
Data Mesh – Rethinking Enterprise Data Architecture
In this age where self-service business intelligence rules the roost, almost every company seeks to position itself as a data-driven organization. Most businesses are acutely aware of the myriad benefits that can be leveraged by leverage to make intelligently empowered decisions. The ability to provide customers with a top-notch, hyper-personalized experience while reducing cost and capital being the most compelling.
However, organizations continue to face a range of complexities in transforming to a data-driven approach and leveraging its full potential. While migrating legacy systems, shunning legacy cultures, and prioritizing data management in a mix of ever-competing business demands are all valid constraints, the architectural structure of data platform initiatives also proves to be a major roadblock.
Siloed data warehouses and data lake architecture come with limited capabilities for real-time data streaming, and thus, undermine the organizations’ goals for scalability and democratization. Fortunately, Data Mesh – a new, transformative architecture paradigm that has created quite the stir – can give your data goals a new lease on life.
Let’s take a closer look at what Data Mesh is and how it can transform big data management.
What is Data Mesh? Data Mesh as a Software Architecture
Data Mesh essentially refers to the concept of breaking down data lakes and siloes into smaller, more decentralized portions. Much like the shift from monolithic applications toward microservices architectures in the world of software development, Data Mesh can be described as a data-centric version of microservices.
The term was first defined by ThoughtWorks consultant Zhamak Dehghani as a type of data platform architecture that is designed to embrace the all-pervasive nature of data in enterprises through its self-serve, domain-oriented structure.
As a novel organizational and architectural concept, Data Mesh challenges the traditional perspective that big data must be centralized to leverage its analytical potential. That unless all data is stored in one place and managed centrally, it cannot deliver its true value. In a 180-degree departure from that age-old assumption, Data Mesh claims that big data can fuel innovation only and only when it’s disbursed among owners of domain data, who then provide data-as-a-product.
To facilitate this, a new version of federated governance must be adopted through automation for the sake of interoperability of domain-oriented data products. The democratization of data is the key premise on which the concept of Data Mesh rests, and it cannot be achieved without decentralization, interoperability, and prioritizing the data consumers’ experience.
As an architectural paradigm, Data Mesh holds immense promise in powering analytics at scale by rapidly providing access to fast-growing distributed domain sets. Particularly, in the case of consumption proliferation scenarios such as analytics, machine learning, or development and deployment of data-centric applications.
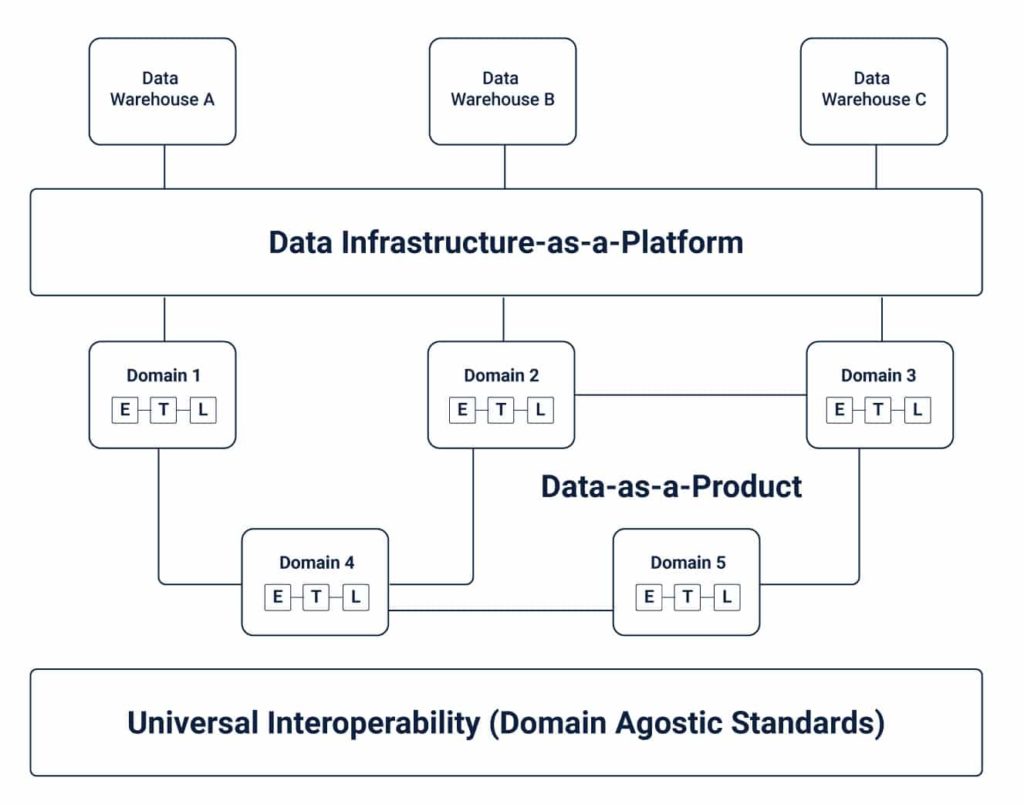
At its core, Data Mesh seeks to address the shortcomings associated with traditional platform architecture that resulted in the creation of centralized data lakes or warehouses. In sharp contrast to monolithic infrastructures for data handling where the consumption, storage, processing, and output of data is limited to a central data lake, a Data Mesh supports the distribution of data into specific domains. The data-as-a-product approach allows owners of different domains to handle their own data pipelines independently.
The tissues interlinking these domains and the data assets associated with them serve as a layer of interoperability that maintains a uniform standard of syntax and data. In essence, different pockets of data are interwoven and held together by a mesh. Hence, the name.
Problems that Data Mesh Seeks to Fix:

As mentioned before, the limitations of traditional data architecture have proven to be a major stumbling block in organizations’ pursuit of leveraging the data at their disposal for tangible gains in transforming business processes and practices. The real struggle lies in transforming mounds of data into astute, actionable insights.
Data Mesh addresses these concerns by fixing the following glaring gaps in the traditional approach to big data management:
- Monolithic platforms can’t keep up: Monolithic data platforms such as warehouses and lakes often lack the diversity of data sources and domain-specific structures needed to generate valuable insights from mounting chunks of data. As a result, crucial domain-specific knowledge gets lost in these centralized platforms. This inhibits the ability of data engineers to make meaningful correlations between different data points to generate accurate analytics that represents operational realities.
- Data Pipelines create bottlenecks: In their traditional form, data pipelines create bottlenecks owing to an isolation of the processes of data ingestion, transformation, and delivery. Different departments handling different sets of data operate without any mutual collaboration. Chunks of data of essentially being passed from one team to the other, without any scope of meaningful integration and transformation.
- Data experts working at cross-purposes: Hyper-specialist data engineers, source owners, and consumers often end up working at cross-purposes as they operate from completely divergent perspectives. This often becomes a breeding ground for counter-productivity. The root cause of this ineffectiveness is a lack of know-how for mapping analytics in a way that correlations can be established vis-à-vis business fundamentals.
3 Key Components of Data Mesh
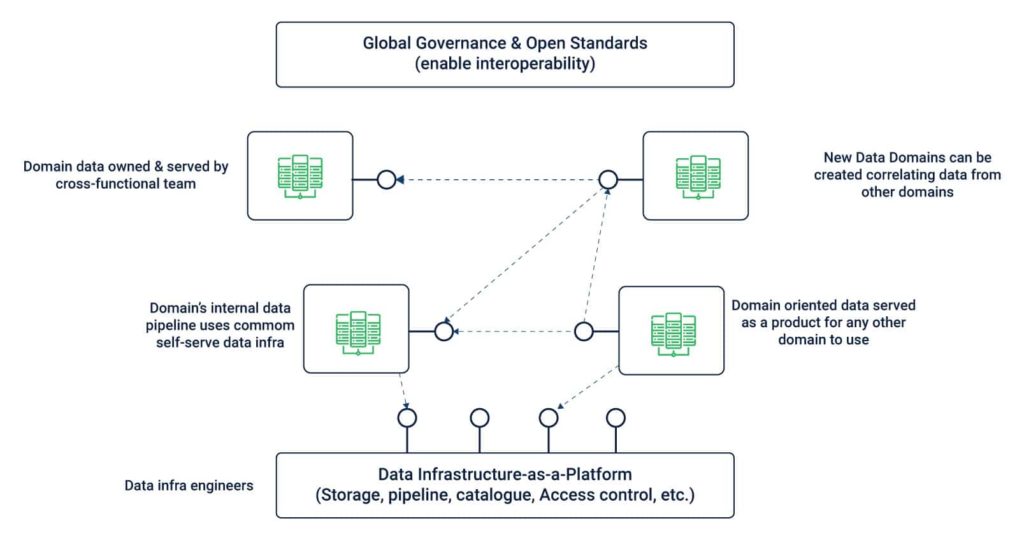
A Data Mesh requires different elements to operate seamlessly – data infrastructure, data sources, and domain-oriented pipelines. Each of these elements is essential for ensuring universal interoperability, observability, governance as well as upholding domain-agnostic standards in data mesh architecture.
The following key components play a crucial role in helping Data Mesh meet those standards:
- Domain-oriented data owners and pipelines: Data Meshes amalgamate data ownership between different domain owners who are responsible for offering their data as a product as well as facilitate communication between different locations across which data has been distributed. While every domain is responsible for owning and managing its Extract-Transform-Load (ETL) pipeline, a set of capabilities are applied to different domains to facilitate storage, cataloging, and access to raw data. Domain owners can leverage data for operational or analytical needs once it has been served to a given domain and is duly transformed.
- Self-serve functionality: One of the main concerns associated with a domain-oriented approach to data management is the duplication of efforts in maintaining pipelines and infrastructure in each. To address it, Data Mesh extracts and collects capabilities from domain-agnostic data infrastructure centrally from where data pipeline infrastructure can be handled. At the same time, each domain leverages the components needed to run their ETL pipelines, paving way for necessary support and autonomy. This self-serve functionality enables domain owners to focus on specific data use cases.
- Interoperability and standardization of communications: Every domain is supported by an underlying set of universal data standards that go a long way in paving a path for collaboration wherever necessary. This is crucial because the same set of raw as well as transformed data can inevitably be of value to more than one domain. Standardizing data features such as governance, discoverability, formation, metadata specifications enables cross-domain collaboration.
4 Core Principles and Logical Architecture of Data Mesh
The Data Mesh paradigm is founded on four core principles, each intuitively directed toward addressing the many challenges posed by the hitherto used centralized approach toward big data management and data analytics. Here’s a closer look at what these core principles entail:
- Domain-oriented decentralized data ownership and architecture: At its core, Data Mesh seeks to decentralize the responsibility of data distribution to those working closely with it for the sake of supporting scalability and continued implementation of changes. The decomposition and decentralization of data are achieved by shaking up the data ecosystem comprising analytical data, metadata, and its complementing computations. Since most organizations today are decentralized as per the domains they operate in, the decomposition of data is also done along the same axis. This localizes the outcomes of evolution and continuous changes vis-à-vis the bounded context of a domain. Hence, fostering the right ecosystem for data ownership distribution
- Data-as-a-product: One of the key challenges posed by monolithic data architectures is the high cost and friction in discovering, trusting, understanding, and using quality data. This problem could have been amplified manifold in Data Meshes considering an increase in the quantum of data domains, if not addressed right at the onset. The data-as-a-product principle was seen as an effective solution for addressing the issues of age-old data silos and the data quality in them. Here, analytical data is treated as a product, and those using this data as customers. Harnessing capabilities such as discoverability, understandability, security, and trustworthiness become imperative for data to be used as a product. Thus, become an integral aspect of Data Mesh implementation.
- Self-serve data infrastructure as a platform: Building, deploying, accessing, and monitoring data-as-a-product requires extensive infrastructure and skills to provision it. Replicating these resources for every domain created under the Data Mesh approach would be unfeasible. More importantly, different domains can require access to the same set of data. To eliminate duplication of efforts and resources, a high-level abstraction of infrastructure. That’s where the principle of self-serve data infrastructure as a platform comes into play. This is essentially an extension of the existing delivery platforms needed to run and monitor different services. A self-serve data platform comprises tools capable of supporting domain developer’s workflow with minimal specialized skill and know-how. At the same time, it must be capable of reducing costs of building data products.
- Federated computational governance: Data Mesh entails a distributed system architecture that is autonomous and built and maintained by independent teams. To get optimal value from such an architecture, interoperability between independent products is a must. The federated computational governance model offers just that. In this, a federation of data domain and platform product owners is entrusted with decision-making autonomy while working within the framework of certain globalized rules. This, in turn, translates into a healthy ecosystem of interoperability.
Why Use Data Mesh?
So far, most organizations have leveraged single data warehouses or data lakes as a part of big data infrastructure to meet their business intelligence needs. Such solutions are deployed, managed, and maintained by a small circle of specialists, who often grapple with towering technical debts. The result is a backlogged data team struggling to keep up with growing business demands, a disconnect between data producers and users, and a growing impatience among data consumers.
In contrast, a decentralized structure such as Data Mesh blends the best of both worlds – a centralized database and decentralized data domains with independent pipelines – to create a more viable and scalable alternative.
The Data Mesh is capable of addressing all the shortcomings of data lakes by facilitating greater flexibility and autonomy in ownership of data. This translates into greater scope for data experimentation and innovation, since the burden is taken off the hands of a select few experts.
At the same time, the self-serve infrastructure as a platform opens up avenues for a far more universal yet automated approach toward data standardization as well as data collection and sharing.
On the whole, the benefits of Data Mesh translate into a definitive competitive edge over traditional data architectures.
To Mesh or Not to Mesh – Is It the Right Choice for You?
Given these myriad benefits, any organization would want to leverage the Data Mesh architecture for big data management. But is it the right fit for you?
One simple way to find out is to first ascertain your Data Mesh score based on the quality of data, the number of data domains, data teams and their size, bottlenecks in data engineering and data governance practices.
The higher the score, the more complex your data infrastructure requirements, and hence, greater your need for a Data Mesh.
The Takeaway
A technological fit is one of the major considerations for any organization’s efforts for adopting and implementing a Data Mesh-based strategy for data management. To be able to embrace Data Mesh architecture successfully, organizations need to restructure their data platforms, redefine the roles of data domain owners, and overhaul structures to make data product ownership feasible, and transition to treating their analytical data as a product.