
Big Data approaches in Pharmacovigilance: Using Big, Real-World Data to Create Decision-Relevant Evidence

The healthcare industry has experienced a watershed moment in its evolution for treatment, as more and more hospitals look towards big data methods to resolve issues. The principle behind such ideas has been to jump ahead from the uncertainties of relapses in patient health statistics. With the advent of newer and refined collection methods for disease parameters as well as population studies, one can see the positive impact of big data in formulating decisions in critical situations.
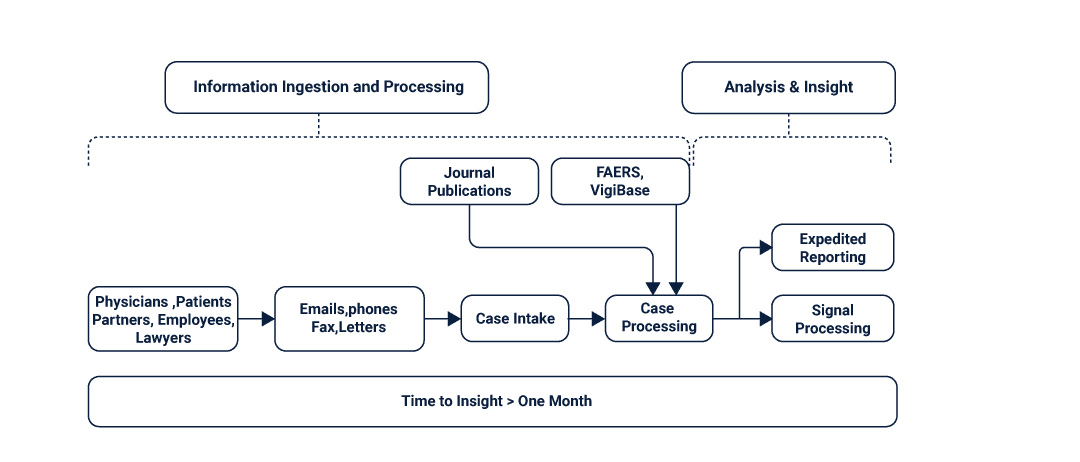
Pharmacovigilance is a branch of pharmacological studies that intends to minimize the effects and reactions of drug intake by studying consumption trends in sample populations. Due to the massive amounts of data-numeric and contextual, that is generated with each trial, and big data has become a favored tool for traversing through clinical repositories.
History Of Big Data In Healthcare
It was during the period of the, and the 60’s that computers evolved from their gigantic proportions to even more elaborate settings in research facilities. Computers such as the ENIVAC and UNIVAC were envisioned by Jon Von Neuman to be the staple used for calculations and advanced military projects. But the vision of big data being used as the tool for model development evolved with the birth of the modern computer. As machines became smaller and faster, Big data storage and collection methods became advanced, promising a new generation of problems to be tackled with greater precision.
The story of big data entering the realms of healthcare and pharmacovigilance begins with the advent of software like STATA being used by analysts. These were employed primarily for studying the onset and possibilities of diseases in patient batches. Tabular and comma-separated value generation helped capture what would be soon to become ‘real-world data’. This refers to the data that is generated from electronic records and the administrative history of patients. Both have their advantages and disadvantages when it comes to the longitudinal aspect of centricity and accuracy. Big data was able to generate sound and logical models to be used in researches for patients afflicted with conditions such as cancer, heart disease, and even minor afflictions.
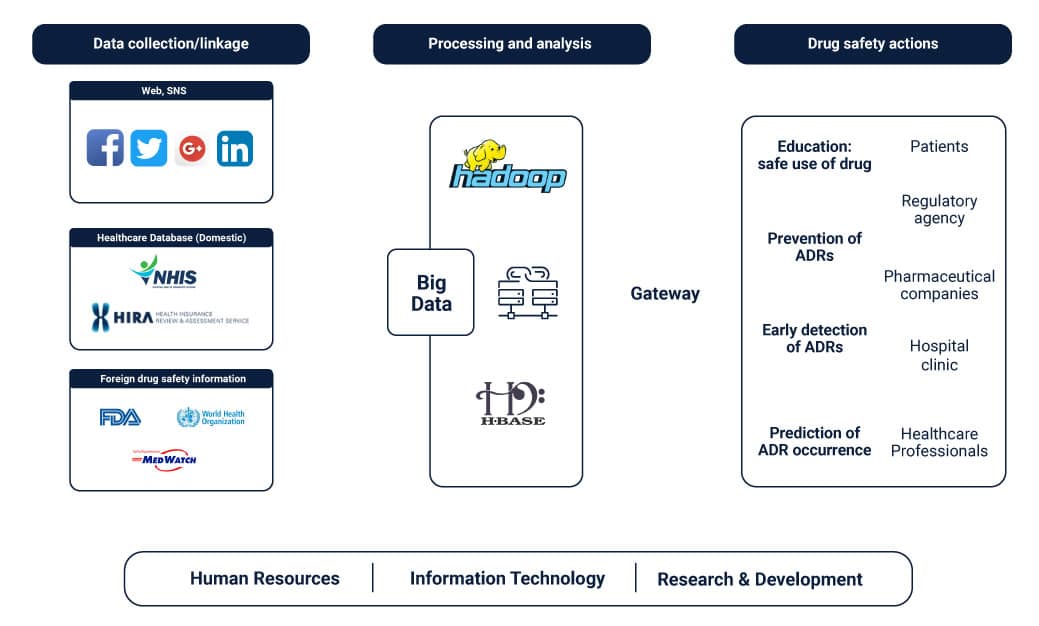
The models in such experiments sought first to collect and classify that which wasn’t known to health professionals at the time-what parameters influence the conditions and their estimation of relapsing in cured patients. As the models grew smarter, the objective spanned out to test cases and looked at finding ways to prevent the onset of conditions for patients through relevant preventive care and medicine. Big data engineering also caught the attention of researchers in the drug development industry. Here it was used to aid in the determination of new medicinal compounds for drug design including analgesics and antipyretics.
The Role Of Real-World Data
Published methods such as the Monte Carlo Method and convex optimization helped in paving the way for stable new compounds that made lives easier everywhere. But it wasn’t a simple journey to reach this point of the cycle. Real-world data has played a huge role in helping analysts derive new ways of looking at how diseases and patients interplay to a more homogenized framework of network models.
Real-world data, in simpler terms, is raw information that is obtained by assessments and analysis of patients in real-life settings. The focus here is to remove the uncertainty that black box models end up incorporating in decision making, by having crisp results to work on. Real-world data is hard to obtain and collect, given the multilateral nature in which the data is linked to health statistics such as blood pressure, ECG levels, lung capacity, and trauma. In the context of big data modeling for health centers, real-world big data is needed for creating a contextual picture of the patient without sacrificing smaller nuances.
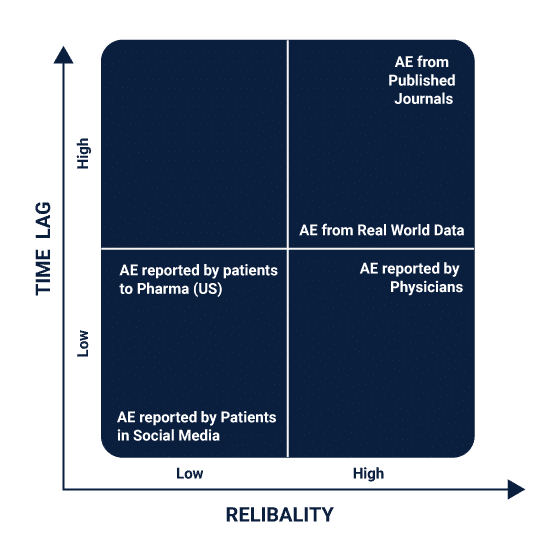
Real-world data can include anything that is generated from the patient’s records while admitted to the hospital and is treated to be the first resource when building predictive models. It can also be generated from registries and pharmaceutical trials that the patient is undergoing for treatment or clinical trial studies. A well-collected repository of real-world data helps in accumulating enough weight for real-world evidence.
Real-world evidence is to be considered for validating the big data models that are created to help confirm their usefulness. One of the key problems faced with any clinical study involving data is the rapid succession of junk values which can affect the weight of the real-world evidence. To perfectly paint this picture of the patient’s health, data must separate the junk values from the relevant ones. Tuning and cleaning methods are thus important to clean inconsistencies and incomplete records.
Real-world data is also used extensively for crafting deterministic models to measure the incidences of adverse drug reactions in patients. Using a system of risk assessment tools and
What Is Decision Relevant Evidence?
Picture the typical analyst environment. Swathes of data files and repositories littered across the servers with documentation of patients strewing all over the floor. It’s a fact seldom contested that big data is a long and arduous process that doesn’t just stop with creating accurate models. The objective behind any typical big data framework is to build a model that can stand the test of new records, regardless of variations and biases.
In the medical and health fields, such problems are magnified to large extents due to the disconnect between the parameters that the machines measure and what they tell analysts. For example, clinical trials where control subjects show certain drug effects over those that don’t could be quickly thought to be influenced by the drugs. Pitfalls and fallacies such as mistaking correlation for causation are common.
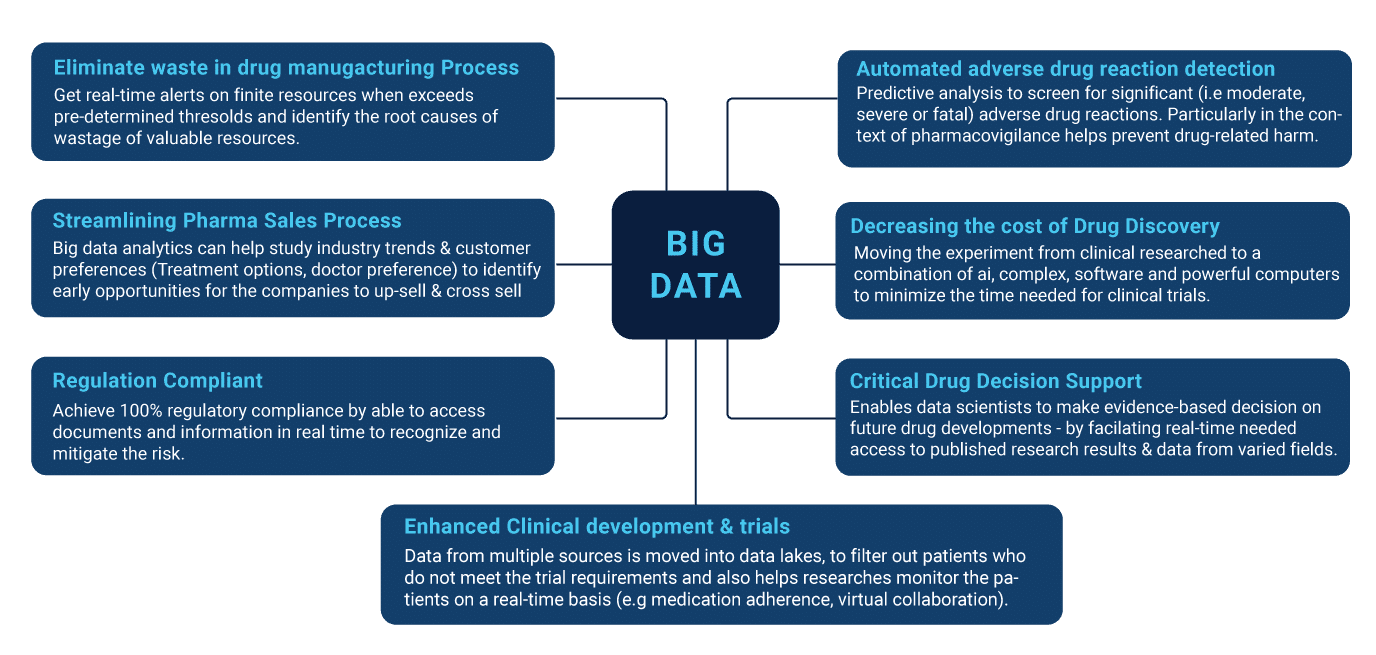
As such, data has to be meaningful and relevant to the study that is being conducted. To be meaningful, the evidence must be relevant and decision-focused. To obtain meaningful evidence, it is necessary that the quality of the data must be fit for the study. The data types of the parameters being measured must be appropriate and should match the outputs for which the studies pertain to. Take the example of a drug design experiment to test the effects of a new ibuprofen variant on people with allergies.
The test cases must include not just those that have a history of allergies but those who aren’t. This brings us to another important point- always employ metrics that matter. Continuing from the same example, if the research team was to use pharmacological metrics such as exposure alone, they wouldn’t yield meaningful results. Sound models are created when all factors-environmental, social, psychological and physical are incorporated. The challenge is to know which parameters are more important than others. Using big data feature engineering techniques, analysts can now pinpoint which metrics are more meaningful.
What Is Good Data In Healthcare?
Bad data leads to bad results. The standard ‘garbage in, garbage out’ methodology is well entrenched in medical sciences as well. To create good big data models that produce evidence for assured decisions is possible, given that a particular number of conditions and requirements are met. To begin with, there must be meaningful evidence for the veracity being collected. The evidence must be validated when the model is being checked and also expedited to prevent errors from entering the models. A fourth condition concerns the transparency of the evidence that is being produced.
Clinical trials and studies must show that experimentations were conducted in impartial and unbiased environments with no influences of external forces. Often, the results obtained from a study may not hold well entirely in real-world settings due to the controlled nature of the testing environment. Many times, teams can even conflate the strength of specific metrics over others for more ulterior reasons.
For healthcare data, the importance lies in four elements- temporality, baseline status (confounders), exposure state and outcome. These relate to the transient nature of how specific pharmacological effects can differ over large sample sizes. A baseline status is thus created to help standardize the results to improve interpretation. To measure how the results would translate to new studies in the future with similar sample sizes, the outcome is baselined against the exposure state.
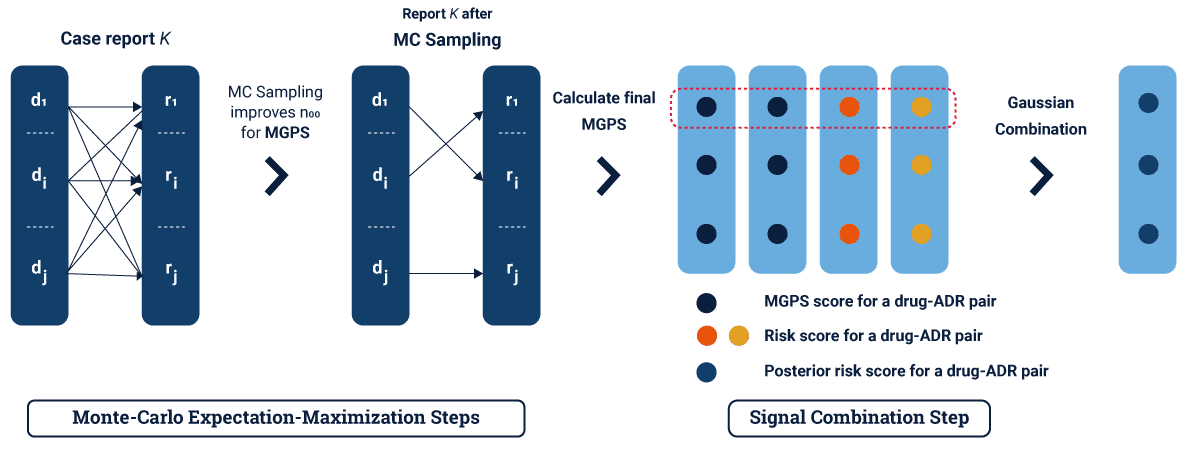
To obtain useful data for pharmacological studies and pharmacovigilance at a glance, analysts prescribe a battery of intrinsic and external characteristic studies. Essential study characteristics look at the variations and errors that can arise from within the data such as biases and preconceived assumptions about certain effects. These can include:-
- Internal validity (bias)
- External validity (generalizability, transportability)
- Precision
- Heterogeneity in risk or benefit (personalized evidence)
- Ethical consideration (equipoise)
External study characteristics can influence the accuracy and quality of the data by changing the conditions of the studies, such as time and capital. Others can include:-
- Timeliness (rapidly changing technology, policy needs)
- Logistical constraints (study size, complexity, cost)
- Data availability, quality, completeness
Getting good data begins by eliminating these factors and keeping a close vigilance on the effects that matter most. Trials for new variations of painkillers, for example, maybe limited due to the extreme needs of the sample populations required for the study to yield meaningful results. Test subjects may be limited by gender, age groups, and history of illnesses. A similar yet far more complex challenge arises for specialty drugs and chemicals. Drugs that are designed for a separate class of consumers and patients can be tougher to study due to the extrinsic reasons suggested above.
Drugs such as alcohol patches and immunosuppressants would produce verifiable results with those that have been diagnosed with certain conditions. As a result, big data modeling has to rely heavily on such realistic examples.
How Does It Work?
Like with any standard big data project, analysts first dig into data from repositories or administrative results. Trials and studies that take place concurrently with the analysis would get to the verification and visualization steps once they are completed. The next step in the process is to clean the data by standardizing and normalizing input variables to a common dimension. The data is then fed to a model maker that tests out the accuracy for different methods such as random forests, logistic regression, and multivariate regression. Any non-numeric variables are converted into numeric types by replacing them with binary classes.
For real-time analysis of drug effects, the data is interlinked from the sensors/systems to an API and finally processed. Result of the data is visualized and published using dashboard makers. Modern age pharmacological vigilance, however, goes beyond these steps and aims at producing preventive models that can save patients before the onset of unwanted reactions. In such specific cases, the models track for cues and symptoms that are linked to the early stages of a disease, condition or reaction.
Looking back at the allergy case study, clinical trials with a history of being afflicted with the condition may only produce a verifiable reaction under certain conditions. As a result, monitoring the specifics of all changes-no matter how minute, becomes a challenge for large scale clinical case studies. After all the steps are conducted and there is are deployed models with good figures running about, comes the crucial step of choosing which models to keep
Promising models will be selected over those that fail to show adaptability and verification over a given confidence level. For a z distribution dataset where the output measured is balanced well, this could mean anywhere above 96%. Clinical trials, however, can take this up to a 99% confidence level to ensure that there are no failures with the models when tested in real life. A more refined methodology uses several verification steps in the middle of the analysis stages so that it can be determined which of the models should be continued and which should be discarded.
Most pharmacological studies thus draw a sampled chart of all possible cases using Monte Carlo simulations. Those that give away the best proof for verification are kept and continued. Models that are to be discarded are tested for any subgroup effects and disseminated among pre-processing teams to check for inconsistencies. Finally, if the models show any chance of improvement, they are further analyzed for future studies and drafted.
How To Get Transparent Evidence?
Always aim for data that would fit with reproducible research. If it cannot be used in any other context for futures studies, the evidence may lack cohesion. As a result, make sure that the results are transparent and ensure that it can be audited if required. Veracity is one of the 4Vs of big data that should be put to the test whenever there may be questions or doubts.
Another important element to remember is trust and validity. New and fresh clinical trials may seem attractive due to their relevance but aim to use trusted sources. This is where an important concept- standardization, comes into play. Data has to match the standards that have been set by the team and never be doctored to fit certain hypotheses. This also assists in making sure that the models are true and close to the data that they are based on. Transparency is also improved by countering the confounding effects of unexpected results in clinical trials.
False positives and false negatives are such examples that are sure to arise in any pharmacological case study. Suppose that a person who has been administered with a Type A drug shows all the symptoms for a reaction but doesn’t experience any- this is a case of confusion where context is necessary. It can also occur due to mistranslations in specific physical effects which may not be stored properly.
Imagine if a test subject showed a reaction that isn’t a part of the expected list of effects, it may be missed or even misinterpreted by researchers. This can make all the difference in phasing out a new drug on the market or launching it and causing immense reactions.
And remember, not all variables-even the minutest ones, can be covered properly with the most foolproof model. In simpler terms, avoiding context can cause teams to miss certain known unknowns in their research. Confounding can be eliminated through a handful of methods including:-
- Restriction
- Matching analysis
- Standardization
- Stratification
- Imputation
- Proxy analysis
- Sensitivity analysis.
- Propensity scores
- Marginal Structural Models
Conclusion
Decision relevant evidence if factored the way it should be can be a powerful weapon in reducing the madness of drug design and pharmacovigilance. In an industry where competition for the fastest and the cheapest drug is always prominent, researchers are prompted to stick to the big guns for better results. But again, such data is only worth the trouble if it maintains all integrities of transparency and trust.
Pharmacological studies have much to thank the revolution of Big data that has swept the industries clean. Where the tide turns next is unclear, but as long as it is transparent and working information available, big data modeling will be a preferred tool for the countless studies that shape the drug market.
Must Reads:[wcp-carousel id=”10003″]