
Top 10 Big Data Tools for 2021!

In today’s tech world, data is everything. As the focus on data grows, it keeps multiplying by leaps and bounds each day. If earlier mounds of data were talked about in kilobytes and megabytes, today terabytes have become the base unit for organizational data. This coming in of big data has transformed paradigms of data storage, processing, and analytics.
Instead of only gathering and storing information that can offer crucial insights to meet short-term goals, an increasing number of enterprises are storing much larger amounts of data gathered from multiple resources across business processes. However, all this data is meaningless on its own. It can add value only when it is processed and analyzed the right way to draw point insights that can improve decision-making.
Processing and analyzing big data is not an easy task. If not handled correctly, big data can turn into an obstacle rather than an effective solution for businesses. Effective handling of big data management requires to use of tools that can steer you toward tangible, substantial results. For that, you need a set of great big data tools that will not only solve this problem but also help you in producing substantial results.
Data storage tools, warehouses, and data lakes all play a crucial role in helping companies store and sort vast amounts of information. However, the true power of big data lies in its analytics. There are a host of big data tools in the market today to aid a business’ journey from gathering data to storing, processing, analyzing, and reporting it. Let’s take a closer look at some of the top big data tools that can help you inch closer to your goal of establishing data-driven decision-making and workflow processes.
Top 10 Big Data Tools That You Can Use in 2021
The importance of big data in the current ecosystem has been reiterated over and over again. However, this big data is redundant without the right set of tools to support every step of data processing and analysis. While the number of big data tools available to businesses today is growing exponentially, not all of these tools are created equal.
To pick the best big data tools, you need to consider factors such as the size of datasets, nature of analytics required, the pricing of the tool, among others. Based on these parameters, you can choose from any of these top 10 big data tools to speed along the process of analysis while lowering the cost
- Apache Hadoop
Apache Hadoop is among the most popular tools in the big data industry. An open-source framework developed by Apache, it runs solely on commodity hardware and is used for big data storage, processing, and analysis.
Hadoop, a Java-based software, relies on clustered architecture to enable parallel data processing on multiple machines simultaneously.
It consists of three parts: The Hadoop Distributed File System (HDFS), which is the storage layer, Map Reduce that handles data processing, and YARN, which is designed for resource management.
Hadoop Features:
- It can authenticate improvements with an HTTP proxy server.
- Supports the POSIX-style file system extended attributes.
- Offers a robust ecosystem for analytics capable of meeting the developers’ needs.
- Makes data processing more flexible.
- Facilitates faster processing of data.
- However, Hadoop lacks real-time processing capabilities.
- Inability to do in-memory calculations is it’s another limitation.
Hadoop Use Cases:
- Building and running applications that rely on analytics to assess risks and create investment models.
- Creating trading algorithms.
- Data analytics for improving customer service.
- Predictive maintenance of IoT devices and other infrastructure.
- Apache Spark
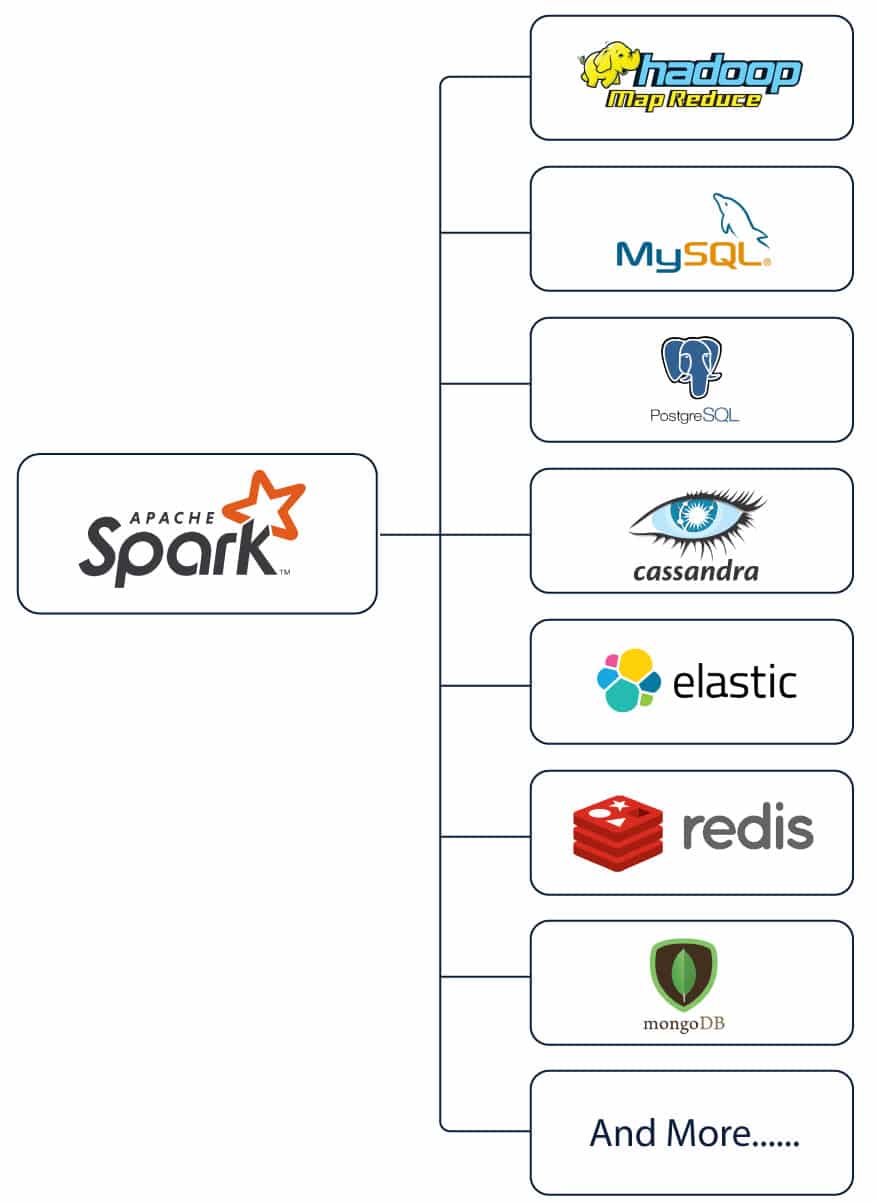
Spark is often considered to be a successor to Hadoop, as it fills the gaps of its many drawbacks. For instance, unlike Hadoop, Spark supports both batch processing and real-time analytics. It also supports in-memory calculations, thus yielding results at least 100 times faster than Hadoop, thanks to a reduction in the number of read and write processes. Spark is also a more versatile and flexible tool for big data crunching, capable of working with an array of data stores such as Apache Cassandra, OpenStack, and HDFS.
Besides offering sophisticated APIs in Scala, Python, Java, and R, Spark also comes with a set of tools that can be used for a host of features, ranging from structured data and graph data processing to Spark Streaming and machine learning analysis.
Spark Features:
- Fast-paced processing
- Easy to use
- Supports complex analytics
- Real-time stream processing
- Flexibility
- In-Memory Computation
Spark Use Cases:
- With Spark, ETL (Extract, Transform, Load) data can be cleaned and aggregated continually before being transferred to data stores.
- Combines live data with static data, allowing more well-rounded real-time analysis.
- Detects and addresses unusual behaviors quickly, thus eliminating potential serious threats.
- In machine learning, it can perform common functions such as customer segmentation, predictive intelligence, and sentiment analysis.
- Its interactive analysis capabilities are used for processing and interactively visualizing complex data sets.
- Flink

Flink is another open-source distributed processing framework for big data analytics used primarily for bounded and unbounded data streams. Written in Scala and Java, it offers high accuracy analysis even for late-arriving data. This stateful tool stands out for its ability to bounce back from faults easily, thus delivering highly efficient performance at a large scale.
Flink Features:
- Accurate results, even for late-arriving or out-of-order data
- Fault-tolerant
- Ability to run on thousands of nodes
- Low latency and high throughput
- Supports stream windowing and processing
- Support wide array of connectors to third-party resources such as data sinks and sources
Flink Use Cases:
- It is used to support continuous streaming as well as batch analytics.
- Its Gelly library offers building blocks and algorithms for high-performance, large-scale graph analytics on data batches.
- Flink’s SQL interface (Table API) can perform data enrichment and transformation tasks and supports user-defined functions.
- It provides diverse connections to storage systems such as Elasticsearch, Kinesis Kafka, and JDBC database systems.
- Its continuous file system sources can be used to monitor directories and sinks writing files in a time-bucketed fashion.
- Apache Storm

Apache Storm is also an open-source tool for big data analytics used for processing unbounded data streams. This fault-tolerant processing system distributed in real-time is not only compatible with all programming languages but also supports JSON-based protocols. Even with high processing speeds and sophistication, Storm is easily scalable and highly user-friendly.
Storm Features:
- It can process one million 100 byte messages per second per node.
- Uses parallel calculations across a cluster of machines.
- Automatically restarts in case of a node failure and transfers work to another node.
- Processes each data unit at least once.
- Extremely easy-to-use big data analytics tool.
Storm Use Cases:
- It can be used to process unbounded streams of data
- Real-time analytics
- Continuous computation
- Online machine learning
- ETL
- Distributed RPC
- Apache Cassandra

Cassandra is a distributed database known for its ability to offer high scalability and availability without impacting performance efficiency. It works seamlessly with different types of data sets, be it unstructured, semi-structured, or structured. Tolerant to faults on cloud infrastructure as well as commodity hardware, it’s best suited for processing mission-critical data.
Cassandra Features:
- Low latency for users that facilitates replicating across multiple data centers.
- High fault tolerance supported by the ability to replicate data to multiple nodes.
- Most suitable for data-critical applications.
- Offers third-party support services and contracts.
Cassandra Use Cases:
- Writing exceed reads by a large margin
- Transaction logging
- Tracking
- Storing data from health trackers
- Maintaining status and event history for IoT
- MongoDB

MongoDB is a NoSQL database, open-source tool for big data analytics with cross-platform compatibility. These features make it the right fit for businesses that rely on fast-moving data and real-time analytics for decision-making. It is also ideal for those who want to adopt data-driven solutions.
As a user-friendly, cost-effective, and reliable tool with easy installation and maintenance, it can be a great start point for an organization’s digital transformation journey. Written in JavaScript, C, and C++, it facilitates efficient management of unstructured or dynamic data. However, its processing speed has been questionable for certain use-cases.
MongoDB Features:
- Easy to use, with a short learning curve
- Supports multiple platforms and technologies
- Seamless installation and maintenance
- Cost-effective
- Reliable
- Slow speed in certain use cases has been a known drawback
MongoDB Use Cases:
- Real-time single view of most critical data
- IoT data analytics
- Fast and efficient mobile app development
- Personalization of content presented to users
- Offloading workflows from mainframe
- Modernizing payment architectures
- Kafka

Kafka is an open-source platform for distributed event processing or streaming, known for its ability to offer high throughput to systems. It can efficiently handle trillions of events every day. As a streaming platform too, it is highly scalable and exhibits great fault tolerance.
Its streaming process entails publishing and subscribing to streams of records evenly to different messaging systems, as well as storing and processing the records. Another highlight of Kafka is that it comes with a zero-downtime guarantee.
Kafka Features:
- Offers scalability for event producers, processors, consumers, and connectors
- Can handle high volumes of data streams with ease
- High fault tolerance and an ability to handle failures with both masters and databases
- Its use of distributed commit log makes it highly durable
- Stability in performance
- Zero downtime
Kafka Use Cases:
- As a message broker
- Building activity tracking pipelines
- Operational monitoring of data
- Event sourcing
- Stream processing
- External commit log for distributed systems
- Tableau

Tableau is among the premier software solution and data visualization tools that have been designed to unleash the true power of your data. It transforms raw data into useful insights capable of adding value to the decision-making process. It not only offers rapid data analytics but also presents them in the form of interactive worksheets and dashboards that are easy to read and comprehend.
Tableau is often used in tandem with other big data tools like Hadoop.
Tableau Features:
- Flexibility
- Visualization of data
- Data blending capabilities
- Speedy data analytics
- No-cade data queries
- Mobile-ready, shareable, interactive dashboards
Tableau Use Cases:
- Asset inventory of hardware and software
- Resource allocation
- Improving call volumes and resolution times
- Budget planning
- Security patch compliance
- Lead generation
- Campaign and web engagements
- Sales pipeline coverage
- Operational management of facilities
- RapidMiner
RapidMiner is a cross-platform tool that creates a robust environment for Data Analytics, Data Science, and Machine Learning procedures. This integrated platform offers support for complete data science life cycles, right from data preparation to predictive deployment models.
This open-source tool is written in Java and offers high efficiency even in the case of integration with cloud services and APIs. RapidMiner is supported by robust data science algorithms and tools.
RapidMiner Features:
- Supports multiple methods of data management
- Integrates with in-house databases
- Predictive analytics
- Batch processing or GUI
- Remote analysis processing
- Shareable, interactive dashboards
- Data filtering, merging, and aggregation
- Building and validating predictive models
RapidMiner Use Cases:
- Creating 360-degree customer views that facilitate highly personalized and efficient interactions.
- Combining and analyzing huge volumes of data at extremely high speeds.
- Identifying potential anomalies in service opportunities.
- Risk analysis.
- Eliminating false positives, thus reducing outcome uncertainties.
- R Programming
R is an open-source programming language that serves as a comprehensive big data tool for statistical analysis. This multi-paradigm programming language facilitates a dynamic environment for development. R is written in Fortran and C and offers a vast package ecosystem that contributes to its popularity as a tool for statistical analysis.
The results of its statistical analysis can be presented in the text as well as graphical formats, making them easier to decipher.
R Features
- It offers comprehensive packages for statistical analysis
- Vast package ecosystem
- Unmatched charting and Graphics benefits
R Use Cases
- Risk Measurement
- Time-series and autoregression analysis
- Credit risk analysis
- Customer quality, segmentation, and retention analysis
- Drug-safety data analysis
- Analyzing cross-selling data
- Sentiment analysis
Conclusion
Each of these big data tools brings unique advantages to your goal of storing large data efficiently, processing it swiftly, and providing analytics that can offer a new direction for growth to your business. However, these results are dependent on one parameter – choosing the right tools that fit your requirements, resources, and objectives.
With the right big data tools, you have the scope of creating something extraordinary and transforming your business for the better. On the flip side, choosing the wrong one is a recipe for making a mess.
Choose wisely to thrive in this ever-dynamic, tech-driven world.