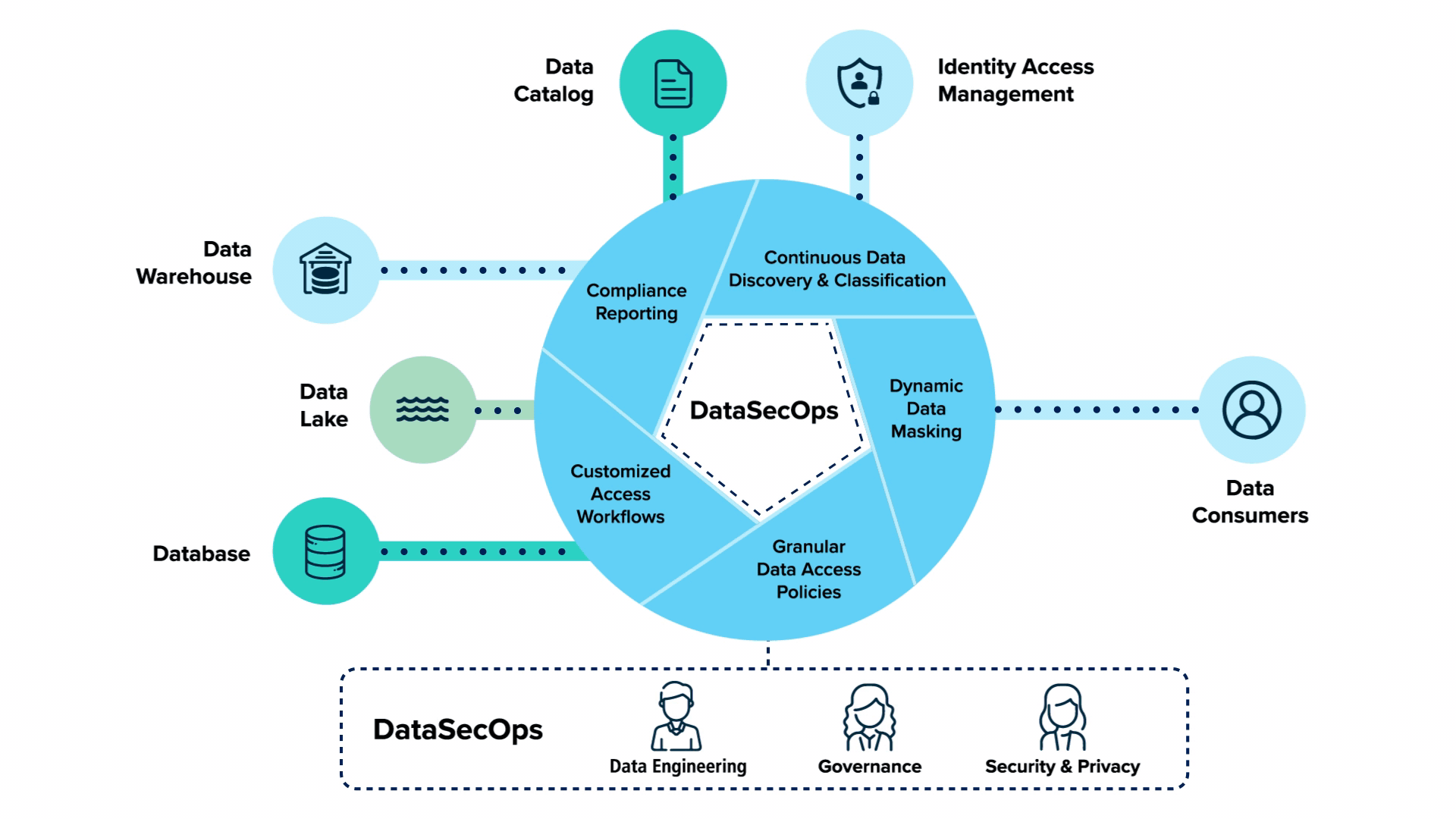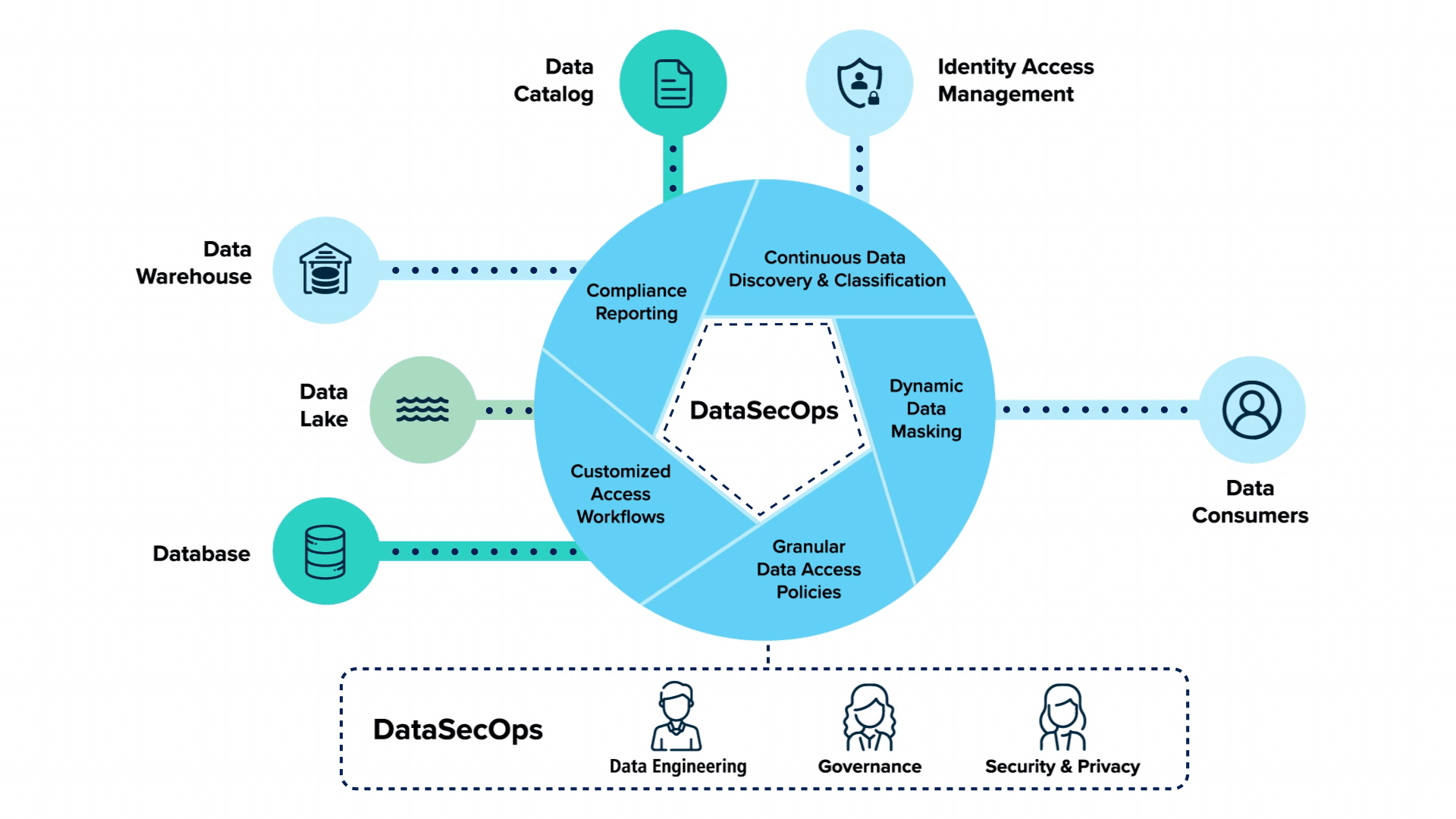
DataSecOps is an agile, holistic, security-embedded approach to coordinating the ever-changing data and its users, aimed at delivering quick data to value while keeping data private, safe, and well-governed.
DataSecOps is an evolution in the way organizations treat security as part of their data operations. It is an understanding that security should be a continuous part of the data operations processes and not something that is added as an afterthought. In fact, DataSecOps should be viewed as the enabler of data democratization processes.
5 Key Principles of DataSecOps to Enable Data as a Product
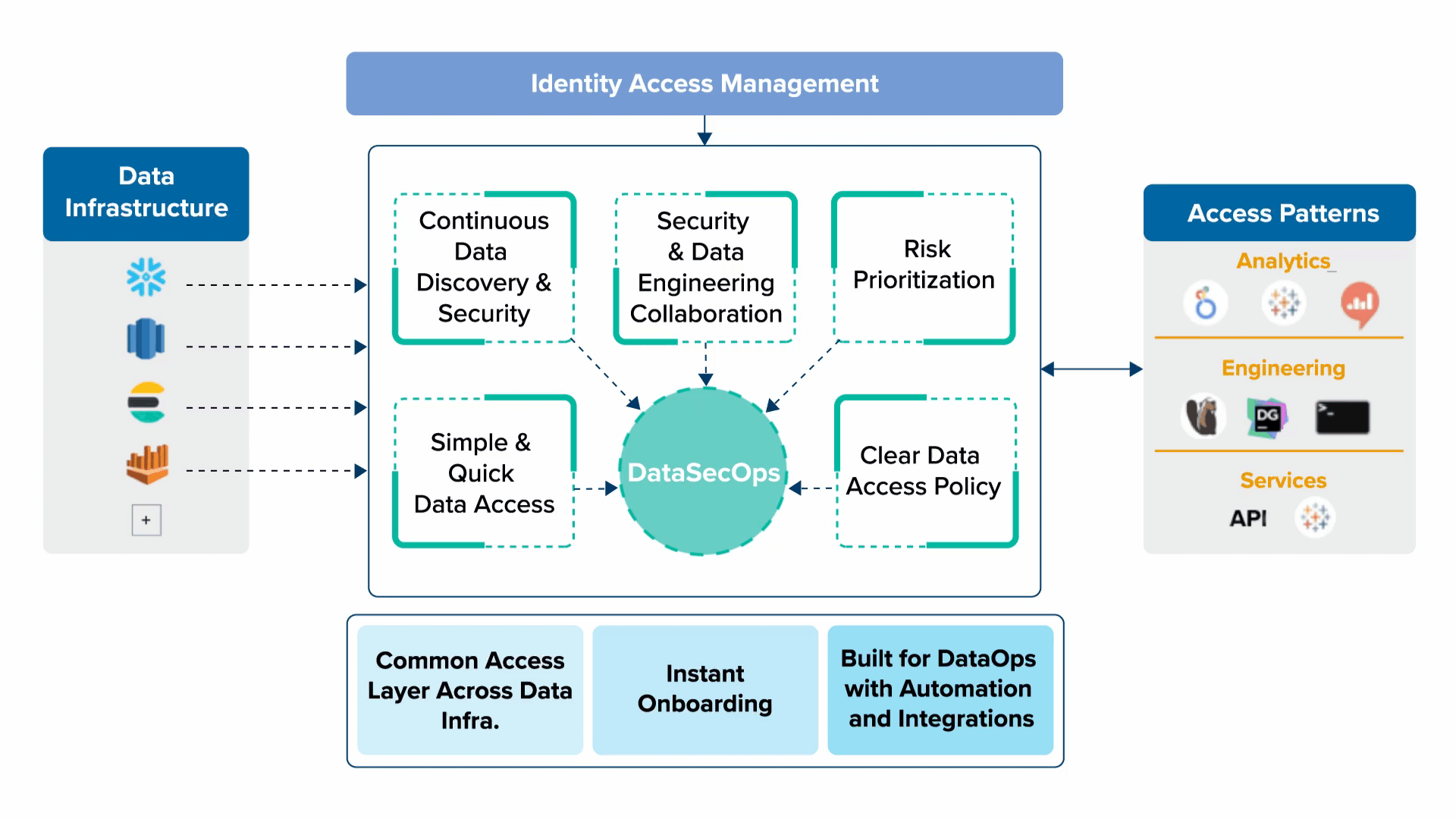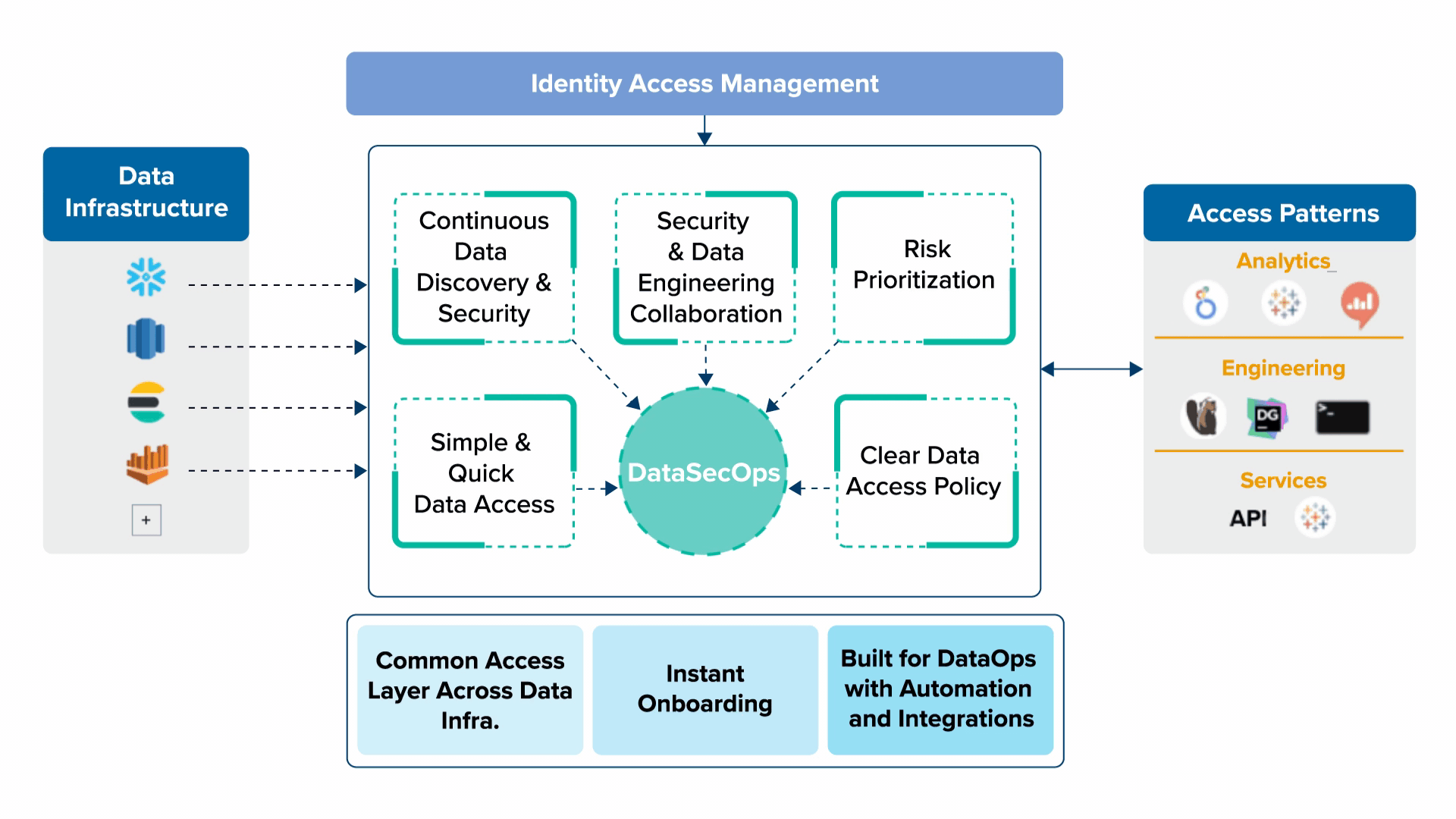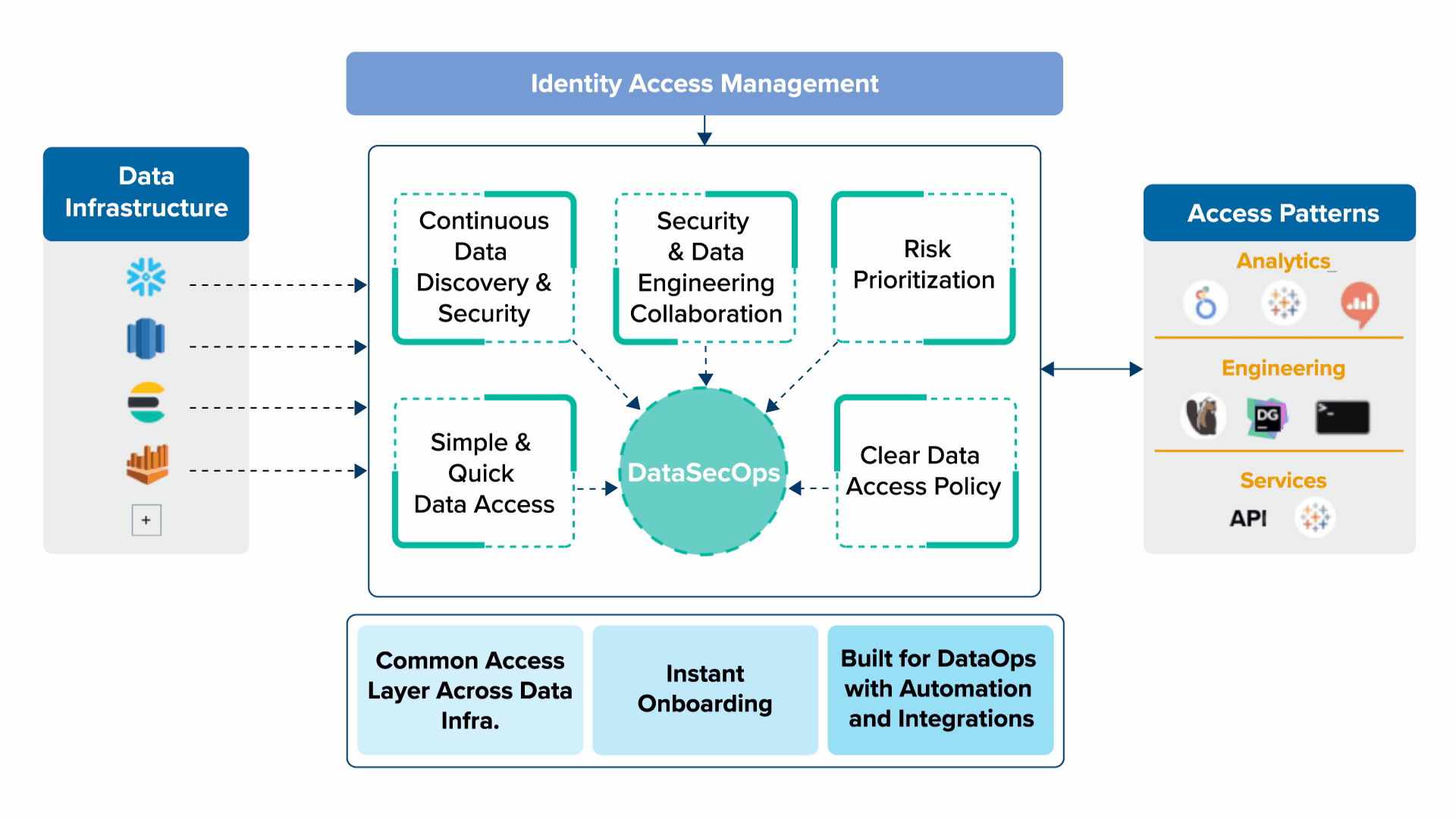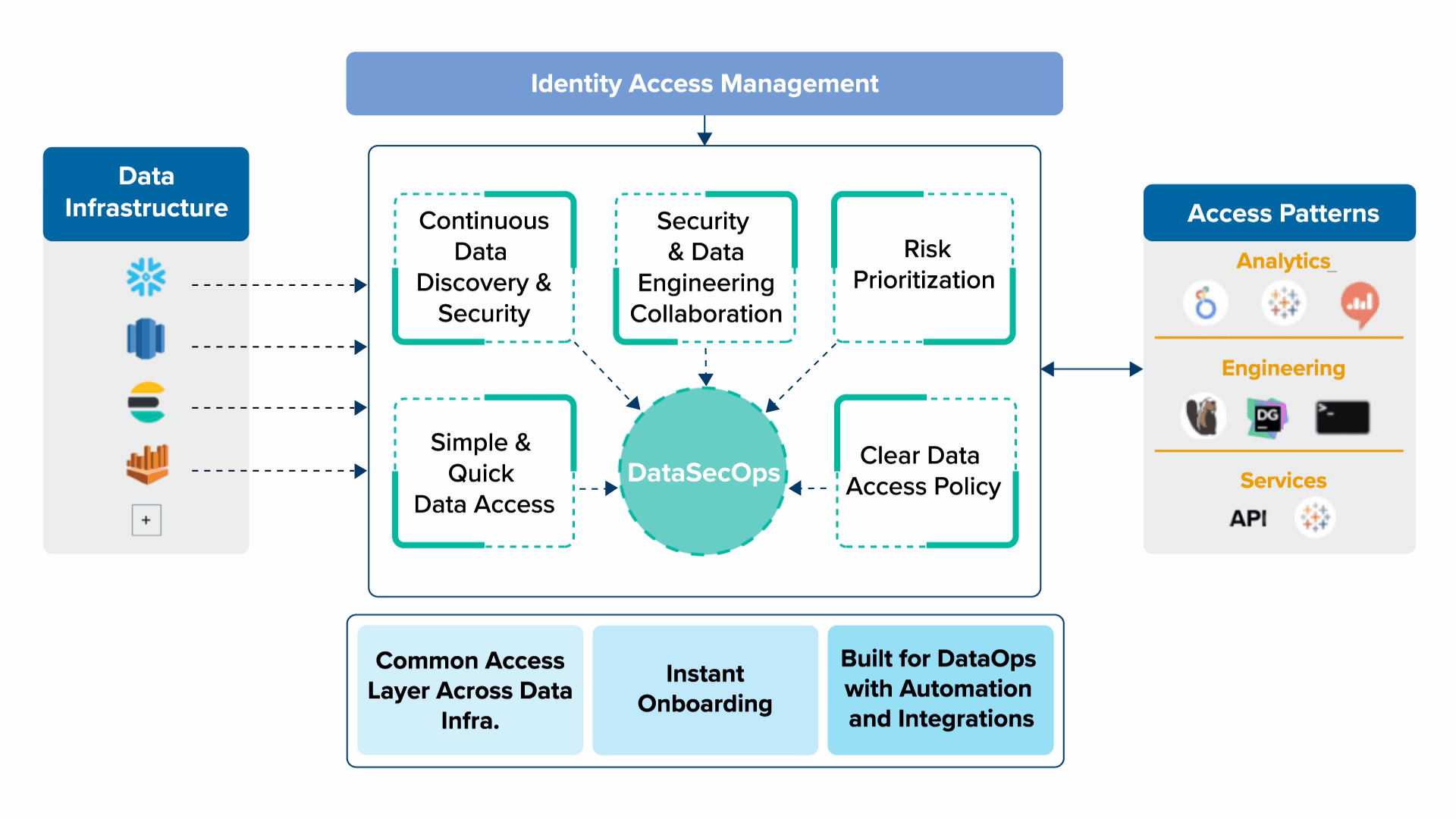
1. Continuous Data Discovery & Security
As data is changing rapidly, data privacy and protection are also fast changing. Hence always prefer continuous and gradual processes to ad hoc projects. You don’t want to go for large security and governance projects that are losing relevance fast and gaining risk until they’re done. As an example, a fully blown mapping and analysis of data access permissions, which often takes a lot of time and may change quickly, is less desired and quick incremental changes in data access are preferred.
2. Security & Data Engineering Collaboration
Security is not an afterthought rather needs to be bolted into DataOps. This means building a cross-team from the start and not just at the end of a big project by setting a stage for ongoing collaboration between security engineering, data engineering, and other relevant stakeholders. This also means that the security of data stores needs to be understood and transparent to security teams.
3. Risk Prioritization
Prioritization is key with limited resources in the ever-changing data world. You should plan and focus on the biggest risks first. In data that often means knowing where your sensitive data is, which is not so trivial and prioritizing it much higher in terms of projects and resources.
4. Clear Data Access Policy
Data access policy needs to be clear and simple when things start getting too complicated or non-deterministic around data access permissions, and by non-deterministic, I mean that sometimes you may request access and get it, and sometimes you may not get it, you’re either being a disabler for the business data usage, or you’re exposing security risks.
5. Simple & Quick Data Access
Last but definitely not least, without compromising on data security access to data should be fast and simplified. Now, this sounds challenging or even conflicting, but managing to do so with clear data access workflows and policies and things like that, will get your company quick value from data while maintaining a low level of security risks.
LTIMindtree and DataSecOps
We see what we do as facilitation of DataSecOps for organizations by allowing adding continuous visibility and security across the different data platforms of your organization with a single pane of glass.
DataSecOps is in its early stages. I’d be happy to work with clients in expanding DataSecOps and making sure organizations adopt DataSecOps and keep data secure while deriving value from it.